Lda Topic Modeling: an Explanation
div>
background
topic modeling on dokumenttien aiheiden tunnistamisprosessi. Tästä voi olla hyötyä hakukoneille, asiakaspalveluautomaatiolle ja muille instansseille, joissa dokumenttien aiheiden tunteminen on tärkeää. On olemassa useita menetelmiä mennä noin tehdä tämä, mutta tässä selitän yksi: Piilevä Dirichlet ’ n allokaatio (Lda).
algoritmi
Lda on valvomattoman oppimisen muoto, joka pitää asiakirjoja sanasäkkeinä (eli järjestyksellä ei ole väliä). LDA toimii tekemällä ensin keskeisen olettamuksen: tapa, jolla dokumentti luotiin, oli poimimalla joukko aiheita ja sitten kullekin aiheelle poimimalla joukko sanoja. Nyt saatat kysyä ” ok joten miten se löytää aiheita?”No vastaus on yksinkertainen:se kääntää insinöörit tämän prosessin. Voit tehdä tämän se tekee seuraavat kunkin asiakirjan m:
- oleta, että kaikissa asiakirjoissa on K-aiheita
- Jaa nämä k-aiheet koko asiakirjaan m (tämä jakauma tunnetaan nimellä α ja se voi olla symmetrinen tai epäsymmetrinen, tästä tarkemmin myöhemmin) osoittamalla jokaiselle sanalle aihe.
- jokaiselle sanalle w asiakirjassa m oletetaan, että sen aihe on väärä, mutta joka toiselle sanalle annetaan oikea aihe.
- todennäköisyyslaskennan mukaan sana w on aihe, joka perustuu kahteen asiaan:
– mitkä aiheet ovat dokumentissa m
– kuinka monta kertaa sana w on annettu tietylle aiheelle kaikissa dokumenteissa (tätä jakaumaa kutsutaan nimellä β, tästä lisää myöhemmin) - Toista tämä prosessi useita kertoja jokaiselle dokumentille ja olet valmis!
malli
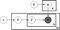
figcaption>tasoitettu Lda: sta https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
edellä on niin sanottu Lda-mallin levykaavio, jossa:
α on dokumentin aihejakauma,
β on aihekohtainen sanajakauma,
θ on dokumentin m aihejakauma,
φ On aiheen k sanajakauma,
z on dokumentin m n: nnen sanan aihe ja
w on nimenomainen sana
mallin muokkaaminen
yllä olevasta levymallikaaviosta näkyy, että w on harmaantunut. Tämä johtuu siitä, että se on ainoa havaittava muuttuja järjestelmässä muiden ollessa piileviä. Tämän vuoksi, nipistää malli on muutamia asioita, voit sotkea ja alla keskityn kahteen.
α on matriisi, jossa jokainen rivi on dokumentti ja jokainen sarake edustaa aihetta. Rivin i ja sarakkeen J arvo kuvaa sitä, kuinka todennäköisesti asiakirja i sisältää aiheen J. symmetrinen jakauma tarkoittaisi, että jokainen aihe jakautuu tasaisesti koko asiakirjaan, kun taas epäsymmetrinen jakauma suosii tiettyjä aiheita toisten sijaan. Tämä vaikuttaa mallin lähtökohtaan ja sitä voidaan käyttää, kun on karkea käsitys siitä, miten aiheet jaetaan tulosten parantamiseksi.
β on matriisi, jossa jokainen rivi edustaa aihetta ja jokainen sarake sanaa. Rivin i ja sarakkeen J arvo kuvaa sitä, kuinka todennäköistä on, että aihe I sisältää sanan j. yleensä jokainen sana jakautuu tasaisesti koko aihealueelle siten, että mikään aihe ei ole puolueellinen tiettyjä sanoja kohtaan. Tätä voidaan kuitenkin käyttää hyväksi, jotta tiettyjä aiheita voidaan suosia tiettyjä sanoja. Esimerkiksi jos tiedät, että sinulla on aihe Applen tuotteista, voi olla hyödyllistä vinouttaa sanoja, kuten ”iphone” ja ”ipad”, yhdelle aiheista, jotta mallia voidaan työntää kohti kyseisen aiheen löytämistä.
johtopäätös
tämän artikkelin ei ole tarkoitus olla täysimittainen LDA-opetusohjelma, vaan antaa yleiskuva siitä, miten LDA-mallit toimivat ja miten niitä käytetään. On olemassa monia toteutuksia siellä, kuten Gensim, jotka ovat helppokäyttöisiä ja erittäin tehokkaita. Hyvä opetusohjelma gensim-kirjaston käyttämisestä LDA-mallinnukseen löytyy täältä.
Have any thoughts or find something I missed? Kerro minulle!
onnellinen aihe mallintaminen!
Leave a Reply