Python、OpenCV、およびPyTesseractを使用したOCR

光学式文字認識(ocr)は、スキャンした文書、文書の写真、シーン(風景写真の看板)からの写真、または画像に重畳されたテキスト(テレビ放送の字幕)かどうか、入力された、手書きまたは印刷されたテキストの画像を機械でエンコードされたテキストに変換することである。OCRは、できるだけ正確に実行するためのサブプロセスで構成されています。
OCRは、一般的にサブプロセスで構成されています。p>

- 前処理
- テキスト検出
- テキスト認識
- 後処理
サブプロセスはもちろん、ユースケースによって異なりますが、これらは一般的に光学文字認識を実行す
Tesseract OCR :Tesseractはオープンソースのテキスト認識(OCR)エンジンであり、Apache2.0ライセンスの下で利用可能です。 これは、直接使用することも、(プログラマの場合)APIを使用して画像から印刷されたテキストを抽出することもできます。 これは、さまざまな言語をサポートしています。 TesseractにはGUIが組み込まれていませんが、3rdPartyページからいくつか利用できます。 Tesseractは、ここにあるラッパーを介して多くのプログラミング言語やフレームワークと互換性があります。 既存のレイアウト解析と一緒に使用して、大きな文書内のテキストを認識したり、外部テキスト検出器と組み合わせて使用して、単一のテキスト行の画像からテキストを認識したりすることができます。DIV>
tesseract4.00には、テキスト行認識器として構成された新しいニューラルネットワークサブシステムが含まれています。 これはOCRopusのPythonベースのLSTM実装に起源を持っていますが、C++のTesseract用に再設計されました。 TesseractのニューラルネットワークシステムはTensorFlowの前の日付ですが、Tensorflowでも利用可能な可変グラフ仕様言語(VGSL)と呼ばれるネットワーク記述言語があるため、互換性が
単一の文字を含む画像を認識するには、通常、畳み込みニューラルネットワーク(CNN)を使用します。 任意の長さのテキストは一連の文字であり、そのような問題はRnnを使用して解決され、LSTMはRNNの一般的な形式です。 LSTMの詳細については、この記事をお読みください。Tesseractは、CLSTMと呼ばれるC++のLSMTのフォークであったPythonのOCRopusモデルから開発されました。 CLSTMは、C++でのlstmリカレントニューラルネットワークモデルの実装です。p>
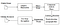
![]()
紙からテッセラクト3OCRプロセス
紙からテッセラクト3OCRプロセス
![]()
tesseractは、コードのクリーニングと新しいlstmモデルの追加に取り組んでいました。 入力画像は、lstmモデルにラインフィードし、出力を与えることによってボックス(長方形)ラインで処理されます。 下の画像では、それがどのように機能するかを視覚化することができます。Div>

![]()
TesseractがLSTMモデルプレゼンテーションをどのように使用するか
TesseractがLSTMモデルプレゼンテーションをどのように使用するか ![]()
tesseractのインストール
windowsへのtesseractのインストールは、ここにあるプリコンパイルされたバイナリで簡単です。 “Path”環境変数を編集し、tesseract pathを追加することを忘れないでください。 LinuxまたはMacのインストールでは、いくつかのコマンドでインストールされます。
デフォルトでは、Tesseractは画像をセグメント化するときにテキストのページを期待します。 小さな領域をOCRしようとしているだけの場合は、—psm引数を使用して別のセグメンテーションモードを試してみてください。 ここで見つけることができる利用可能な14のモードがあります。 デフォルトでは、Tesseractはページ分割を完全に自動化しますが、向きとスクリプトの検出は実行しません。 パラメータを指定するには、次のように入力します。
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
もう一つの重要な引数、OCRエンジンモード(oem)もあります。 Tesseract4には、従来のTesseractエンジンとLSTMエンジンの2つのOCRエンジンがあります。 —Oemオプションを使用して選択された4つの操作モードがあります。
0. レガシーエンジンのみ。
1. ニューラルネットLSTMエンジンのみ。
2. レガシー+LSTMエンジン。
3. 利用可能なものに基づいて、デフォルト。PYTESSERACTとOpenCVを使用したOCR:
PytesseractはTesseract-OCRエンジンのラッパーです。 また、jpeg、png、gif、bmp、tiffなど、PillowおよびLeptonicaイメージングライブラリでサポートされているすべてのイメージタイプを読み取ることができるため、tesseractのスタンドアロン呼 Pythonのアプローチについての詳細はこちらをお読みください。P>
Tesseractの前処理:
画像が適切に前処理されていることを確認する必要があります。 ある特定のレベルの正確さを保障するため。
これには、再スケーリング、二値化、ノイズ除去、deskewingなどが含まれます。OCR用の画像を前処理するには、次のpython関数のいずれかを使用するか、OpenCVのドキュメントに従います。
Our input is this image :

![]()
Here’s what we get :

![]()
Getting boxes around text :次のコードを使用して、PyTesseradtを使用して境界ボックス情報を決定できます。以下のスクリプトは、OCR中にtesseractによって検出された各文字の境界ボックス情報を提供します。
以下のスクリプトは、OCR中にtesseractによって検出された各文字文字の代わりに単語の周りにボックスを配置したい場合は、関数image_to_dataが便利です。 PytesseractOutputimage_to_data関数を使用できます。tesseractをテストするための入力として、以下のサンプル領収書画像を使用します。
/div>
tesseract4.00には、テキスト行認識器として構成された新しいニューラルネットワークサブシステムが含まれています。 これはOCRopusのPythonベースのLSTM実装に起源を持っていますが、C++のTesseract用に再設計されました。 TesseractのニューラルネットワークシステムはTensorFlowの前の日付ですが、Tensorflowでも利用可能な可変グラフ仕様言語(VGSL)と呼ばれるネットワーク記述言語があるため、互換性が
単一の文字を含む画像を認識するには、通常、畳み込みニューラルネットワーク(CNN)を使用します。 任意の長さのテキストは一連の文字であり、そのような問題はRnnを使用して解決され、LSTMはRNNの一般的な形式です。 LSTMの詳細については、この記事をお読みください。Tesseractは、CLSTMと呼ばれるC++のLSMTのフォークであったPythonのOCRopusモデルから開発されました。 CLSTMは、C++でのlstmリカレントニューラルネットワークモデルの実装です。p>
tesseractは、コードのクリーニングと新しいlstmモデルの追加に取り組んでいました。 入力画像は、lstmモデルにラインフィードし、出力を与えることによってボックス(長方形)ラインで処理されます。 下の画像では、それがどのように機能するかを視覚化することができます。Div>
tesseractのインストール
windowsへのtesseractのインストールは、ここにあるプリコンパイルされたバイナリで簡単です。 “Path”環境変数を編集し、tesseract pathを追加することを忘れないでください。 LinuxまたはMacのインストールでは、いくつかのコマンドでインストールされます。
デフォルトでは、Tesseractは画像をセグメント化するときにテキストのページを期待します。 小さな領域をOCRしようとしているだけの場合は、—psm引数を使用して別のセグメンテーションモードを試してみてください。 ここで見つけることができる利用可能な14のモードがあります。 デフォルトでは、Tesseractはページ分割を完全に自動化しますが、向きとスクリプトの検出は実行しません。 パラメータを指定するには、次のように入力します。
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
もう一つの重要な引数、OCRエンジンモード(oem)もあります。 Tesseract4には、従来のTesseractエンジンとLSTMエンジンの2つのOCRエンジンがあります。 —Oemオプションを使用して選択された4つの操作モードがあります。
0. レガシーエンジンのみ。
1. ニューラルネットLSTMエンジンのみ。
2. レガシー+LSTMエンジン。
3. 利用可能なものに基づいて、デフォルト。PYTESSERACTとOpenCVを使用したOCR:
PytesseractはTesseract-OCRエンジンのラッパーです。 また、jpeg、png、gif、bmp、tiffなど、PillowおよびLeptonicaイメージングライブラリでサポートされているすべてのイメージタイプを読み取ることができるため、tesseractのスタンドアロン呼 Pythonのアプローチについての詳細はこちらをお読みください。P>
Tesseractの前処理:
画像が適切に前処理されていることを確認する必要があります。 ある特定のレベルの正確さを保障するため。
これには、再スケーリング、二値化、ノイズ除去、deskewingなどが含まれます。OCR用の画像を前処理するには、次のpython関数のいずれかを使用するか、OpenCVのドキュメントに従います。
Our input is this image :
Here’s what we get :
Getting boxes around text :次のコードを使用して、PyTesseradtを使用して境界ボックス情報を決定できます。以下のスクリプトは、OCR中にtesseractによって検出された各文字の境界ボックス情報を提供します。
以下のスクリプトは、OCR中にtesseractによって検出された各文字文字の代わりに単語の周りにボックスを配置したい場合は、関数image_to_dataが便利です。 PytesseractOutputimage_to_data関数を使用できます。tesseractをテストするための入力として、以下のサンプル領収書画像を使用します。
/div>
出力は、次のキーを持つ辞書です。

出力は、次のキーを持つ辞書です。
出力は、次のキーを持つ辞書です。
この辞書を使用して、検出された各単語、境界ボックス情報、それらのテキスト、それぞれの信頼スコアを取得次のコードを使用してボックスをプロットできます。
出力:

div>
tesseractはすべてのテキストボックスを自信を持って検出することができないことがわかります。 また、画像の品質を向上させるための前処理は行われていない。
テキストテンプレートマッチング(数字のみを検出):
画像内の数字のみの文字列がどこにあるかを見つけようとする例を見てみましょう。 ここで私たちのテンプレートは、適切な境界ボックスを見つけるために私たちのOCRの結果と一致する正規表現パターンになります。 これにはregeximage_to_data関数を使用します。div>

ページセグメンテーションモード :テキストのページを分析するには、いくつかの方法があります。
TESSERACT apiは、小さな領域や異なる向きなどでOCRを実行する場合に、いくつかのページ分割モードを提供します。
tesseractでサポートされているページ分割モードのリストは次のとおりです。
0. 方向およびスクリプト検出(OSD)のみ。
1. OSDによる自動ページ分割。
2. 自動ページ分割、ただしOSD、またはOCRはありません。
3. 完全に自動のページ分割、しかしOSD無し。 (デフォルト)
4. 可変サイズのテキストの単一の列を想定します。
5. 垂直方向に整列したテキストの単一の一様なブロックを想定します。
6. 単一の一様なテキストブロックを想定します。
7. 画像を単一のテキスト行として扱います。
8. 画像を単一の単語として扱います。
9. 画像を円の中の単一の単語として扱います。
10. 画像を単一の文字として扱います。
11. スパーステキスト。 できるだけ多くのテキストを特定の順序で検索します。
12. Osdを使用したスパーステキスト。
13. 生のライン。 画像を単一のテキスト行として扱い、Tesseract固有のハックをバイパスします。ページ分割モードを変更するには、カスタム設定文字列の--psm引数を上記のモードコードのいずれかに変更します。
設定を使用して数字のみを検出します。
設定を次のように変更することで数字のみを認識できます。
これは次の出力を与えます。あなたが見ることができるように、出力は同じではありません。規表現を使用します。
ホワイトリスト/ブラックリスト文字:
指定された画像から特定の文字だけを検出し、残りを無視したいとします。 次の設定を使用して、文字のホワイトリストを指定することができます(ここでは、aからzまでのすべての小文字のみを使用しています)。p>
そして、それは私たちにこの出力を与えます :/div>ブラックリスト文字:
いくつかの文字や式が間違いなくテキストに表示されないと確信している場合(ocrはブラックリスト文字の代わりに間違ったテキP>
出力 :
複数の言語のテキスト:ocr出力が必要な言語を指定するには、設定で-l LANG引数を使用します。langは、使用する言語の3文字コードです。次のようにLANGパラメータを変更することで、複数の言語で作業できます。
NB : -lパラメータに最初に指定された言語がプライマリ言語です。div>の出力:

残念ながらtesseractには、画像内のテキストの言語を自動的に検出する機能はありません。 別の解決策は、langdetectという別のpythonモジュールによって提供されています。
このモジュールは、画像を使用してテキストの言語を検出しませんが、言語を検出するために文字列入力が必要です。 これを行う最善の方法は、最初にtesseractを使用して、そこにあると感じる可能性のある言語でOCRテキストを取得し、langdetectを使用してOCRテキストに含まれている言語を見つけてから、見つかった言語でOCRを再度実行することです。
私たちは英語とポルトガル語であったと思ったテキストを持っていると言います。NB:複数の言語を持つ画像で、設定で指定された言語が間違っているか、まったく言及されていない場合、Tesseractはひどく実行されます。 これはlangdetectモジュールをかなり誤解させる可能性があります。TESSERACT OCRは非常に強力ですが、いくつかの制限があります。
tesseractの制限:
TESSERACT OCRは非常に強力ですが、いくつかの制限があります。OCRは、いくつかの利用可能な商業的なソリューションほど正確ではありません。
- は、部分的なオクルージョン、歪んだ遠近法、複雑な背景などのアーティファクトの影響を受ける画像ではうまくいきません。
- 手書きを認識することはできません。
- ちんぷんかんぷんを見つけて、これをOCR出力として報告するかもしれません。
- -l LANG引数で指定された言語以外の言語がドキュメントに含まれている場合、結果が悪くなる可能性があります。
- 文書の自然な読み取り順序を分析するのは必ずしも得意ではありません。 たとえば、文書に2つの列が含まれていることを認識できず、列間でテキストを結合しようとする可能性があります。
- 品質の悪いスキャンは、品質の悪いOCRを生成する可能性があります。
- どのフォントファミリのテキストが属しているかについての情報は公開しません。
結論:
Tesseractはきれいな文書をスキャンするのに最適であり、そのトレーニングは包括的だったので、かなり高い精度とフォントの変動が付属し
Tesseract4.0の最新リリースは、はるかに正確である深い学習ベースのOCRをサポートしています。 OCRエンジン自体は、特定のタイプのリカレントニューラルネットワーク(RNN)である長期短期記憶(LSTM)ネットワーク上に構築されています。
Leave a Reply