Comment Effacer le Cache sous Linux
Le cache du système de fichiers Linux (Cache de page) est utilisé pour accélérer les opérations d’E/S. Dans certaines circonstances, un administrateur ou un développeur peut vouloir vider manuellement le cache. Dans cet article, nous expliquerons comment fonctionne le cache du système de fichiers Linux. Ensuite, nous montrerons comment surveiller l’utilisation du cache et comment effacer le cache. Nous ferons quelques expériences de performances simples pour vérifier que le cache fonctionne comme prévu et que la procédure de vidage et d’effacement du cache fonctionne également comme prévu.
Fonctionnement du cache du système de fichiers Linux
Le noyau réserve une certaine quantité de mémoire système pour mettre en cache les accès au disque du système de fichiers afin d’accélérer les performances globales. Le cache sous Linux s’appelle le Cache de page. La taille du cache de page est configurable avec des valeurs par défaut généreuses activées pour mettre en cache de grandes quantités de blocs de disque. La taille maximale du cache et les stratégies d’expulsion des données du cache sont réglables avec les paramètres du noyau. L’approche du cache Linux est appelée cache de réécriture. Cela signifie que si des données sont écrites sur le disque, elles sont écrites en mémoire dans le cache et marquées comme sales dans le cache jusqu’à ce qu’elles soient synchronisées sur le disque. Le noyau maintient des structures de données internes pour optimiser les données à expulser du cache lorsque plus d’espace est nécessaire dans le cache.
Pendant les appels système de lecture Linux, le noyau vérifiera si les données demandées sont stockées dans des blocs de données dans le cache, ce serait un succès du cache et les données seront renvoyées du cache sans faire d’E/S au système de disque. Pour un manque de cache, les données seront extraites du système d’E/S et le cache mis à jour en fonction des stratégies de mise en cache, car ces mêmes données seront probablement à nouveau demandées.
Lorsque certains seuils d’utilisation de la mémoire sont atteints, les tâches en arrière-plan commencent à écrire des données sales sur le disque pour s’assurer qu’elles effacent le cache mémoire. Ceux-ci peuvent avoir un impact sur les performances des applications gourmandes en mémoire et en CPU et nécessiter un réglage par les administrateurs et / ou les développeurs.
En utilisant la commande Free pour afficher l’utilisation du cache
Nous pouvons utiliser la commande free depuis la ligne de commande afin d’analyser la mémoire système et la quantité de mémoire allouée à la mise en cache. Voir la commande ci-dessous:
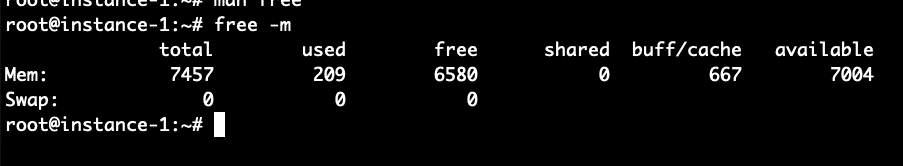
Ce que nous voyons de la commande libre ci-dessus, c’est qu’il y a 7,5 Go de RAM sur ce système. De ce nombre, seuls 209 Mo sont utilisés et 6,5 Mo sont gratuits. 667 Mo sont utilisés dans le cache tampon. Essayons maintenant d’augmenter ce nombre en exécutant une commande pour générer un fichier de 1 Gigaoctet et en lisant le fichier. La commande ci-dessous générera environ 100 Mo de données aléatoires, puis ajoutera 10 copies du fichier ensemble dans un fichier large_file.
# pour i dans `seq 1 10`; do echo $i; cat data_file >> large_file; done
Maintenant, nous allons nous assurer de lire ce fichier de 1 Gig et de vérifier à nouveau la commande free:
#free-m

Nous pouvons voir que l’utilisation du cache tampon a augmenté depuis 667 à 1735 Mégaoctets une augmentation d’environ 1 gigaoctet de l’utilisation du cache tampon.
Commande Proc Sys VM Drop Caches
Le noyau linux fournit une interface pour supprimer le cache essayons ces commandes et voyons l’impact sur le paramètre libre.
#free-m

Nous pouvons voir ci-dessus que la majorité l’allocation du cache tampon a été libérée avec cette commande.
Vérification expérimentale que les caches de dépôt Fonctionnent
Pouvons-nous effectuer une validation des performances de l’utilisation du cache pour lire le fichier? Lisons le fichier et réécrivons-le dans /dev/null afin de tester le temps nécessaire pour lire le fichier à partir du disque. Nous le chronométrerons avec la commande de temps. Nous faisons cette commande immédiatement après avoir effacé le cache avec les commandes ci-dessus.

Il a fallu 8,4 secondes pour lire le fichier. Relisons-le maintenant que le fichier doit être dans le cache du système de fichiers et voyons combien de temps cela prend maintenant.
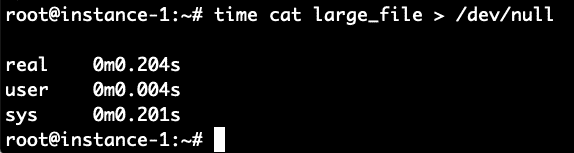
Boom! Il n’a fallu que.2 secondes contre 8,4 secondes pour le lire lorsque le fichier n’était pas mis en cache. Pour vérifier, répétons-le en vidant d’abord le cache, puis en lisant le fichier 2 fois.
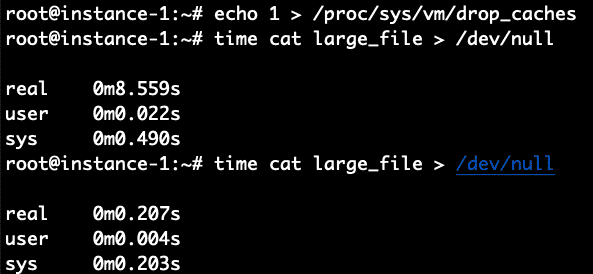
Cela a parfaitement fonctionné comme prévu. 8.5 secondes pour la lecture non mise en cache et.2 secondes pour la lecture en cache.
Conclusion
Le cache de page est automatiquement activé sur les systèmes Linux et accélère de manière transparente les E/S en stockant les données récemment utilisées dans le cache. Si vous souhaitez vider manuellement le cache, cela peut être fait facilement en envoyant une commande echo au système de fichiers /proc indiquant au noyau de supprimer le cache et de libérer la mémoire utilisée pour le cache. Les instructions d’exécution de la commande ont été montrées ci-dessus dans cet article et la validation expérimentale du comportement du cache avant et après le rinçage a également été montrée.
Leave a Reply