OCR con Python, OpenCV y PyTesseract

El reconocimiento óptico de caracteres (OCR) es la conversión de imágenes de texto mecanografiado, escrito a mano o impreso en texto codificado por máquina, ya sea a partir de un documento escaneado, una foto de un documento, una foto de una escena (vallas publicitarias en una foto de paisaje) o de un texto superpuesto a una imagen (subtítulos en una emisión de televisión).
El OCR consiste generalmente en subprocesos para realizar con la mayor precisión posible.

- Pre-procesamiento
- Texto de detección
- reconocimiento de Texto
- Post-procesamiento
Los sub-procesos por supuesto, puede variar dependiendo del caso de uso, pero estos son en general los pasos necesarios para realizar el reconocimiento óptico de caracteres.
OCR de Tesseracto :
Tesseract es un motor de reconocimiento de texto de código abierto (OCR), disponible bajo la licencia Apache 2.0. Se puede usar directamente, o (para programadores) usando una API para extraer texto impreso de imágenes. Es compatible con una amplia variedad de idiomas. Tesseract no tiene una interfaz gráfica de usuario incorporada, pero hay varias disponibles en la página de 3rdParty. Tesseract es compatible con muchos lenguajes de programación y frameworks a través de envoltorios que se pueden encontrar aquí. Se puede usar con el análisis de diseño existente para reconocer texto dentro de un documento grande, o se puede usar junto con un detector de texto externo para reconocer texto de una imagen de una sola línea de texto.
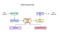
Tesseract 4.00 incluye una nueva red neuronal subsistema configurado como una línea de texto y de reconocimiento. Tiene sus orígenes en la implementación de LSTM basada en Python de OCRopus, pero se ha rediseñado para Tesseract en C++. El sistema de red neuronal en Tesseract es anterior a TensorFlow, pero es compatible con él, ya que hay un lenguaje de descripción de red llamado Lenguaje de Especificación de Gráficos Variables (VGSL), que también está disponible para TensorFlow.
Para reconocer una imagen que contiene un solo carácter, normalmente usamos una Red Neuronal Convolucional (CNN). El texto de longitud arbitraria es una secuencia de caracteres, y tales problemas se resuelven utilizando RNNs y LSTM es una forma popular de RNN. Lea esta publicación para obtener más información sobre LSTM.
Tesseract desarrollado a partir del modelo OCRopus en Python, que era una bifurcación de un LSMT en C++, llamado CLSTM. CLSTM es una implementación del modelo de red neuronal recurrente LSTM en C++.
Tesseract fue un esfuerzo en la limpieza del código y la adición de un nuevo LSTM modelo. La imagen de entrada se procesa en cajas (rectángulo), línea por línea, que se introduce en el modelo LSTM y da salida. En la imagen de abajo podemos visualizar cómo funciona.

Instalación de Tesseract
la Instalación de tesseract en Windows es fácil con los binarios precompilados que se encuentran aquí. No olvide editar la variable de entorno» path » y añadir la ruta de tesseract. Para la instalación de Linux o Mac, se instala con pocos comandos.
De forma predeterminada, Tesseract espera una página de texto cuando segmenta una imagen. Si solo está buscando OCR una región pequeña, pruebe un modo de segmentación diferente, utilizando el argumento-psm. Hay 14 modos disponibles que se pueden encontrar aquí. De forma predeterminada, Tesseract automatiza completamente la segmentación de páginas, pero no realiza la detección de orientación y script. Para especificar el parámetro, escriba lo siguiente:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
También hay un argumento más importante, OCR engine mode (oem). Tesseract 4 tiene dos motores OCR: el antiguo motor Tesseract y el motor LSTM. Hay cuatro modos de operación elegidos usando la opción-oem.
0. Solo motor heredado.
1. Solo motor Neural nets LSTM.
2. Motores Legacy + LSTM.
3. Predeterminado, basado en lo que está disponible.
OCR con Pytesseract y OpenCV:
Pytesseract es una envoltura para el motor Tesseract-OCR. También es útil como script de invocación independiente para tesseract, ya que puede leer todos los tipos de imágenes compatibles con las bibliotecas de imágenes Pillow y Leptonica, incluidas jpeg, png, gif, bmp, tiff y otras. Más información sobre el enfoque de Python, lea aquí.
Preprocesamiento para Tesseract :
Debemos asegurarnos de que la imagen está adecuadamente pre-procesado. para garantizar un cierto nivel de precisión.
Esto incluye el reajuste, la binarización, la eliminación de ruido, el deskewing, etc.
Para preprocesar la imagen para el OCR, utilice cualquiera de las siguientes funciones de python o siga la documentación de OpenCV.
Our input is this image :

Here’s what we get :

Getting boxes around text :
Podemos determinar la información del cuadro delimitador con PyTesseradt utilizando el siguiente código.
El script de abajo le dará información de cuadro delimitador para cada carácter detectado por tesseract durante el OCR.
Si desea cajas alrededor de palabras en lugar de caracteres, la función image_to_data le será útil. Puede utilizar la función image_to_data con el tipo de salida especificado con pytesseract Output.
Usaremos la imagen de recibo de muestra a continuación como entrada para probar tesseract .

este es el código :
El resultado es un diccionario con las siguientes claves :

el Uso de este diccionario, se puede obtener cada palabra detectadas, su cuadro delimitador de la información, el texto en ellos y la confianza de las puntuaciones para cada uno.
Usted puede trazar las cajas mediante el código siguiente :
El resultado:

Como podemos ver Tesseract no es capaz de detectar todos los cuadros de texto con confianza, mala calidad de las exploraciones y de las fuentes pequeñas pueden producir una mala calidad de texto OCR de detección. Tampoco se ha realizado ningún preprocesamiento para mejorar la calidad de la imagen.
Coincidencia de plantilla de texto (detectar solo dígitos ):
Tome el ejemplo de intentar encontrar dónde está una cadena de solo dígitos en una imagen. Aquí nuestra plantilla será un patrón de expresión regular que coincidiremos con nuestros resultados de OCR para encontrar los cuadros delimitadores apropiados. Usaremos el módulo regex y la función image_to_data para esto.

de la Página de la segmentación de los modos de :
Hay varias maneras de analizar una página de texto. La API tesseract proporciona varios modos de segmentación de páginas si desea ejecutar OCR solo en una región pequeña o en diferentes orientaciones,etc.
Aquí hay una lista de los modos de segmentación de páginas compatibles por tesseract:
0. Solo detección de orientación y script (OSD).
1. Segmentación automática de páginas con OSD.
2. Segmentación automática de páginas, pero sin OSD ni OCR.
3. Segmentación de páginas totalmente automática, pero sin OSD. (Predeterminado)
4. Suponga una sola columna de texto de tamaños variables.
5. Supongamos un único bloque uniforme de texto alineado verticalmente.
6. Supongamos un único bloque de texto uniforme.
7. Trate la imagen como una sola línea de texto.
8. Trate la imagen como una sola palabra.
9. Trate la imagen como una sola palabra en un círculo.
10. Trate la imagen como un solo carácter.
11. Texto escaso. Encuentra la mayor cantidad de texto posible sin ningún orden en particular.12. Texto escaso con OSD.13. Línea Raw. Trate la imagen como una sola línea de texto, evitando los hacks que son específicos de Tesseract.
Para cambiar el modo de segmentación de su página, cambie el argumento --psm en su cadena de configuración personalizada a cualquiera de los códigos de modo mencionados anteriormente.
Detecta solo dígitos mediante la configuración:
Puede reconocer solo dígitos cambiando la configuración a lo siguiente:
que da la siguiente salida.

Como puede ver, el resultado no es el mismo el uso de expresiones regulares .
Caracteres de lista blanca / Lista negra:
Digamos que solo desea detectar ciertos caracteres de la imagen dada e ignorar el resto. Puede especificar su lista blanca de caracteres (aquí, solo hemos utilizado todos los caracteres en minúsculas de la a a la z) utilizando la siguiente configuración.
Y nos da este resultado :

listas Negras de las letras :
Si usted está seguro de que algunos personajes o expresiones que sin duda no va a subir en su texto (OCR volverá mal de texto en lugar de la lista negra de personajes de otra manera), usted puede poner los caracteres mediante la siguiente config.
Salida :
Varios idiomas de texto :
Para especificar el idioma que usted necesita a su salida de OCR, utilice la etiqueta -l LANG argumento en la config donde LANG es el 3 código de letras para qué idioma que desea utilizar.
Usted puede trabajar con varios idiomas, cambiando el parámetro LANG tales como :
NB : El idioma especificado primero en el parámetro -l es el idioma principal.

Y obtendrá el siguiente resultado :

Por desgracia tesseract no tiene una función para detectar el idioma del texto en una imagen automáticamente. Una solución alternativa es proporcionada por otro módulo de python llamado langdetect que se puede instalar a través de pip para obtener más información, consulte este enlace.
Este módulo, de nuevo, no detecta el idioma del texto usando una imagen, pero necesita una entrada de cadena para detectar el idioma. La mejor manera de hacerlo es primero usando tesseract para obtener texto de OCR en cualquier idioma que pueda sentir que está allí, usando langdetect para encontrar qué idiomas están incluidos en el texto de OCR y luego ejecute OCR de nuevo con los idiomas encontrados.
Digamos que tenemos un texto que pensamos que estaba en inglés y portugués.
NB: Tesseract funciona mal cuando, en una imagen con varios idiomas, los idiomas especificados en la configuración son incorrectos o no se mencionan en absoluto. Esto también puede inducir a error al módulo langdetect.
Limitaciones de Tesseract:
Tesseract OCR es bastante potente, pero tiene algunas limitaciones.
- El OCR no es tan preciso como algunas soluciones comerciales disponibles .
- No funciona bien con imágenes afectadas por artefactos, como oclusión parcial, perspectiva distorsionada y fondo complejo.
- no es capaz de reconocer la escritura a mano.
- Puede encontrar galimatías e informar de esto como salida OCR.
- Si un documento contiene idiomas distintos de los indicados en los argumentos-l LANG, los resultados pueden ser pobres.
- No siempre es bueno para analizar el orden natural de lectura de los documentos. Por ejemplo, puede no reconocer que un documento contiene dos columnas y puede intentar unir texto entre columnas.
- Las exploraciones de mala calidad pueden producir OCR de mala calidad.
- No expone información sobre a qué familia de fuentes pertenece el texto.
Conclusión:
Tesseract es perfecto para escanear documentos limpios y viene con una precisión y variabilidad de fuentes bastante altas, ya que su capacitación fue completa.
La última versión de Tesseract 4.0 admite OCR basado en aprendizaje profundo que es significativamente más preciso. El motor OCR en sí está construido sobre una red de Memoria a Corto Plazo (LSTM), que es un tipo particular de Red Neuronal Recurrente (RNN).
Leave a Reply