LDA Tema de Modelado: Una Explicación
Fondo
Tema de modelado es el proceso de identificación de temas en un conjunto de documentos. Esto puede ser útil para motores de búsqueda, automatización de servicio al cliente y cualquier otra instancia en la que sea importante conocer los temas de los documentos. Hay múltiples métodos para hacer esto, pero aquí explicaré uno: Asignación de Dirichlet Latente (LDA).
El algoritmo
LDA es una forma de aprendizaje no supervisado que ve los documentos como bolsas de palabras (es decir, el orden no importa). LDA funciona primero haciendo una suposición clave: la forma en que se generó un documento fue seleccionando un conjunto de temas y luego, para cada tema, eligiendo un conjunto de palabras. Ahora usted puede estar preguntando » ok, entonces, ¿cómo encuentra los temas?»Bueno, la respuesta es simple: realiza ingeniería inversa de este proceso. Para ello hace lo siguiente para cada documento m:
- Suponga que hay k temas en todos los documentos
- Distribuya estos k temas en el documento m (esta distribución se conoce como α y puede ser simétrica o asimétrica, más sobre esto más adelante) asignando un tema a cada palabra.
- Para cada palabra w en el documento m, asuma que su tema es incorrecto, pero a cada otra palabra se le asigna el tema correcto.
- Probabilísticamente asignar palabra w un tema basado en dos cosas:
– qué temas están en el documento m
– cuántas veces a word w se le ha asignado un tema en particular en todos los documentos (esta distribución se llama β, más sobre esto más adelante) - Repita este proceso varias veces para cada documento y listo!
El Modelo de
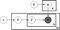
por Encima de lo que se conoce como placa diagrama de un modelo donde LDA:
α es la distribución de temas por documento,
β es la distribución de palabras por tema,
θ es la distribución de temas para el documento m,
φ es la distribución de palabras para el tema k,
z es el tema para la n-ésima palabra en el documento m, y
w es la palabra específica
Ajustando el modelo
En el diagrama del modelo de placas anterior, puede ver que w está en gris. Esto se debe a que es la única variable observable en el sistema, mientras que las demás están latentes. Debido a esto, para modificar el modelo, hay algunas cosas con las que puedes meterte y, a continuación, me centraré en dos.
α es una matriz donde cada fila es un documento y cada columna representa un tema. Un valor en la fila i y la columna j representa la probabilidad de que el documento i contenga el tema j. Una distribución simétrica significaría que cada tema se distribuye uniformemente por todo el documento, mientras que una distribución asimétrica favorece a ciertos temas sobre otros. Esto afecta el punto de partida del modelo y se puede usar cuando se tiene una idea aproximada de cómo se distribuyen los temas para mejorar los resultados.
β es una matriz donde cada fila representa un tema y cada columna representa una palabra. Un valor en la fila i y la columna j representa la probabilidad de que el tema i contenga la palabra j.Por lo general, cada palabra se distribuye uniformemente a lo largo del tema, de modo que ningún tema está sesgado hacia ciertas palabras. Sin embargo, esto se puede explotar para sesgar ciertos temas para favorecer ciertas palabras. Por ejemplo, si sabes que tienes un tema sobre productos Apple, puede ser útil sesgar palabras como» iphone «y» ipad » para uno de los temas con el fin de impulsar el modelo hacia la búsqueda de ese tema en particular.
Conclusión
Este artículo no pretende ser un tutorial completo de LDA, sino más bien dar una visión general de cómo funcionan los modelos de LDA y cómo usarlos. Hay muchas implementaciones por ahí, como Gensim, que son fáciles de usar y muy efectivas. Un buen tutorial sobre el uso de la biblioteca Gensim para el modelado LDA se puede encontrar aquí.
¿Tienes alguna idea o encuentras algo que me perdí? ¡Avísame!
¡Feliz modelado de temas!
Leave a Reply