LDA Téma Modelování: Vysvětlení
Pozadí
Téma modelování je proces identifikace témat v sadě dokumentů. To může být užitečné pro vyhledávače, automatizaci zákaznických služeb a jakýkoli jiný případ, kdy je důležité znát témata dokumentů. Existuje několik způsobů, jak to udělat, ale tady vysvětlím jeden: Latentní Dirichletova alokace (LDA).
algoritmus
LDA je forma bez dozoru, která nahlíží na dokumenty jako na pytle slov (tj. na pořadí nezáleží). LDA pracuje tak, že nejprve vytvoří klíčový předpoklad: způsob, jakým byl dokument vygenerován, byl výběrem sady témat a poté pro každé téma výběrem sady slov. Nyní se možná ptáte “ ok, tak jak to najde témata?“No odpověď je jednoduchá: to reverzní inženýři tento proces. Chcete-li to provést, provede následující pro každý dokument m:
- Předpokládat, že jsou k témat napříč všemi dokumenty
- Distribuovat tyto k tématům napříč dokument m (tato distribuce je známá jako α a mohou být symetrické nebo asymetrické, více o tom později) přiřazením každé slovo téma.
- pro každé slovo w v dokumentu m předpokládejme, že jeho téma je špatné, ale každému druhému slovu je přiřazeno správné téma.
- pravděpodobnostně přiřaďte word w tématu založenému na dvou věcech:
– jaká témata jsou v dokumentu m
– jak se mnohokrát slovo w má přiděleno konkrétní téma napříč všemi dokumenty (toto rozdělení se nazývá β, více o tom později) - tento postup Opakujte několikrát pro každý dokument a máte hotovo!
Model
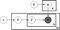
Výše uvedené je to, co je známé jako desky schéma LDA modelu, kde:
α je za dokument téma rozdělení,
β je za-téma slovo distribuce,
θ je téma distribuce pro dokument m,
φ je slovo distribuce pro téma k,
z je téma pro n-tého slova v dokumentu m, a
w je zvláštní slovo,
Ladění Modelu
V desce diagramu modelu výše, můžete vidět, že w je zobrazena šedě. Je to proto, že je to jediná pozorovatelná proměnná v systému, zatímco ostatní jsou latentní. Kvůli tomu, vyladit model existuje několik věcí, se kterými si můžete pohrávat, a níže se zaměřuji na dvě.
α je matice, kde každý řádek je dokument a každý sloupec představuje téma. Hodnota v řádku i a sloupci j představuje, jak pravděpodobné dokument, který obsahuje téma j. Symetrické rozdělení by znamenalo, že každé téma je rovnoměrně rozložena v celém dokumentu, zatímco asymetrické distribuce laskavosti některých témat před jinými. To ovlivňuje výchozí bod modelu a lze jej použít, když máte hrubou představu o tom, jak jsou témata distribuována, aby se zlepšily výsledky.
β je matice, kde každý řádek představuje téma a každý sloupec představuje slovo. Hodnota v řádku i a sloupci j představuje pravděpodobnost, že toto téma I obsahuje slovo j. obvykle je každé slovo rovnoměrně rozloženo v celém tématu tak, že žádné téma není zaujaté vůči určitým slovům. To však lze využít k zaujatosti určitých témat, aby upřednostňovala určitá slova. Například pokud víte, že máte téma o Apple produkty, to může být užitečné, aby zaujatost slova jako „iphone“ a „ipad“ pro jedno z témat, s cílem, aby se zasadila model k zjištění, že určité téma.
závěr
tento článek nemá být plnohodnotným tutoriálem LDA, ale spíše poskytnout přehled o tom, jak fungují modely LDA a jak je používat. Existuje mnoho implementací, jako je Gensim, které se snadno používají a jsou velmi účinné. Dobrý návod k použití knihovny Gensim pro modelování LDA najdete zde.
máte nějaké myšlenky nebo najít něco, co mi chybělo? Dej mi vědět!
šťastné modelování témat!
Leave a Reply