OCR Python, OpenCV a PyTesseract

Optické Rozpoznávání Znaků (OCR) je převod obrázků napsaný, ručně psaný nebo tištěný text do stroje-kódovaný text, ať už z naskenovaného dokumentu, fotografie, dokument, fotografii z místa nehody (billboardy v krajině, foto) nebo text překrývá obrázek (titulky na televizní vysílání).
OCR sestává obecně z dílčích procesů, které mají provádět co nejpřesněji.

- Pre-processing
- Text detekce
- rozpoznání Textu
- Post processing
sub-procesy mohou samozřejmě lišit v závislosti na použití-případ, ale tyto jsou obecně potřebné kroky provádět optické rozpoznávání znaků.
Tesseract OCR :
Tesseract je open source rozpoznávání textu (OCR) motor, k dispozici pod licencí Apache 2.0. Může být použit přímo, nebo (pro programátory) pomocí API extrahovat tištěný text z obrázků. Podporuje širokou škálu jazyků. Tesseract nemá vestavěné GUI, ale na stránce 3rdParty je k dispozici několik. Tesseract je kompatibilní s mnoha programovacími jazyky a frameworky prostřednictvím obalů, které najdete zde. Může být použit s existující analýzou rozvržení k rozpoznání textu ve velkém dokumentu, nebo může být použit ve spojení s externím detektorem textu k rozpoznání textu z obrázku jednoho textového řádku.
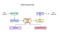
Tesseract 4.00 obsahuje nové neuronové sítě subsystém nakonfigurován jako textový on-line rozpoznávače. To má svůj původ v ocropus ‚ Python-based lstm implementace, ale byl přepracován pro Tesseract v C++. Neuronové sítě systém Tesseract pre-data TensorFlow ale je kompatibilní s tím, jak tam je síť, popis jazyce nazývají Proměnné Graf Specifikaci Jazyka (VGSL), který je také k dispozici pro TensorFlow.
k rozpoznání obrazu obsahujícího jeden znak obvykle používáme konvoluční neuronovou síť (CNN). Text libovolné délky je posloupnost znaků, a tyto problémy jsou řešeny pomocí RNNs a LSTM je populární forma RNN. Přečtěte si tento příspěvek a dozvíte se více o LSTM.
Tesseract vyvinut z OCRopus modelu v Pythonu, který byl vidličkou LSMT v C++, nazvaný CLSTM. CLSTM je implementace modelu rekurentní neuronové sítě LSTM v jazyce C++.
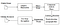
Tesseract byla snaha na čištění kódu a přidání nové LSTM model. Vstupní obraz je zpracován v boxech (obdélníku) řádek po řádku, který se přivádí do modelu LSTM a dává výstup. Na obrázku níže si můžeme představit, jak to funguje.

Instalace Tesseract
Instalace tesseract na Windows je snadné s předkompilované binárky nalézt zde. Nezapomeňte upravit proměnnou prostředí „path“ a přidat cestu Tesseract. Pro instalaci systému Linux nebo Mac je nainstalován s několika příkazy.
ve výchozím nastavení Tesseract očekává stránku textu, když segmentuje obrázek. Pokud právě hledáte OCR malou oblast, zkuste jiný režim segmentace pomocí argumentu-psm. K dispozici je 14 režimů, které najdete zde. Ve výchozím nastavení Tesseract plně automatizuje segmentaci stránek, ale neprovádí orientaci a detekci skriptů. Chcete-li zadat parametr, zadejte následující:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
existuje také další důležitý argument, OCR engine mode (oem). Tesseract 4 má dva motory OCR-starší motor Tesseract a motor LSTM. Existují čtyři režimy provozu vybrané pomocí volby-oem.
0. Pouze starší motor.
1. Neuronové sítě lstm pouze motor.
2. Legacy + lstm motory.
3. Výchozí, na základě toho, co je k dispozici.
OCR s Pytesseractem a OpenCV:
Pytesseract je obal pro motor Tesseract-OCR. To je také užitečné jako stand-alone vyvolání skriptu tesseract, jak to může číst všechny typy obrázků podporované Polštář a Leptonica zobrazovací knihovny, včetně jpeg, png, gif, bmp, tiff, a další. Více informací o Python přístupu čtěte zde.
Předzpracování pro Tesseract :
Musíme se ujistit, že obraz je vhodně pre-zpracované. pro zajištění určité úrovně přesnosti.
To zahrnuje změnu měřítka, binarizaci, odstranění šumu, deskewing atd.
Chcete-li zpracovat obrázek pro OCR, použijte některou z následujících funkcí Pythonu nebo postupujte podle dokumentace OpenCV.
Our input is this image :

Here’s what we get :

Getting boxes around text :
informace o ohraničujícím poli můžeme určit pomocí PyTesseradt pomocí následujícího kódu.
níže uvedený skript vám vymezovacího rámečku informace pro každý znak detekován při OCR tesseract.
Pokud chcete, krabice kolem slova místo znaků, funkce image_to_data přijde vhod. Můžete použít funkci image_to_data s typem výstupu určeným pomocí pytesseract Output.
použijeme ukázkový obrázek příjmu níže jako vstup k vyzkoušení Tesseractu .

Zde je kód :
výstup je slovník s následujícího klíče :

Pomocí tohoto slovníku, můžeme si každé slovo, které zjištěné, jejich ohraničení informace, text v nich, a důvěru skóre pro každého.
můžete vytvořit obrázek krabice pomocí kódu níže :
výstup:

Jak můžeme vidět Tesseract není schopen detekovat všechny textové boxy s jistotou, nekvalitní skeny a malé fonty mohou produkovat špatnou kvalitu OCR text detekce. Rovněž nebylo provedeno žádné předzpracování ke zlepšení kvality obrazu.
odpovídající text šablony (detekovat pouze číslice ):
Vezměme si příklad pokusu zjistit, kde je v obrázku pouze řetězec číslic. Zde bude naší šablonou vzor regulárního výrazu, který porovnáme s našimi výsledky OCR, abychom našli příslušná ohraničující políčka. K tomu použijeme modul regex a funkci image_to_data.

Page segmentace režimy :
existuje několik způsobů, jak lze stránku textu analyzovat. Rozhraní Tesseract api poskytuje několik režimů segmentace stránek, pokud chcete spustit OCR pouze na malém regionu nebo v různých orientacích atd.
zde je seznam podporovaných režimů segmentace stránek pomocí tesseract:
0. Pouze orientace a detekce skriptů (OSD).
1. Automatická segmentace stránek pomocí OSD.
2. Automatická segmentace stránek, ale bez OSD nebo OCR.
3. Plně automatická segmentace stránek, ale bez OSD. (Výchozí)
4. Předpokládejme jeden sloupec textu proměnných velikostí.
5. Předpokládejme jeden jednotný blok vertikálně zarovnaného textu.
6. Předpokládejme jeden jednotný blok textu.
7. Zacházejte s obrázkem jako s jedním textovým řádkem.
8. Zacházejte s obrázkem jako s jediným slovem.
9. Zacházejte s obrázkem jako s jedním slovem v kruhu.
10. Zacházejte s obrázkem jako s jedním znakem.
11. Řídký text. Najděte co nejvíce textu v žádném konkrétním pořadí.
12. Řídký text s OSD.
13. Surová linie. Zacházejte s obrázkem jako s jedním textovým řádkem a obcházejte hacky, které jsou specifické pro Tesseract.
Chcete-li změnit režim segmentace stránky, změňte argument --psm v řetězci vlastní konfigurace na některý z výše uvedených kódů režimu.
Detekovat pouze číslice pomocí konfigurace :
můžete rozpoznat pouze číslice změnou config následující :
což dává následující výstup.

Jak můžete vidět výstup není totéž pomocí regulárního výrazu .
Whitelisting / Blacklisting characters:
řekněte, že chcete detekovat pouze určité znaky z daného obrázku a zbytek ignorovat. Můžete zadat whitelist znaků (zde jsme použili všechna malá písmena pouze od a do z) pomocí následující konfigurace.
a dává nám tento výstup :

černé listiny, dopisy :
Pokud jste si jisti, že některé znaky nebo výrazy, určitě nebude zase až v textu (OCR vrátí chybný text místo na černé listině znaky jinak), můžete blacklist tyto znaky pomocí následujících config.
výstup :
Více jazycích, text :
určete jazyk, který potřebujete OCR výstupu, použijte -l LANG argument v config, kde LANG je 3 písmenný kód pro to, co jazyk, který chcete použít.
můžete pracovat s více jazyky změnou parametr LANG jako takový :
NB : Jazyk zadaný nejprve parametru -l je primárním jazykem.

A dostanete následující výstup :

Bohužel tesseract nemá funkci pro detekci jazyka textu v obrázku automaticky. Alternativní řešení poskytuje jiný modul python s názvem langdetect, který lze nainstalovat pomocí pip pro více informací zkontrolujte tento odkaz.
Tento modul opět nedetekuje jazyk textu pomocí obrázku, ale potřebuje řetězec pro detekci jazyka. Nejlepší způsob, jak to udělat, je tím, že nejprve pomocí tesseract se dostat OCR text v jakémkoli jazyce můžete cítit, pomocí langdetect najít to, co jazyky jsou zahrnuty v OCR text a potom spusťte rozpoznávání OCR znovu s jazyky nalezen.
Řekněme, že máme text, o kterém jsme si mysleli, že je v angličtině a portugalštině.
POZNÁMKA: Tesseract provádí špatně, když v obrázku s více jazyky, jazyky zadané v konfiguračním jsou špatné nebo nejsou uvedeny vůbec. To může také uvést modul langdetect v omyl.
Tesseract omezení:
Tesseract OCR je poměrně silný, ale má určitá omezení.
- OCR není tak přesný jako některá dostupná komerční řešení .
- nedělá dobře s obrázky ovlivněny artefakty včetně částečné okluze, zkreslené perspektivy a komplexní pozadí.
- není schopen rozpoznat rukopis.
- může najít blábol a nahlásit to jako výstup OCR.
- pokud dokument obsahuje jazyky mimo jazyky uvedené v argumentech-l LANG, výsledky mohou být špatné.
- není vždy dobré analyzovat přirozené pořadí čtení dokumentů. Například může selhat rozpoznat, že dokument obsahuje dva sloupce, a může se pokusit připojit text mezi sloupci.
- nekvalitní skenování může způsobit nekvalitní OCR.
- nevystavuje informace o tom, do jaké rodiny písem patří text.
závěr:
Tesseract je ideální pro skenování čistých dokumentů a přichází s velmi vysokou přesností a variabilitou písma, protože jeho výcvik byl komplexní.
nejnovější verze Tesseract 4.0 podporuje OCR založené na hlubokém učení, které je výrazně přesnější. Samotný motor OCR je postaven na síti s dlouhou krátkodobou pamětí (LSTM), což je zvláštní typ rekurentní neuronové sítě (RNN).
Leave a Reply