Modélisation du sujet LDA: Une explication
Background
La modélisation de sujets est le processus d’identification de sujets dans un ensemble de documents. Cela peut être utile pour les moteurs de recherche, l’automatisation du service client et toute autre instance où la connaissance des sujets des documents est importante. Il existe plusieurs méthodes pour le faire, mais ici, je vais en expliquer une: Allocation de Dirichlet latente (LDA).
L’algorithme
LDA est une forme d’apprentissage non supervisé qui considère les documents comme des sacs de mots (l’ordre n’a pas d’importance). LDA fonctionne en faisant d’abord une hypothèse clé: la façon dont un document a été généré était de choisir un ensemble de sujets, puis pour chaque sujet de choisir un ensemble de mots. Maintenant, vous demandez peut-être « ok alors comment trouve-t-il des sujets? »Eh bien, la réponse est simple: il inverse ce processus. Pour ce faire, il effectue les opérations suivantes pour chaque document m:
- Supposons qu’il y a k sujets dans tous les documents
- Distribuez ces k sujets dans le document m (cette distribution est connue sous le nom de α et peut être symétrique ou asymétrique, plus à ce sujet plus loin) en attribuant à chaque mot un sujet.
- Pour chaque mot w dans le document m, supposons que son sujet est incorrect mais que le sujet correct est attribué à chaque autre mot.
- Attribuez de manière probabiliste à word w un sujet basé sur deux choses:
– quels sont les sujets du document m
– combien de fois word w a été affecté à un sujet particulier dans tous les documents (cette distribution est appelée β, plus à ce sujet plus tard) - Répétez ce processus plusieurs fois pour chaque document et vous avez terminé!
Le modèle
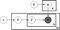
Ci-dessus est ce que l’on appelle un diagramme en plaques d’un modèle LDA où:
α est la distribution de sujet par document,
β est la distribution de mot par sujet,
θ est la distribution de sujet pour le document m,
φ est la distribution de mot pour le sujet k,
z est la rubrique pour le n-th mot dans le document m, et
w est le mot spécifique
Peaufinant le modèle
Dans le diagramme de modèle de plaque ci-dessus, vous pouvez voir que w est grisé. C’est parce que c’est la seule variable observable dans le système alors que les autres sont latentes. Pour cette raison, pour modifier le modèle, il y a quelques choses avec lesquelles vous pouvez jouer et ci-dessous, je me concentre sur deux.
α est une matrice où chaque ligne est un document et chaque colonne représente un sujet. Une valeur dans la ligne i et la colonne j représente la probabilité que le document i contienne le sujet j. Une distribution symétrique signifierait que chaque sujet est réparti uniformément dans le document tandis qu’une distribution asymétrique favorise certains sujets par rapport à d’autres. Cela affecte le point de départ du modèle et peut être utilisé lorsque vous avez une idée approximative de la façon dont les sujets sont distribués pour améliorer les résultats.
β est une matrice où chaque ligne représente un sujet et chaque colonne représente un mot. Une valeur dans la ligne i et la colonne j représente la probabilité que ce sujet i contienne le mot j. Habituellement, chaque mot est réparti uniformément dans le sujet de sorte qu’aucun sujet ne soit biaisé vers certains mots. Cela peut cependant être exploité afin de biaiser certains sujets pour favoriser certains mots. Par exemple, si vous savez que vous avez un sujet sur les produits Apple, il peut être utile de biaiser des mots comme « iphone” et « ipad” pour l’un des sujets afin de pousser le modèle vers la recherche de ce sujet particulier.
Conclusion
Cet article n’est pas destiné à être un tutoriel LDA complet, mais plutôt à donner un aperçu du fonctionnement des modèles LDA et de leur utilisation. Il existe de nombreuses implémentations telles que Gensim qui sont faciles à utiliser et très efficaces. Un bon tutoriel sur l’utilisation de la bibliothèque Gensim pour la modélisation LDA peut être trouvé ici.
Avez-vous des pensées ou trouvez quelque chose que j’ai manqué? Fais-le moi savoir!
Bonne modélisation de sujet!
Leave a Reply