Ldaトピックモデリング:説明
背景
トピックモデリングは、ドキュメントのセット内のトピックを識別するプロセスです。 これは、検索エンジン、顧客サービスの自動化、およびドキュメントのトピックを知ることが重要である他のインスタンスに便利です。 これを行うには複数の方法がありますが、ここでは1つを説明します: ディリクレ(LDA)の愛称で知られる。
アルゴリズム
ldaは、文書を単語の袋として見る教師なし学習の一形態です(つまり、順序は問題ではありません)。 LDAは、最初に重要な前提を作ることによって動作します:文書が生成された方法は、トピックのセットを選択し、各トピックのために単語のセットを選 今、あなたは”okだから、どのようにトピックを見つけるのですか?”まあ答えは簡単です:それはこのプロセスをリバースエンジニアリング。 これを行うには、各文書mに対して次のことを行います:
- すべての文書にk個のトピックがあると仮定します
- これらのk個のトピックを文書mに配布します(この分布はαと呼ばれ、対称または非対称
- 文書mの各単語wについて、そのトピックは間違っていると仮定しますが、他のすべての単語には正しいトピックが割り当てられています。
- 確率的に単語wに二つのことに基づいてトピックを割り当てます:
-ドキュメントmにあるトピック
-word wがすべてのドキュメントに特定のトピックを割り当てられた回数(この分布はβと呼ばれ、詳細は後述します) - このプロセスを各ドキュメントに対して何度も繰り返すと完了です!
モデル
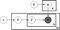
上記は、ldaモデルのプレート図として知られているものです。:
αは文書ごとのトピック分布、
βはトピックごとの単語分布、
γは文書mのトピック分布、
φはトピックkの単語分布、
zは文書mのn番目の単語のトピック、
wは特定の単語
モデルを微調整する
上のプレートモデル図では、wがグレーアウトされていることがわかります。 これは、それがシステム内で唯一の観測可能な変数であり、他の変数は潜在的であるためです。 このため、モデルを微調整するために、あなたが混乱することができるいくつかのことがあり、以下では2つに焦点を当てます。
αは、各行が文書であり、各列がトピックを表す行列です。 対称分布は、各トピックがドキュメント全体に均等に分布し、非対称分布は特定のトピックを他のトピックよりも優先することを意味します。 これはモデルの開始点に影響し、結果を改善するためにトピックがどのように分散されるかを大まかに把握している場合に使用できます。
βは、各行がトピックを表し、各列が単語を表す行列です。 通常、各単語はトピック全体に均等に分散され、トピックが特定の単語に偏っていないようにします。 これは、特定のトピックに偏見を与えて特定の単語を支持するために悪用される可能性があります。 たとえば、Apple製品に関するトピックがあることがわかっている場合は、モデルを特定のトピックを見つけるために、トピックの1つに「iphone」や「ipad」などの
結論
この記事は、本格的なLDAチュートリアルではなく、LDAモデルがどのように機能し、どのように使用されるかの概要を説明します。 Gensimなど、使いやすく非常に効果的な多くの実装があります。 LdaモデリングのためのGensimライブラリの使用に関する良いチュートリアルはここにあります。何か考えがあるか、私が逃した何かを見つけますか?
私に知らせて!幸せなトピックモデリング!
Leave a Reply