OCR Python, OpenCV 및 PyTesseract

광학적인 문자를 인식(OCR) 변환의 이미지 형식으로 필기 또는 인쇄된 텍스트로 기계-로 인코딩된 텍스트,부터 스캔한 문서,사진,문서의 사진에서 현장(게시판에서는 풍경 사진)또는 텍스트에 겹쳐 이미지(자막에 텔레비전 방송).
OCR 은 일반적으로 가능한 한 정확하게 수행 할 수있는 하위 프로세스로 구성됩니다.

- 전처리
- 텍스트 검색
- 텍스트 인식
- 후처리
sub-프로세스의 변화에 따라 사용하는 사례는 하지만 이들은 generaly 는 데 필요한 단계를 수행하는 광학 문자인식입니다.
Tesseract OCR :
Tesseract 는 Open source text recognition(OCR)엔진으로 Apache2.0 라이센스하에 사용할 수 있습니다. 직접 사용하거나(프로그래머 용)API 를 사용하여 이미지에서 인쇄 된 텍스트를 추출 할 수 있습니다. 다양한 언어를 지원합니다. Tesseract 에는 내장 GUI 가 없지만 3rdParty 페이지에서 사용할 수있는 몇 가지가 있습니다. Tesseract 는 여기에서 찾을 수있는 래퍼를 통해 많은 프로그래밍 언어 및 프레임 워크와 호환됩니다. 그것과 함께 사용할 수 있습은 기존의 레이아웃 분석을 인식하는 텍스트 내에서 큰 문서 또는 그것과 함께 사용하실 수 있으로 외부에 텍스트 검출기를 인식하는 이미지에서 텍스트의 텍스트 라인.
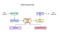
큐브 4.00 을 포함한 새로운 신경 네트워크 서브시스템으로 구성된 텍스트의 라인을 인식. 그것은 OCRopus 의 Python 기반 LSTM 구현에 기원을두고 있지만 C++에서 Tesseract 를 위해 재 설계되었습니다. 신경 네트워크 시스템에서 큐브 pre-날짜 TensorFlow 나와 호환되 그것으로 네트워크 설명 언어라는 변수 그래프 사양 언어(VGSL),는 것도 사용할 수 있 TensorFlow.
단일 문자를 포함하는 이미지를 인식하기 위해 일반적으로 Cnn(Convolutional Neural Network)을 사용합니다. 임의의 길이의 텍스트는 일련의 문자이며 이러한 문제는 RNNs 를 사용하여 해결되며 LSTM 은 인기있는 rnn 형태입니다. LSTM 에 대해 자세히 알아 보려면이 게시물을 읽으십시오.
Tesseract 는 C++에서 LSMT 의 포크 인 PYTHON 의 OCRopus 모델에서 개발되었으며 CLSTM 이라고합니다. CLSTM 은 C++에서 lstm 반복 신경망 모델의 구현입니다.
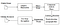
큐브 노력하였 코드리고를 추가하는 새로운 LSTM 모델입니다. 입력 이미지는 lstm 모델에 공급되고 출력을 제공하는 선으로 상자(직사각형)선으로 처리됩니다. 아래 이미지에서 우리는 어떻게 작동하는지 시각화 할 수 있습니다.

설치 큐브
설치 큐브 윈도우에서는 미리 컴파일된 바이너리 여기에 있습니다. “Path”환경 변수를 편집하고 tesseract 경로를 추가하는 것을 잊지 마십시오. Linux 또는 Mac 설치의 경우 몇 가지 명령으로 설치됩니다.
기본적으로 Tesseract 는 이미지를 세그먼트 화 할 때 텍스트 페이지를 기대합니다. 단지 작은 영역을 OCR 하려는 경우—psm 인수를 사용 하 여 다른 분할 모드를 시도 합니다. 여기에서 찾을 수있는 사용할 수있는 14 가지 모드가 있습니다. 기본적으로 Tesseract 는 페이지 세분화를 완전히 자동화하지만 방향 및 스크립트 감지는 수행하지 않습니다. 매개 변수를 지정하려면 다음을 입력하십시오.
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
또 하나의 중요한 인수 인 OCR 엔진 모드(oem)가 있습니다. Tesseract4 에는 레거시 Tesseract 엔진과 LSTM 엔진의 두 가지 OCR 엔진이 있습니다. -Oem 옵션을 사용하여 선택한 네 가지 작동 모드가 있습니다.0 입니다. 레거시 엔진 전용.
1. 신경망 lstm 엔진 만.
2 입니다. 레거시+LSTM 엔진.
3. 사용 가능한 것을 기반으로 기본값입니다.pytesseract 와 OpenCV 가있는 OCR:
Pytesseract 는 Tesseract-OCR 엔진의 래퍼입니다. 그것은 또한 유용한 독립으로 호출하는 스크립트 큐브,그것을 읽을 수 있는 모든 이미지 유형에 의해 지원되는 베개 Leptonica 상 라이브러리를 포함하여,jpeg,png,gif,bmp,tiff,및 다른 사람입니다. 파이썬 접근법에 대한 자세한 정보는 여기를 읽으십시오.
전처리를 위한 큐브:
우리는 것을 확인할 필요가 이미지가 적절한 사전 처리됩니다. 일정 수준의 정확성을 보장합니다.
여기에는 리 스케일링,이진화,노이즈 제거,데스 케 윙 등이 포함됩니다.
OCR 에 대한 이미지를 전처리하려면 다음 파이썬 함수 중 하나를 사용하거나 OpenCV 설명서를 따르십시오.
Our input is this image :

Here’s what we get :

Getting boxes around text :
다음 코드를 사용하여 pytesseradt 로 경계 상자 정보를 결정할 수 있습니다.
아래 스크립트는 OCR 동안 tesseract 에 의해 감지 된 각 문자에 대한 경계 상자 정보를 제공합니다.
하려는 경우 박스에는 단어 대신의 캐릭터,이 기능을image_to_dataimage_to_data기능과 출력 지정된 형식으로 pytesseractOutput.
우리는 tesseract 를 테스트하기 위해 아래의 샘플 영수증 이미지를 입력으로 사용할 것입니다.

코드는 다음과 같습니다:
출력은 사전 다음 키:

이전에,우리는 얻을 수 있는 각각의 단어를 감지,그들의 경계 상자 정보 에 텍스트와 자신감에 대한 점수를 각.
정보를 그래프로 표시할 수 있습니다 박스를 사용하여 아래 코드:
출력:

으로 우리는 볼 수 있습니다 큐브는 할 수 없을 감지하는 모든 텍스트 상자가 자신있게, 가난한 품질을 검사하고 작은 글꼴을 생산할 수 있습 품질 OCR 텍스트를 감지합니다. 또한 이미지의 품질을 향상시키기 위해 전처리가 수행되지 않았습니다.
텍스트 템플릿 일치(숫자 만 감지):
이미지에서 숫자 문자열 만있는 곳을 찾으려고하는 예를 들어보십시오. 여기서 우리의 템플릿은 적절한 경계 상자를 찾기 위해 OCR 결과와 일치하는 정규식 패턴이 될 것입니다. 이를 위해regeximage_to_data함수를 사용합니다.

페이지 세분화 모드 :
텍스트 페이지를 분석 할 수있는 몇 가지 방법이 있습니다. Tesseract api 는 작은 영역에서만 또는 다른 방향 등에서 OCR 을 실행하려는 경우 여러 페이지 분할 모드를 제공합니다.
다음은 tesseract 에 의해 지원되는 페이지 분할 모드 목록입니다.
0. Osd(Orientation and script detection)전용입니다.
1. OSD 로 자동 페이지 분할.
2 입니다. 자동 페이지 분할,하지만 OSD,또는 OCR.
3. 완전 자동 페이지 분할,하지만 OSD. (기본값)
4. 가변 크기의 단일 텍스트 열을 가정합니다.
5. 세로로 정렬 된 텍스트의 단일 균일 블록을 가정합니다.
6. 단일 균일 한 텍스트 블록을 가정합니다.
7. 이미지를 단일 텍스트 줄로 취급합니다.
8. 이미지를 한 단어로 취급하십시오.
9. 이미지를 원의 한 단어로 취급하십시오.10. 이미지를 단일 문자로 취급하십시오.
11. 스파 스 텍스트. 특별한 순서없이 가능한 한 많은 텍스트를 찾으십시오.
12. Osd 가있는 스파 스 텍스트.13. 원시 라인. 이미지를 하나의 텍스트 줄로 취급하여 큐브에 특정한 해킹을 우회합니다.
을 변경 페이지로 분할 모드를 변화--psm인수에서 설정 문자열을 언급 위의 모드 코드입니다.
탐지만 숫자를 사용하여 구성:
할 수 있습 숫자만을 변경하여 설정을 다음과 같다:
는 다음과 같이 출력됩니다.

당신이 볼 수 있듯이 출력되지 않은 사용하여 동일한 정규식으로 이루어져 있습니다.
화이트/블랙리스트 문자
말 너만을 감지하는 특정 문자에서 주어진 이미지하고 나머지는 무시합니다. 다음 구성을 사용하여 문자의 허용 목록을 지정할 수 있습니다(여기서는 a 에서 z 까지의 모든 소문자 만 사용했습니다).이 작업을 수행하려면 다음 단계를 따르고 다음 작업을 수행 할 수 있습니다. :

블랙리스트 문자:
확신하는 경우 어떤 문자나 표현실에 켜지지 않습니다 당신의 텍스트(OCR 반환됩니다 잘못된 텍스트를 블랙리스트 문자는 그렇지 않으면),블랙리스트할 수 있습니다 해당 문자를 사용하여 다음과 같은 config.
출력 :
여러 언어 텍스트:
을 지정할 필요한 언어의 OCR 출력에 사용하는-l LANG인 config 는 랑은 3 글자 코드에 대한 어떤 언어를 사용할 수 있습니다.
할 수 있는 작품으로 변경하여 여러 언어로 된 LANG 매개 변수는 이와 같이
NB : 먼저-l매개 변수에 지정된 언어가 기본 언어입니다.

그리고 당신은 다음과 같은 출력이 나타납니다:

불행하게도 큐브가 없는 기능을 감지하는 언어는 이미지의 텍스트는 자동으로 합니다. 대체 솔루션을 제공하는 또 다른 파이썬 모듈이라고langdetect를 통해 설치될 수 있는 핍 자세한 정보는 확인 이 링크를 클릭하십시오.
이 모듈을 다시 검색하지 않은 언어를 텍스트의 이미지를 사용하여 그 문자열을 입력하는 언어를 검색합니다. 최선의 방법은 이렇게 하려면 먼저 사용하는 큐브를 얻을 텍스트에는 어떤 언어를 느낄 수 있습니다 거기에 사용하는langdetect것을 찾는 언어가 포함되어 있습니다에서 텍스트와 그때 실행 OCR 다시 언어와 발견했다.
우리가 영어와 포르투가어로되어 있다고 생각한 텍스트가 있다고 가정 해보십시오.
NB:Tesseract 는 여러 언어가있는 이미지에서 config 에 지정된 언어가 잘못되었거나 전혀 언급되지 않은 경우 심하게 수행됩니다. 이것은 langdetect 모듈을 꽤 오도 할 수 있습니다.
Tesseract 제한 사항:
Tesseract OCR 은 매우 강력하지만 몇 가지 제한이 있습니다.
- OCR 은 일부 사용 가능한 상용 솔루션만큼 정확하지 않습니다.
- 는 부분 폐색,왜곡 된 원근감 및 복잡한 배경을 포함한 아티팩트의 영향을받는 이미지와는 잘 어울리지 않습니다.
- 필기를 인식 할 수 없습니다.
- 그것은 횡설수설을 발견하고 이것을 OCR 출력으로 신고 할 수 있습니다.
- 문서에-l LANG 인수에 주어진 언어 이외의 언어가 포함되어 있으면 결과가 좋지 않을 수 있습니다.
- 문서의 자연스러운 읽기 순서를 분석하는 데 항상 좋은 것은 아닙니다. 예를 들어,그것은 실패할 수 있다는 것을 인식이 포함된 문서 두 개의 열을 수 있습에 참여 하려고 텍스트를 통해 열이 있습니다.
- 품질이 좋지 않은 스캔은 품질이 좋지 않은 OCR 을 생성 할 수 있습니다.
- 글꼴 패밀리 텍스트가 속한 것에 대한 정보를 노출하지 않습니다.
Conclusion:
큐브는 완벽한 스캔을 위해 깨끗한 문서와 함께 매우 높은 정확성 및 글꼴 변동성을 이 교육은 포괄적이다.
Tesseract4.0 의 최신 릴리스는 훨씬 더 정확한 딥 러닝 기반 OCR 을 지원합니다. OCR 엔진 자체는 특정 유형의 재발 성 신경망(RNN)인 긴 단기 기억(Lstm)네트워크를 기반으로합니다.
Leave a Reply