OCR mit Python, OpenCV und PyTesseract

Optische Zeichenerkennung (OCR) ist die Umwandlung von Bildern von getipptem, handgeschriebenem oder gedrucktem Text in maschinencodierten Text, sei es aus einem gescannten Dokument, einem Foto eines Dokuments, einem Foto aus einer Szene (Werbetafeln in einem Landschaftsfoto) oder aus einem Text, der einem Bild überlagert ist (Untertitel in einer Fernsehsendung).
OCR besteht im Allgemeinen aus Teilprozessen, die so genau wie möglich ausgeführt werden sollen.

- Vorverarbeitung
- Texterkennung
- Texterkennung
- Nachbearbeitung
Die Teilprozesse können natürlich je nach Anwendungsfall variieren, aber dies sind im Allgemeinen die Schritte, die zur Durchführung der optischen Zeichenerkennung erforderlich sind.
Tesseract OCR :
Tesseract ist eine Open-Source-Texterkennungs-Engine (OCR), die unter der Apache 2.0-Lizenz verfügbar ist. Es kann direkt oder (für Programmierer) mit einer API verwendet werden, um gedruckten Text aus Bildern zu extrahieren. Es unterstützt eine Vielzahl von Sprachen. Tesseract hat keine integrierte GUI, aber es gibt mehrere von der 3rdParty-Seite. Tesseract ist mit vielen Programmiersprachen und Frameworks durch Wrapper kompatibel, die hier zu finden sind. Es kann mit der vorhandenen Layoutanalyse verwendet werden, um Text in einem großen Dokument zu erkennen, oder es kann in Verbindung mit einem externen Textdetektor verwendet werden, um Text aus einem Bild einer einzelnen Textzeile zu erkennen.
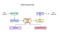
Tesseract 4.00 enthält ein neues neuronales Netzwerk-Subsystem, das als Textzeilenerkennung konfiguriert ist. Es hat seinen Ursprung in der Python-basierten LSTM-Implementierung von OCRopus, wurde jedoch für Tesseract in C ++ neu gestaltet. Das neuronale Netzwerksystem in Tesseract datiert TensorFlow vor, ist jedoch damit kompatibel, da es eine Netzwerkbeschreibungssprache namens Variable Graph Specification Language (VGSL) gibt, die auch für TensorFlow verfügbar ist.
Um ein Bild zu erkennen, das ein einzelnes Zeichen enthält, verwenden wir normalerweise ein Convolutional Neural Network (CNN). Text beliebiger Länge ist eine Folge von Zeichen, und solche Probleme werden mit RNNs gelöst, und LSTM ist eine beliebte Form von RNN. Lesen Sie diesen Beitrag, um mehr über LSTM zu erfahren.
Tesseract wurde aus dem OCRopus-Modell in Python entwickelt, das eine Abzweigung eines LSMT in C ++ namens CLSTM war. CLSTM ist eine Implementierung des LSTM-Modells für wiederkehrende neuronale Netze in C ++.
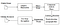
Tesseract war ein Versuch, Code zu bereinigen und ein neues LSTM-Modell hinzuzufügen. Das Eingabebild wird zeilenweise in Kästchen (Rechteck) verarbeitet, die in das LSTM-Modell eingespeist und ausgegeben werden. Im Bild unten können wir visualisieren, wie es funktioniert.

Tesseract installieren
Die Installation von Tesseract unter Windows ist mit den hier vorkompilierten Binärdateien einfach. Vergessen Sie nicht, die Umgebungsvariable „path“ zu bearbeiten und den Tesseract-Pfad hinzuzufügen. Für die Linux- oder Mac-Installation wird es mit wenigen Befehlen installiert.
Standardmäßig erwartet Tesseract eine Textseite, wenn es ein Bild segmentiert. Wenn Sie nur eine kleine Region OCR möchten, versuchen Sie es mit einem anderen Segmentierungsmodus mit dem Argument — psm. Es stehen 14 Modi zur Verfügung, die hier gefunden werden können. Standardmäßig automatisiert Tesseract die Seitensegmentierung vollständig, führt jedoch keine Ausrichtung und Skripterkennung durch. Um den Parameter anzugeben, geben Sie Folgendes ein:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
Es gibt noch ein weiteres wichtiges Argument, den OCR Engine Mode (oem). Tesseract 4 verfügt über zwei OCR-Engines – Legacy Tesseract Engine und LSTM Engine. Es gibt vier Betriebsmodi, die mit der Option — oem ausgewählt werden.
0. Nur Legacy-Engine.
1. Neuronale Netze LSTM Motor nur.
2. Legacy + LSTM-Motoren.
3. Standard, basierend auf dem, was verfügbar ist.
OCR mit Pytesseract und OpenCV :
Pytesseract ist ein Wrapper für die Tesseract-OCR-Engine. Es ist auch als eigenständiges Aufrufskript für tesseract nützlich, da es alle von den Pillow- und Leptonica-Imaging-Bibliotheken unterstützten Bildtypen lesen kann, einschließlich JPEG, png, gif, bmp, tiff und andere. Weitere Informationen zum Python-Ansatz finden Sie hier.
Vorverarbeitung für Tesseract :
Wir müssen sicherstellen, dass das Bild entsprechend vorverarbeitet ist. um ein gewisses Maß an Genauigkeit zu gewährleisten.
Dazu gehören Neuskalierung, Binarisierung, Rauschunterdrückung, Deskewing usw.
Um Bilder für OCR vorzuverarbeiten, verwenden Sie eine der folgenden Python-Funktionen oder folgen Sie der OpenCV-Dokumentation.
Our input is this image :

Here’s what we get :

Getting boxes around text :
Wir können die Bounding-Box-Informationen mit PyTesseradt mit dem folgenden Code bestimmen.
Das folgende Skript gibt Ihnen Bounding-Box-Informationen für jedes Zeichen, das von tesseract während der OCR erkannt wird.
Wenn Sie Felder um Wörter anstelle von Zeichen möchten, ist die Funktion image_to_data nützlich. Sie können die Funktion image_to_data mit dem mit pytesseract Output angegebenen Ausgabetyp pytesseract Output .
Wir werden das Beispielbelegbild unten als Eingabe verwenden, um tesseract zu testen.

Hier ist der Code:
Die Ausgabe ist ein Wörterbuch mit den folgenden Schlüsseln:
Mit diesem Wörterbuch können wir jedes erkannte Wort, seine Begrenzungsrahmeninformationen, den darin enthaltenen Text und die Konfidenzwerte für jedes Wort abrufen.
Sie können die Felder mit dem folgenden Code zeichnen:
Die Ausgabe:

Wie wir sehen können, ist Tesseract nicht in der Lage, alle Textfelder sicher zu erkennen. Es wurde auch keine Vorverarbeitung durchgeführt, um die Qualität des Bildes zu verbessern.
Übereinstimmung der Textvorlage (nur Ziffern erkennen):
Versuchen Sie beispielsweise herauszufinden, wo sich eine Zeichenfolge mit nur Ziffern in einem Bild befindet. Hier ist unsere Vorlage ein Muster für reguläre Ausdrücke, das wir mit unseren OCR-Ergebnissen abgleichen, um die entsprechenden Begrenzungsrahmen zu finden. Dazu verwenden wir das regex Modul und die image_to_data Funktion.

Seitensegmentierungsmodi :
Es gibt mehrere Möglichkeiten, eine Textseite zu analysieren. Die Tesseract-API bietet mehrere Seitensegmentierungsmodi, wenn Sie OCR nur für einen kleinen Bereich oder in verschiedenen Ausrichtungen usw. ausführen möchten.
Hier ist eine Liste der unterstützten Seitensegmentierungsmodi von tesseract :
0. Nur Orientierungs- und Skripterkennung (OSD).
1. Automatische Seitensegmentierung mit OSD.
2. Automatische Seitensegmentierung, aber kein OSD oder OCR.
3. Vollautomatische Seitensegmentierung, aber kein OSD. (Standard)
4. Angenommen, eine einzelne Textspalte variabler Größe.
5. Angenommen, ein einzelner einheitlicher Block vertikal ausgerichteter Text.
6. Nehmen wir einen einzigen einheitlichen Textblock an.
7. Behandeln Sie das Bild als einzelne Textzeile.
8. Behandeln Sie das Bild als ein einzelnes Wort.
9. Behandeln Sie das Bild als ein einzelnes Wort in einem Kreis.
10. Behandeln Sie das Bild als einzelnes Zeichen.
11. Spärlicher Text. Finden Sie so viel Text wie möglich in keiner bestimmten Reihenfolge.
12. Spärlicher Text mit OSD.
13. Rohe Linie. Behandeln Sie das Bild als einzelne Textzeile und umgehen Sie Hacks, die Tesseract-spezifisch sind.
Um Ihren Seitensegmentierungsmodus zu ändern, ändern Sie das Argument --psm in Ihrer benutzerdefinierten Konfigurationszeichenfolge in einen der oben genannten Moduscodes.
Nur Ziffern anhand der Konfiguration erkennen:
Sie können nur Ziffern erkennen, indem Sie die Konfiguration wie folgt ändern:
was die folgende Ausgabe ergibt.

Wie Sie sehen können, ist die Ausgabe nicht die dasselbe mit Regex.
Whitelisting/Blacklisting von Zeichen :
Angenommen, Sie möchten nur bestimmte Zeichen aus dem angegebenen Bild erkennen und den Rest ignorieren. Sie können Ihre Whitelist von Zeichen angeben (hier haben wir nur alle Kleinbuchstaben von a bis z verwendet), indem Sie die folgende Konfiguration verwenden.
Und es gibt uns diese Ausgabe :

Buchstaben auf die schwarze Liste setzen:
Wenn Sie sicher sind, dass einige Zeichen oder Ausdrücke definitiv nicht in Ihrem Text auftauchen (die OCR gibt ansonsten falschen Text anstelle von Zeichen auf der schwarzen Liste zurück), können Sie diese Zeichen mithilfe der folgenden Konfiguration auf die schwarze Liste setzen.
Ausgabe :
Text in mehreren Sprachen :
Um die Sprache anzugeben, in der Sie Ihre OCR-Ausgabe benötigen, verwenden Sie das Argument -l LANG in der Konfiguration, wobei LANG der 3-Buchstaben-Code für die Sprache ist, die Sie verwenden möchten.
Sie können mit mehreren Sprachen arbeiten, indem Sie den Parameter LANG wie folgt ändern:
NB : Die Sprache, die zuerst im Parameter -l angegeben wird, ist die primäre Sprache.

Und sie erhalten die folgende Ausgabe:

esseract hat keine Funktion, um die Sprache des Textes in einem Bild automatisch zu erkennen. Eine alternative Lösung bietet ein anderes Python-Modul namens langdetect, das über pip installiert werden kann.
Dieses Modul wiederum erkennt die Sprache des Textes nicht anhand eines Bildes, sondern benötigt eine Zeichenfolgeneingabe, um die Sprache zu erkennen. Der beste Weg, dies zu tun, besteht darin, zuerst tesseract zu verwenden, um OCR-Text in den Sprachen abzurufen, die Ihrer Meinung nach vorhanden sind, und langdetect , um herauszufinden, welche Sprachen im OCR-Text enthalten sind, und dann OCR erneut mit den gefundenen Sprachen auszuführen.
Angenommen, wir haben einen Text, von dem wir dachten, er sei auf Englisch und Portugiesisch.
NB: Tesseract funktioniert schlecht, wenn in einem Bild mit mehreren Sprachen die in der Konfiguration angegebenen Sprachen falsch sind oder überhaupt nicht erwähnt werden. Dies kann auch das Langdetect-Modul ziemlich irreführen.
Tesseract Einschränkungen:
Tesseract OCR ist sehr leistungsfähig, hat aber einige Einschränkungen.
- Die OCR ist nicht so genau wie einige verfügbare kommerzielle Lösungen .
- Funktioniert nicht gut mit Bildern, die von Artefakten wie partieller Okklusion, verzerrter Perspektive und komplexem Hintergrund betroffen sind.
- Es ist nicht in der Lage, Handschrift zu erkennen.
- Es kann Kauderwelsch finden und dies als OCR-Ausgabe melden.
- Wenn ein Dokument Sprachen außerhalb der in den Argumenten -l LANG angegebenen Sprachen enthält, können die Ergebnisse schlecht sein.
- Es ist nicht immer gut, die natürliche Lesereihenfolge von Dokumenten zu analysieren. Beispielsweise wird möglicherweise nicht erkannt, dass ein Dokument zwei Spalten enthält, und es wird möglicherweise versucht, Text spaltenübergreifend zu verknüpfen.
- Scans von schlechter Qualität können zu OCR von schlechter Qualität führen.
- Es werden keine Informationen darüber angezeigt, zu welcher Schriftfamilie Text gehört.
Fazit :
Tesseract eignet sich perfekt zum Scannen sauberer Dokumente und zeichnet sich durch eine ziemlich hohe Genauigkeit und Variabilität der Schriftarten aus, da die Schulung umfassend war.
Die neueste Version von Tesseract 4.0 unterstützt Deep Learning basierte OCR, die deutlich genauer ist. Die OCR-Engine selbst basiert auf einem LSTM-Netzwerk (Long Short-Term Memory), einem bestimmten Typ eines rekurrenten neuronalen Netzwerks (RNN).
Leave a Reply