Lda Topic Modeling: o explicație
fundal
modelarea subiectului este procesul de identificare a subiectelor într-un set de documente. Acest lucru poate fi util pentru motoarele de căutare, automatizarea serviciilor pentru clienți și orice altă instanță în care cunoașterea subiectelor documentelor este importantă. Există mai multe metode de a merge despre a face acest lucru, dar aici voi explica unul: Alocarea latentă Dirichlet (LDA).
algoritmul
LDA este o formă de învățare nesupravegheată care vede documentele ca pungi de cuvinte (adică ordinea nu contează). LDA funcționează făcând mai întâi o presupunere cheie: modul în care a fost generat un document a fost prin alegerea unui set de subiecte și apoi pentru fiecare subiect alegerea unui set de cuvinte. Acum s-ar putea să vă întrebați „OK, deci cum găsește subiecte?”Ei bine, răspunsul este simplu: se inversa ingineri acest proces. Pentru a face acest lucru, face următoarele pentru fiecare document m:
- Să presupunem că există subiecte k în toate documentele
- distribuiți aceste subiecte k în documentul M (această distribuție este cunoscută sub numele de Irak și poate fi simetrică sau asimetrică, mai multe despre aceasta mai târziu) atribuind fiecărui cuvânt un subiect.
- pentru fiecare cuvânt w din documentul m, presupuneți că subiectul său este greșit, dar fiecărui alt cuvânt i se atribuie subiectul corect.
- atribuie probabilistic cuvânt w un subiect bazat pe două lucruri:
– Ce subiecte sunt în documentul m
– De câte ori word w a fost atribuit un anumit subiect în toate documentele (această distribuție se numește ecuot, mai multe despre acest lucru mai târziu) - repetați acest proces de mai multe ori pentru fiecare document și ați terminat!
Modelul
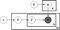
de mai sus este ceea ce este cunoscut ca o diagramă placă a unui model Lda unde:
XV este distribuția pe subiect a documentului,
XV este distribuția pe subiect a cuvântului,
XV este distribuția pe subiect a documentului m,
XV este distribuția cuvântului pentru subiectul k,
z este subiectul pentru al n-lea cuvânt din documentul m și
w este cuvântul specific
modificând modelul
în diagrama modelului plăcii de mai sus, puteți vedea că w este gri. Acest lucru se datorează faptului că este singura variabilă observabilă din sistem, în timp ce celelalte sunt latente. Din această cauză, pentru a modifica modelul, există câteva lucruri cu care vă puteți încurca și mai jos mă concentrez pe două.
XV este o matrice în care fiecare rând este un document și fiecare coloană reprezintă un subiect. O valoare în rândul i și coloana j reprezintă cât de probabil documentul I conține subiectul j. o distribuție simetrică ar însemna că fiecare subiect este distribuit uniform în întregul document, în timp ce o distribuție asimetrică favorizează anumite subiecte față de altele. Acest lucru afectează punctul de plecare al Modelului și poate fi utilizat atunci când aveți o idee aproximativă despre modul în care subiectele sunt distribuite pentru a îmbunătăți rezultatele.
XV este o matrice în care fiecare rând reprezintă un subiect și fiecare coloană reprezintă un cuvânt. O valoare în rândul i și coloana j reprezintă cât de probabil că subiectul I conține cuvântul j. de obicei, fiecare cuvânt este distribuit uniform pe întregul subiect, astfel încât niciun subiect să nu fie părtinitor față de anumite cuvinte. Acest lucru poate fi exploatat, deși, în scopul de a părtinire anumite subiecte pentru a favoriza anumite cuvinte. De exemplu, dacă știți că aveți un subiect despre produsele Apple, poate fi util să părtiniți cuvinte precum „iphone” și „ipad” pentru unul dintre subiecte, pentru a împinge modelul spre găsirea acelui subiect.
concluzie
Acest articol nu este menit să fie un tutorial Lda complet, ci mai degrabă să ofere o imagine de ansamblu asupra modului în care funcționează modelele LDA și cum să le folosească. Există multe implementări acolo, cum ar fi Gensim, care sunt ușor de utilizat și foarte eficiente. Un tutorial bun despre utilizarea bibliotecii Gensim pentru modelarea LDA poate fi găsit aici.
aveți gânduri sau găsiți ceva ce mi-a scăpat? Anunță-mă!
modelare subiect fericit!
Leave a Reply