LDA 항목 모델링: 설명
배
항목 모델링은 프로세스의 식별 주제에 집의 문서를 제공하고 있습니다. 이는 검색 엔진,고객 서비스 자동화 및 문서의 주제를 아는 것이 중요한 다른 인스턴스에 유용 할 수 있습니다. 이 작업을 수행하는 방법에 대해가는 여러 가지 방법이 있지만 여기서는 하나를 설명 할 것입니다: 잠재 Dirichlet 할당(LDA).
알고리즘
LDA 형태의 자율 학습을 보는 문서로 가방의 말씀(ie 순서는 중요하지 않습니다). LDA 작품으로 첫 번째 열쇠를 만들고 가정하는 방법을 문서를 생성하여 주제의 설정한 다음 각 주제를 집의 단어입니다. 지금 당신은”확인 그래서 어떻게 주제를 찾을 수 있습니까?”그럼 대답은 간단합니다:그것은이 과정을 리버스 엔지니어링합니다. 이를 위해 각 문서 m 에 대해 다음을 수행합니다:
- 들이 있다고 가정해 봅시다 k 주제에 걸쳐 모든 문서의
- 이러한 배포 k 주제에 걸쳐 문서 m(이 메일로 알려져 있 α 및 수 있는 대칭 또는 비대칭,더 이상)지정하여 각각의 단어는 주제입니다.
- 문서 m 의 각 단어 w 에 대해 해당 주제가 잘못되었다고 가정하지만 다른 모든 단어에는 올바른 주제가 할당됩니다.
- 확률 적으로 단어 w 를 두 가지를 기반으로 주제 할당:
어떤 주제에 있는 문서 m
어떻게 여러 번 말씀 w 에 할당되었는 특정 주제에 걸쳐 모든 문서의(이 메일이라고 β,더 이상) - 이 과정을 반복 횟수를 위해 각각의 문서하고 당신은 끝났어!
모델
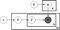
위에 무엇으로 알려진 격판덮개의 다이어그램이 LDA 모델:
α 는 문서를 항목의 분포,
β 은 당제 단어를 배포,
θ 은 항목의 유통에 대한 문서 m,
φ 은 단어를 배포에 대한 항목에서 k
z 에 대한 항목에서의 n 번째 단어에서 문서 m,그리고
w 은 특정 단어
꼬집 모델
에서 플레이트 모델에 위의 다이어그램 당신이 볼 수 있는 w 은 회색으로 표시됩니다. 이는 다른 변수가 잠재되어있는 동안 시스템에서 유일하게 관찰 가능한 변수이기 때문입니다. 이 때문에 모델을 조정하려면 엉망이 될 수있는 몇 가지가 있으며 아래에는 두 가지에 중점을 둡니다.
α 는 각 행이 문서이고 각 열이 주제를 나타내는 행렬입니다. 값에서 나는 행과 열 j 을 나타내는 방법을 가능성이 높 문서 나는 항목이 포함 j. 대칭 분포는 것을 의미하는 각 주제가 전체에 걸쳐 균등하게 분산되어 있는 문서는 비대칭 배급 호의 특정한 주제를 통해 다른 사람입니다. 이에 영향을 미치 시작하는 포인트는 모델의 사용될 수 있는 경우 거친의 아이디어는 어떻게 주제는 배 향상 결과입니다.
β 는 각 행이 주제를 나타내고 각 열이 단어를 나타내는 행렬입니다. 값에서 나는 행과 열 j 을 나타내는 방법을 가능성이 있는 화제가 포함되어 j. 일반적으로 각 단어를 고르게 분포되어내 같은 항목이 없는 항목으로 편견입니다. 이것은 특정 단어를 선호하기 위해 특정 주제를 편향시키기 위해 비록 악용 될 수 있습니다. 예를 들어 알고 있는 경우에 당신은 항목에 대해 사과 제품 그것은 도움이 될 수 있습니다 바이어스와 같은 단어”아이폰”및”이”중 하나에 대한 주제의 유도하기 위해서는 모델을 찾는쪽으로는 특정 주제입니다.
결론
이 문서는 아닙니다 full-blown LDA 토하지만,오히려주는 방법에 대한 개요를 LDA 모델 일 방법을 사용합니다. 거기에는 사용하기 쉽고 매우 효과적인 Gensim 과 같은 많은 구현이 있습니다. LDA 모델링을 위해 Gensim 라이브러리 사용에 대한 좋은 자습서는 여기에서 찾을 수 있습니다.
어떤 생각이 있거나 내가 놓친 것을 찾으십니까? 알려주세요!
행복한 주제 모델링!
Leave a Reply