OCR avec Python, OpenCV et PyTesseract

La reconnaissance optique de caractères (OCR) est la conversion d’images de texte dactylographié, manuscrit ou imprimé en texte codé par machine, que ce soit à partir d’un document numérisé, d’une photo d’un document, d’une photo d’une scène (panneaux d’affichage dans une photo de paysage) ou d’un texte superposé à une image (sous-titres sur une émission de télévision).
L’OCR consiste généralement en sous-processus à effectuer aussi précisément que possible.

- Prétraitement
- Détection de texte
- Reconnaissance de texte
- Post-traitement
Les sous-processus peuvent bien sûr varier selon les cas d’utilisation mais ce sont généralement les étapes nécessaires pour effectuer la reconnaissance optique de caractères.
Tesseract OCR :
Tesseract est un moteur de reconnaissance de texte (OCR) open source, disponible sous la licence Apache 2.0. Il peut être utilisé directement, ou (pour les programmeurs) en utilisant une API pour extraire le texte imprimé des images. Il prend en charge une grande variété de langues. Tesseract n’a pas d’interface graphique intégrée, mais il en existe plusieurs disponibles sur la page 3rdParty. Tesseract est compatible avec de nombreux langages de programmation et frameworks via des wrappers disponibles ici. Il peut être utilisé avec l’analyse de mise en page existante pour reconnaître le texte dans un grand document, ou il peut être utilisé en conjonction avec un détecteur de texte externe pour reconnaître le texte d’une image d’une seule ligne de texte.
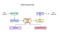
Tesseract 4.00 inclut un nouveau sous-système de réseau neuronal configuré en tant que reconnaissance de ligne de texte. Il a ses origines dans l’implémentation LSTM basée sur Python d’OCRopus, mais a été repensé pour Tesseract en C++. Le système de réseau neuronal de Tesseract est antérieur à TensorFlow, mais il est compatible avec lui, car il existe un langage de description de réseau appelé Variable Graph Specification Language (VGSL), également disponible pour TensorFlow.
Pour reconnaître une image contenant un seul caractère, nous utilisons généralement un réseau de neurones convolutifs (CNN). Le texte de longueur arbitraire est une séquence de caractères, et de tels problèmes sont résolus en utilisant RNNs et LSTM est une forme populaire de RNN. Lisez cet article pour en savoir plus sur LSTM.
Tesseract a été développé à partir du modèle OCRopus en Python qui était un fork d’un LSMT en C++, appelé CLSTM. CLSTM est une implémentation du modèle de réseau neuronal récurrent LSTM en C++.
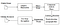
Tesseract était un effort de nettoyage de code et d’ajout d’un nouveau modèle LSTM. L’image d’entrée est traitée dans des cases (rectangle) ligne par ligne entrant dans le modèle LSTM et donnant la sortie. Dans l’image ci-dessous, nous pouvons visualiser comment cela fonctionne.

Installation de Tesseract
L’installation de tesseract sous Windows est facile avec les binaires précompilés trouvés ici. N’oubliez pas d’éditer la variable d’environnement « path” et d’ajouter le chemin tesseract. Pour une installation Linux ou Mac, il est installé avec peu de commandes.
Par défaut, Tesseract attend une page de texte lorsqu’il segmente une image. Si vous cherchez simplement à OCR une petite région, essayez un mode de segmentation différent, en utilisant l’argument —psm. Il y a 14 modes disponibles qui peuvent être trouvés ici. Par défaut, Tesseract automatise entièrement la segmentation des pages mais n’effectue pas d’orientation ni de détection de script. Pour spécifier le paramètre, tapez ce qui suit :
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
Il existe également un autre argument important, le mode moteur OCR (oem). Tesseract 4 a deux moteurs OCR – le moteur Tesseract hérité et le moteur LSTM. Il existe quatre modes de fonctionnement choisis en utilisant l’option —oem.
0. Moteur hérité uniquement.
1. Moteur LSTM des réseaux neuronaux uniquement.
2. Moteurs Legacy + LSTM.
3. Par défaut, en fonction de ce qui est disponible.
OCR avec Pytesseract et OpenCV :
Pytesseract est un wrapper pour le moteur Tesseract-OCR. Il est également utile en tant que script d’invocation autonome pour tesseract, car il peut lire tous les types d’images pris en charge par les bibliothèques d’imagerie Pillow et Leptonica, y compris jpeg, png, gif, bmp, tiff et autres. Plus d’informations sur l’approche Python à lire ici.
Prétraitement pour Tesseract:
Nous devons nous assurer que l’image est correctement prétraitée. pour assurer un certain niveau de précision.
Cela inclut le redimensionnement, la binarisation, la suppression du bruit, la désembuage, etc.
Pour prétraiter l’image pour l’OCR, utilisez l’une des fonctions python suivantes ou suivez la documentation OpenCV.
Our input is this image :

Here’s what we get :

Getting boxes around text :
Nous pouvons déterminer les informations de la boîte englobante avec PyTesseradt en utilisant le code suivant.
Le script ci-dessous vous donnera des informations de boîte englobante pour chaque caractère détecté par tesseract pendant l’OCR.
Si vous voulez des boîtes autour des mots au lieu de caractères, la fonction image_to_data vous sera utile. Vous pouvez utiliser la fonction image_to_data avec le type de sortie spécifié avec pytesseract Output.
Nous utiliserons l’image de reçu d’échantillon ci-dessous comme entrée pour tester tesseract.

Voici le code:
La sortie est un dictionnaire avec les clés suivantes:

En utilisant ce dictionnaire, nous pouvons obtenir chaque mot détecté, leurs informations de boîte englobante, le texte qu’il contient et les scores de confiance pour chacun.
Vous pouvez tracer les cases en utilisant le code ci-dessous:
La sortie:

Comme nous pouvons le voir, Tesseract n’est pas capable de détecter toutes les zones de texte en toute confiance, les scans de mauvaise qualité et les petites polices peuvent produire une détection de texte OCR de mauvaise qualité. De plus, aucun prétraitement n’a été effectué pour améliorer la qualité de l’image.
Correspondance des modèles de texte (détection uniquement des chiffres):
Prenons l’exemple d’essayer de trouver où se trouve une chaîne de chiffres dans une image. Ici, notre modèle sera un modèle d’expression régulière que nous associerons à nos résultats OCR pour trouver les boîtes de délimitation appropriées. Nous utiliserons le module regex et la fonction image_to_data pour cela.

Modes de segmentation des pages :
Il existe plusieurs façons d’analyser une page de texte. L’api tesseract fournit plusieurs modes de segmentation de page si vous souhaitez exécuter l’OCR sur une petite région ou dans des orientations différentes, etc.
Voici une liste des modes de segmentation de page pris en charge par tesseract :
0. Orientation et détection de script (OSD) uniquement.
1. Segmentation automatique des pages avec OSD.
2. Segmentation automatique des pages, mais pas d’OSD ou d’OCR.
3. Segmentation de page entièrement automatique, mais pas d’OSD. (Par défaut)
4. Supposons une seule colonne de texte de tailles variables.
5. Supposons un seul bloc uniforme de texte aligné verticalement.
6. Supposons un seul bloc de texte uniforme.
7. Traitez l’image comme une seule ligne de texte.
8. Traitez l’image comme un seul mot.
9. Traitez l’image comme un seul mot dans un cercle.
10. Traitez l’image comme un seul caractère.
11. Texte clairsemé. Trouvez autant de texte que possible sans ordre particulier.
12. Texte clairsemé avec OSD.
13. Ligne brute. Traitez l’image comme une seule ligne de texte, en contournant les hacks spécifiques à Tesseract.
Pour changer le mode de segmentation de votre page, remplacez l’argument --psm dans votre chaîne de configuration personnalisée par l’un des codes de mode mentionnés ci-dessus.
Détecter uniquement les chiffres en utilisant la configuration:
Vous pouvez reconnaître uniquement les chiffres en changeant la configuration à la suivante:
ce qui donne la sortie suivante.

Comme vous pouvez le voir, la sortie n’est pas la même en utilisant regex.
Caractères de liste blanche / liste noire:
Disons que vous voulez seulement détecter certains caractères de l’image donnée et ignorer le reste. Vous pouvez spécifier votre liste blanche de caractères (ici, nous avons utilisé tous les caractères minuscules de a à z uniquement) en utilisant la configuration suivante.
Et cela nous donne cette sortie :

Lettres de liste noire:
Si vous êtes sûr que certains caractères ou expressions n’apparaîtront certainement pas dans votre texte (l’OCR renverra un mauvais texte à la place des caractères sur liste noire sinon), vous pouvez mettre ces caractères sur liste noire en utilisant la configuration suivante.
Sortie :

Texte en plusieurs langues:
Pour spécifier la langue dans laquelle vous avez besoin de votre sortie OCR, utilisez l’argument -l LANG dans la configuration où LANG est le code à 3 lettres de la langue que vous souhaitez utiliser.
Vous pouvez travailler avec plusieurs langues en modifiant le paramètre LANG en tant que tel :
NB : La langue spécifiée en premier pour le paramètre -l est la langue principale.

Et vous obtiendrez la sortie suivante:

Malheureusement, tesseract n’a pas de fonction pour détecter automatiquement la langue du texte dans une image. Une solution alternative est fournie par un autre module python appelé langdetect qui peut être installé via pip pour plus d’informations, consultez ce lien.
Ce module ne détecte pas encore la langue du texte à l’aide d’une image mais nécessite une entrée de chaîne pour détecter la langue. La meilleure façon de le faire est d’utiliser d’abord tesseract pour obtenir du texte OCR dans les langues que vous pourriez ressentir, en utilisant langdetect pour trouver les langues incluses dans le texte OCR, puis exécutez à nouveau l’OCR avec les langues trouvées.
Disons que nous avons un texte que nous pensions être en anglais et en portugais.
NB: Tesseract fonctionne mal lorsque, dans une image avec plusieurs langues, les langues spécifiées dans la configuration sont erronées ou ne sont pas du tout mentionnées. Cela peut également induire en erreur le module langdetect.
Tesseract limitations:
Tesseract OCR est assez puissant mais a quelques limitations.
- L’OCR n’est pas aussi précis que certaines solutions commerciales disponibles.
- Ne fonctionne pas bien avec les images affectées par des artefacts, y compris une occlusion partielle, une perspective déformée et un arrière-plan complexe.
- Il n’est pas capable de reconnaître l’écriture manuscrite.
- Il peut trouver du charabia et le signaler comme sortie OCR.
- Si un document contient des langues en dehors de celles données dans les arguments -l LANG, les résultats peuvent être médiocres.
- Il n’est pas toujours bon pour analyser l’ordre de lecture naturel des documents. Par exemple, il peut ne pas reconnaître qu’un document contient deux colonnes et peut essayer de joindre du texte entre les colonnes.
- Les scans de mauvaise qualité peuvent produire une ROC de mauvaise qualité.
- Il n’expose pas d’informations sur la famille de polices à laquelle appartient le texte.
Conclusion:
Tesseract est parfait pour numériser des documents propres et est livré avec une précision et une variabilité de police assez élevées car sa formation était complète.
La dernière version de Tesseract 4.0 prend en charge l’OCR basée sur l’apprentissage profond qui est nettement plus précise. Le moteur OCR lui-même est construit sur un réseau de mémoire à Long Terme (LSTM), qui est un type particulier de Réseau neuronal Récurrent (RNN).
Leave a Reply