recunoașterea optică a caracterelor (OCR) este conversia imaginilor textului tastat, scris de mână sau tipărit în text codificat de mașină, fie dintr-un document scanat, o fotografie a unui document, o fotografie dintr-o scenă (panouri publicitare într-o fotografie peisaj) sau dintr-un text suprapus pe o imagine (subtitrări la o emisiune de televiziune).
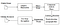
OCR constă în general din subprocese pentru a efectua cât mai exact posibil.
pre-procesare
detectarea textului
recunoașterea textului
post-procesare
subprocesele pot varia, desigur, în funcție de cazul de utilizare, dar acestea sunt în general pașii necesari pentru a efectua recunoașterea optică a caracterelor.
Tesseract OCR :Tesseract este un motor open source de recunoaștere a textului (OCR), disponibil sub Licența Apache 2.0. Poate fi folosit direct sau (pentru programatori) folosind un API pentru a extrage text tipărit din imagini. Aceasta susține o mare varietate de limbi. Tesseract nu are o interfață grafică încorporată, dar există mai multe disponibile de pe pagina 3rdparty. Tesseract este compatibil cu multe limbaje de programare și cadre prin ambalaje care pot fi găsite aici. Poate fi utilizat cu analiza de aspect existentă pentru a recunoaște textul într-un document mare sau poate fi utilizat împreună cu un detector de text extern pentru a recunoaște textul dintr-o imagine a unei singure linii de text.
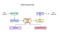
fluxul de proces OCR din o postare pe blog
tesseract 4.00 include un nou subsistem de rețea neuronală configurat ca un recognizer de linie text. Își are originile în implementarea Lstm bazată pe Python a OCRopus, dar a fost reproiectată pentru Tesseract în c++. Sistemul de rețea neuronală din Tesseract pre-datează TensorFlow, dar este compatibil cu acesta, deoarece există un limbaj de descriere a rețelei numit Variable Graph Specification Language (Vgsl), care este disponibil și pentru TensorFlow.
pentru a recunoaște o imagine care conține un singur caracter, folosim de obicei o rețea neuronală convoluțională (CNN). Textul de lungime arbitrară este o secvență de caractere, iar astfel de probleme sunt rezolvate folosind RNNs și LSTM este o formă populară de RNN. Citiți această postare pentru a afla mai multe despre LSTM.
Tesseract dezvoltat din modelul OCRopus în Python, care a fost o furculiță a unui LSMT în C++, numit CLSTM. CLSTM este o implementare a modelului de rețea neuronală recurentă lstm în c++.
Tesseract 3 OCR proces din hârtie
tesseract a fost un efort de curățare a codului și adăugarea unui nou model lstm. Imaginea de intrare este procesată în cutii (dreptunghi) linie cu linie alimentând modelul LSTM și dând ieșire. În imaginea de mai jos putem vizualiza cum funcționează.
cum Tesseract folosește prezentarea modelului lstm
instalarea tesseract
instalarea Tesseract pe Windows este ușoară cu binarele precompilate găsite aici. Nu uitați să editați variabila de mediu „path” și să adăugați calea tesseract. Pentru instalarea Linux sau Mac este instalat cu câteva comenzi.
în mod implicit, Tesseract așteaptă o pagină de text atunci când segmentează o imagine. Dacă doriți doar să OCR o regiune mică, încercați un alt mod de segmentare, folosind argumentul — psm. Există 14 moduri disponibile care pot fi găsite aici. În mod implicit, Tesseract automatizează complet segmentarea paginii, dar nu efectuează orientarea și detectarea scriptului. Pentru a specifica parametrul, tastați următoarele:
0 Orientation and script detection (OSD) only. 1 Automatic page segmentation with OSD. 2 Automatic page segmentation, but no OSD, or OCR. 3 Fully automatic page segmentation, but no OSD. (Default) 4 Assume a single column of text of variable sizes. 5 Assume a single uniform block of vertically aligned text. 6 Assume a single uniform block of text. 7 Treat the image as a single text line. 8 Treat the image as a single word. 9 Treat the image as a single word in a circle. 10 Treat the image as a single character. 11 Sparse text. Find as much text as possible in no particular order. 12 Sparse text with OSD. 13 Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.
există, de asemenea, un argument mai important, modul motor OCR (oem). Tesseract 4 are două motoare OCR — Legacy Tesseract engine și lstm engine. Există patru moduri de funcționare alese folosind opțiunea-oem.
0. Numai motorul Legacy. 1. Numai motorul LSTM al rețelelor neuronale. 2. Legacy + motoare LSTM. 3. Implicit, pe baza a ceea ce este disponibil.
OCR cu Pytesseract și OpenCV:
Pytesseract este un înveliș pentru motorul Tesseract-OCR. De asemenea, este util ca un script de invocare stand-alone pentru tesseract, deoarece poate citi toate tipurile de imagini susținute de bibliotecile de imagini Pillow și leptonica, inclusiv jpeg, png, gif, bmp, tiff și altele. Mai multe informații despre abordarea Python citiți aici.
preprocesare pentru Tesseract:
trebuie să ne asigurăm că imaginea este pre-procesată corespunzător. pentru a asigura un anumit nivel de precizie.
aceasta include redimensionarea, binarizare, eliminarea zgomotului, deskewing, etc.
pentru a preprocesa imaginea pentru OCR, utilizați oricare dintre următoarele funcții python sau urmați documentația OpenCV.
Our input is this image :
Here’s what we get :
Getting boxes around text :
putem determina informațiile caseta de încadrare cu PyTesseradt folosind următorul cod.
scriptul de mai jos vă va oferi informații despre caseta de delimitare pentru fiecare caracter detectat de tesseract în timpul OCR.
dacă doriți casete în jurul cuvintelor în loc de caractere, funcția image_to_data va fi utilă. Puteți utiliza funcția image_to_data cu tipul de ieșire specificat cu pytesseract Output.
vom folosi imaginea de primire eșantion de mai jos ca intrare pentru a testa tesseract .
iată codul:
ieșirea este un dicționar cu următoarele taste:
folosind acest dicționar, putem obține fiecare cuvânt detectat, informațiile lor cutie de încadrare, textul în ele și scorurile de încredere pentru fiecare.
puteți trasa casetele folosind codul de mai jos :
ieșirea:
după cum putem vedea, tesseract nu este capabil să detecteze cu încredere toate casetele de text, scanările de calitate slabă și fonturile mici pot produce detectarea textului OCR de calitate slabă. De asemenea, nu s-au făcut preprocesări pentru a îmbunătăți calitatea imaginii.
potrivire șablon de Text ( detecta numai cifre):
ia exemplul de a încerca să găsească în cazul în care un șir de numai cifre este într-o imagine. Aici șablonul nostru va fi un model de Expresie regulat pe care îl vom potrivi cu rezultatele OCR pentru a găsi casetele de încadrare corespunzătoare. Vom folosi modulul regex și funcția image_to_data pentru aceasta.
moduri de segmentare a paginilor :
există mai multe moduri în care o pagină de text poate fi analizată. Api-ul tesseract oferă mai multe moduri de segmentare a paginilor dacă doriți să rulați OCR doar pe o regiune mică sau în orientări diferite etc.
Iată o listă a modurilor de segmentare a paginilor acceptate de tesseract:
0. Orientare și detectare script (OSD) numai. 1. Segmentarea automată a paginilor cu OSD. 2. Segmentarea automată a paginii, dar fără OSD sau OCR. 3. Segmentarea paginii complet automată, dar fără OSD. (Implicit) 4. Să presupunem o singură coloană de text de dimensiuni variabile. 5. Să presupunem un singur bloc uniform de text aliniat vertical. 6. Să presupunem un singur bloc uniform de text. 7. Tratați imaginea ca o singură linie de text. 8. Tratează imaginea ca pe un singur cuvânt. 9. Tratați imaginea ca un singur cuvânt într-un cerc. 10. Tratați imaginea ca un singur caracter. 11. Text rar. Găsiți cât mai mult text posibil, în nici o ordine specială. 12. Text rar cu OSD. 13. Linie brută. Tratați imaginea ca o singură linie de text, ocolind hack-urile care sunt specifice Teseractului.
pentru a schimba modul de segmentare a paginii, schimbați argumentul--psm din șirul de configurare personalizat la oricare dintre codurile de mod menționate mai sus.
detectați numai cifre utilizând configurația:
puteți recunoaște numai cifre schimbând configurația la următoarea:
care dă următoarea ieșire.
după cum puteți vedea, ieșirea nu este aceeași folosind Regex .
whitelisting/blacklisting characters:
spuneți că doriți doar să detectați anumite caractere din imaginea dată și să ignorați restul. Puteți specifica lista albă de caractere (aici, am folosit toate caracterele minuscule de la A la z numai) utilizând următoarea configurare.
și ne dă această ieșire :
blacklisting letters:
dacă sunteți sigur că unele caractere sau expresii cu siguranță nu vor apărea în textul dvs. (OCR va returna textul greșit în locul caracterelor pe lista neagră altfel), puteți lista neagră acele caractere utilizând următoarea configurare.
ieșire :
text în mai multe limbi:
pentru a specifica limba în care aveți nevoie de ieșirea OCR, utilizați argumentul -l LANG în config unde Lang este codul de 3 litere pentru ce limbă doriți să utilizați.
puteți lucra cu mai multe limbi schimbând parametrul LANG ca atare:
NB : Limba specificată mai întâi la parametrul-l este limba principală.
și veți obține următoarea ieșire:
Din păcate, tesseract nu are o caracteristică pentru a detecta limba textului într-o imagine în mod automat. O soluție alternativă este furnizată de un alt modul python numit langdetect care poate fi instalat prin pip pentru mai multe informații verificați acest link.
Acest modul din nou, nu detectează limba textului folosind o imagine, dar are nevoie de intrare șir pentru a detecta limba de la. Cel mai bun mod de a face acest lucru este de a utiliza mai întâi tesseract pentru a obține Text OCR în orice limbi s-ar putea simți sunt acolo, folosind langdetect pentru a găsi ce limbi sunt incluse în textul OCR și apoi executați din nou OCR cu limbile găsite.
să spunem că avem un text pe care l-am crezut în engleză și portugheză.
NB: Tesseract funcționează prost atunci când, într-o imagine cu mai multe limbi, limbile specificate în configurare sunt greșite sau nu sunt menționate deloc. Acest lucru poate induce în eroare modulul langdetect destul de mult.
limitări Tesseract:
Tesseract OCR este destul de puternic, dar are unele limitări.
OCR nu este la fel de precis ca unele soluții comerciale disponibile .
nu se descurcă bine cu imaginile afectate de artefacte, inclusiv ocluzia parțială, perspectiva distorsionată și fundalul complex.
nu este capabil să recunoască scrisul de mână.
se poate găsi păsărească și să raporteze acest lucru ca ieșire OCR.
dacă un document conține limbi în afara celor date în argumentele-l LANG, rezultatele pot fi slabe.
nu este întotdeauna bun la analizarea ordinii naturale de citire a documentelor. De exemplu, este posibil să nu recunoască faptul că un document conține două coloane și poate încerca să asocieze textul între coloane.
scanările de calitate slabă pot produce OCR de calitate slabă.
nu expune informații despre ce aparține textul familiei de fonturi.
concluzie:
Tesseract este perfect pentru scanarea documentelor curate și vine cu o precizie destul de mare și variabilitatea fontului, deoarece formarea sa a fost cuprinzătoare.
cea mai recentă versiune a Tesseract 4.0 acceptă OCR bazat pe învățare profundă, care este semnificativ mai precis. Motorul OCR în sine este construit pe o rețea de memorie pe termen scurt (Lstm), care este un tip particular de rețea neuronală recurentă (RNN).












Leave a Reply