LDA-Themenmodellierung: Eine Erklärung
Hintergrund
Bei der Themenmodellierung werden Themen in einer Reihe von Dokumenten identifiziert. Dies kann für Suchmaschinen, die Automatisierung des Kundendienstes und alle anderen Fälle nützlich sein, in denen es wichtig ist, die Themen von Dokumenten zu kennen. Es gibt mehrere Methoden, dies zu tun, aber hier werde ich eine erklären: Latente Dirichlet-Allokation (LDA).
Der Algorithmus
LDA ist eine Form des unbeaufsichtigten Lernens, die Dokumente als Wortsäcke betrachtet (dh die Reihenfolge spielt keine Rolle). LDA arbeitet, indem es zuerst eine Schlüsselannahme macht: Die Art und Weise, wie ein Dokument generiert wurde, bestand darin, eine Reihe von Themen auszuwählen und dann für jedes Thema eine Reihe von Wörtern auszuwählen. Jetzt fragen Sie vielleicht „Ok, wie findet es Themen?“ Nun, die Antwort ist einfach: es Reverse Engineering diesen Prozess. Dazu führt es für jedes Dokument Folgendes aus::
- Angenommen, es gibt k Themen in allen Dokumenten
- Verteilen Sie diese k Themen auf Dokument m (diese Verteilung ist als α bekannt und kann symmetrisch oder asymmetrisch sein, dazu später mehr), indem Sie jedem Wort ein Thema zuweisen.
- Nehmen Sie für jedes Wort w in Dokument m an, dass sein Thema falsch ist, aber jedem anderen Wort das richtige Thema zugewiesen ist.
- Probabilistisch zuweisen Wort w ein Thema auf der Grundlage von zwei Dingen:
– Welche Themen befinden sich in Dokument m
– Wie oft Word w in allen Dokumenten ein bestimmtes Thema zugewiesen wurde (diese Verteilung heißt β, dazu später mehr) - Wiederholen Sie diesen Vorgang mehrmals für jedes Dokument und fertig!
Das Modell
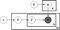
Oben ist ein so genanntes Plattendiagramm eines LDA-Modells, in dem:
α ist die Pro-Dokument-Themenverteilung,
β ist die Pro-Thema-Wortverteilung,
θ ist die Themenverteilung für Dokument m,
φ ist die Wortverteilung für Thema k,
z ist das Thema für das n-te Wort in Dokument m und
w ist das spezifische Wort
Optimieren des Modells
Im obigen Plattenmodelldiagramm können Sie sehen, dass w ausgegraut ist. Dies liegt daran, dass es die einzige beobachtbare Variable im System ist, während die anderen latent sind. Aus diesem Grund gibt es zum Optimieren des Modells einige Dinge, mit denen Sie sich anlegen können, und unten konzentriere ich mich auf zwei.
α ist eine Matrix, in der jede Zeile ein Dokument und jede Spalte ein Thema darstellt. Eine symmetrische Verteilung würde bedeuten, dass jedes Thema gleichmäßig im gesamten Dokument verteilt ist, während eine asymmetrische Verteilung bestimmte Themen gegenüber anderen bevorzugt. Dies wirkt sich auf den Ausgangspunkt des Modells aus und kann verwendet werden, wenn Sie eine grobe Vorstellung davon haben, wie die Themen verteilt sind, um die Ergebnisse zu verbessern.β ist eine Matrix, in der jede Zeile ein Thema und jede Spalte ein Wort darstellt. Ein Wert in Zeile i und Spalte j gibt an, wie wahrscheinlich es ist, dass das Thema i das Wort j enthält. Normalerweise ist jedes Wort gleichmäßig über das Thema verteilt, sodass kein Thema auf bestimmte Wörter ausgerichtet ist. Dies kann jedoch ausgenutzt werden, um bestimmte Themen zu verzerren, um bestimmte Wörter zu bevorzugen. Wenn Sie beispielsweise wissen, dass Sie ein Thema zu Apple-Produkten haben, kann es hilfreich sein, Wörter wie „iPhone“ und „ipad“ für eines der Themen zu verwenden, um das Modell dazu zu bringen, dieses bestimmte Thema zu finden.
Fazit
Dieser Artikel soll kein vollständiges LDA-Tutorial sein, sondern einen Überblick darüber geben, wie LDA-Modelle funktionieren und wie sie verwendet werden. Es gibt viele Implementierungen wie Gensim, die einfach zu bedienen und sehr effektiv sind. Ein gutes Tutorial zur Verwendung der Gensim-Bibliothek für die LDA-Modellierung finden Sie hier.
Haben Sie irgendwelche Gedanken oder finden Sie etwas, das ich verpasst habe? Gib mir Bescheid!
Viel Spaß beim Modellieren!
Leave a Reply