OCR Pythonin, OpenCV: n ja Pytesseraktin kanssa

/div>
optinen merkintunnistus (OCR) on tyypitettyjen, käsin kirjoitettujen tai painettujen tekstien muuntamista koneellisesti koodatuksi tekstiksi joko skannatusta asiakirjasta, asiakirjasta otetusta valokuvasta, kohtauksesta otetusta valokuvasta (mainostaulut maisemakuvassa) tai kuvan päälle asetetusta tekstistä (tekstitys televisiolähetyksessä).
OCR koostuu yleensä osaprosesseista, jotka suoritetaan mahdollisimman tarkasti.

- esikäsittely
- tekstintunnistus
- tekstintunnistus
- jälkikäsittely
osaprosessit voivat toki vaihdella käyttötapauksesta riippuen, mutta nämä ovat yleensä optisen merkintunnistuksen suorittamiseen tarvittavia vaiheita.
Tesseract OCR :
Tesseract on avoimen lähdekoodin tekstintunnistus (OCR) – moottori, joka on saatavilla Apache 2.0-lisenssillä. Sitä voidaan käyttää suoraan, tai (ohjelmoijille) API: n avulla poimia Tulostettua tekstiä kuvista. Se tukee monenlaisia kieliä. Tesseractissa ei ole sisäänrakennettua käyttöliittymää, mutta 3rdParty-sivulta on saatavilla useita. Tesseract on yhteensopiva monien ohjelmointikielten ja kehysten kanssa kääreiden kautta, jotka löytyvät täältä. Sitä voidaan käyttää olemassa olevan layout analysis tunnistaa tekstin sisällä suuri asiakirja, tai sitä voidaan käyttää yhdessä ulkoisen tekstin ilmaisin tunnistaa tekstiä kuvan yhden tekstirivin.
tesseract 4.00 sisältää tekstirivin tunnistajaksi konfiguroidun uuden neuroverkon alijärjestelmän. Se on saanut alkunsa Okropuksen Python-pohjaisesta Lstm-toteutuksesta, mutta se on uudistettu Tesseractia varten C++ – kielellä. Tesseractin neuroverkkojärjestelmä edeltää TensorFlow ’ta, mutta on sen kanssa yhteensopiva, sillä TensorFlow’ lle on saatavilla myös verkon kuvauskieli Variable Graph Specification Language (Vgsl).
tunnistaaksemme kuvan, joka sisältää yhden merkin, käytämme tyypillisesti Convolutionaalista neuroverkkoa (CNN). Teksti mielivaltainen pituus on sarja merkkejä, ja tällaiset ongelmat ratkaistaan käyttämällä RNNs ja LSTM on suosittu muoto RNN. Lue tämä viesti lisätietoja LSTM.
Tesseract kehittyi Pythonin OCRopus-mallista, joka oli C++: n lsmt: n haarukka eli clstm. CLSTM on lstm: n uusiutuvan neuroverkkomallin toteutus C++: ssa.
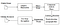
tesseract oli pyrkimys koodin puhdistamiseen ja uuden lstm-mallin lisäämiseen. Syötekuva käsitellään laatikoissa (suorakulmio) viivalla syöttämällä lstm-malliin ja antamalla ulostulo. Alla olevassa kuvassa voimme visualisoida, miten se toimii.

Tesseractin asentaminen Windowsiin on helppoa täältä löytyvien esikäännettyjen binäärien avulla. Älä unohda muokata ”polku” ympäristömuuttuja ja lisätä tesseract polku. Linux – tai Mac-asennukseen se asennetaan muutamalla komennolla.
oletuksena Tesseract odottaa sivun verran tekstiä, kun se segmentoi kuvan. Jos olet vain etsivät OCR pieni alue, kokeile eri segmentointi tilassa, käyttäen-psm argumentti. Tarjolla on 14 tilaa, jotka löytyvät täältä. Oletusarvoisesti Tesseract automatisoi sivun segmentoinnin täysin, mutta ei suorita orientaatiota ja skriptien tunnistusta. Parametrin määrittelemiseksi on kirjoitettava seuraava:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
on myös yksi tärkeämpi argumentti, OCR-moottoritila (oem). Tesseract 4: ssä on kaksi OCR — moottoria: Legacy Tesseract-moottori ja LSTM-Moottori. On neljä toimintatilaa valitaan käyttämällä — oem-vaihtoehtoa.
0. Vain Legacy engine.
1. Vain hermoverkkoja.
2. Legacy + LSTM-moottorit.
3. Oletus, joka perustuu siihen, mitä on saatavilla.
OCR Pytesseraktilla ja OpenCV: llä:
Pytesseract on Tesseract-OCR-Moottorin kääre. Se on myös hyödyllinen stand-alone invocation script to tesseract, koska se voi lukea kaikki kuvatyypit tukee tyynyn ja Leptonica kuvantaminen kirjastot, kuten jpeg, png, gif, bmp, tiff, ja muut. Lisätietoja Python lähestymistapa lue täältä.
Tesseraktin esikäsittely:
on varmistettava, että kuva on asianmukaisesti esikäsitelty. tietyn tarkkuuden varmistamiseksi.
Tähän sisältyy rescaling, binarisointi, kohinan poisto, deskewing jne.
ESIPROSESSOIDAKSESI kuvan OCR: lle, käytä jotain seuraavista python-funktioista tai seuraa OpenCV-ohjeistusta.
Our input is this image :

Here’s what we get :

Getting boxes around text :
voimme määrittää bounding box-tiedot Pytesseradtin avulla seuraavan koodin avulla.
alla oleva komentosarja antaa sinulle rajausruututiedot jokaisesta Tesseractin OCR: n aikana havaitsemasta merkistä.
Jos haluaa laatikoita sanojen ympärille merkkien sijaan, funktio image_to_data tulee tarpeeseen. Voit käyttää image_to_data funktiota, jonka tulostyyppi on määritelty pytesseraktilla Output.
käytämme alla olevaa otoksen vastaanottokuvaa syötteenä testataksemme tesseraktia .

tässä on koodi:
tuloste on sanakirja, jossa on seuraavat avaimet:
tämän sanakirjan avulla saamme jokaisen havaitun sanan, niiden rajauslaatikon tiedot, niissä olevan tekstin ja kunkin Luottamuspisteet.
ruudut voi piirtää alla olevalla koodilla :
lähtö:

kuten näemme, tesseract ei pysty havaitsemaan kaikkia tekstiruutuja luotettavasti, heikkolaatuiset skannaukset ja pienet fontit voivat tuottaa heikkolaatuisen OCR-tekstin tunnistuksen. Myöskään kuvan laadun parantamiseksi ei ole tehty esikäsittelyä.
tekstimallien vastaavuus (tunnista vain numeroita ):
esimerkiksi yritetään selvittää, missä kuvassa on vain numeromerkkijono. Tässä meidän malli on säännöllinen lauseke kuvio, että me vastaavat meidän OCR tulokset löytää sopiva rajaavat laatikot. Tähän käytetään regex modulia ja image_to_data funktiota.

sivun segmentointitilat :
sivun tekstiä voi analysoida monella tavalla. Tesseract api tarjoaa useita sivun segmentointitiloja, jos haluat ajaa OCR: ää vain pienellä alueella tai eri suuntauksissa jne.
tässä on lista tuetuista sivun segmentointitiloista Tesseraktin mukaan:
0. Vain Orientation and script detection (OSD).
1. Automaattinen sivun segmentointi OSD: llä.
2. Automaattinen sivun segmentointi, mutta ei OSD: tä tai OCR: ää.
3. Täysin automaattinen sivun segmentointi, mutta ei OSD. (Oletus)
4. Oletetaan yhden sarakkeen tekstiä vaihtelevan kokoisia.
5. Oletetaan yksi yhtenäinen lohko pystysuorassa linjassa tekstiä.
6. Oletetaan yksi yhtenäinen lohko tekstiä.
7. Käsittele kuva yhtenä tekstirivinä.
8. Käsittele kuva yhtenä sanana.
9. Käsittele kuvaa yhtenä sanana ympyrässä.
10. Käsittele kuva yhtenä merkkinä.
11. Niukasti tekstiä. Etsi niin paljon tekstiä kuin mahdollista missään tietyssä järjestyksessä.
12. Harva teksti OSD: llä.
13. Raaka linja. Käsittele kuvaa yhtenä tekstirivinä, ohittaen tesseraktikohtaiset hakkeroinnit.
muuttaaksesi sivun segmentointitilaa, muuta --psm argumentti mukautetussa asetusmerkkijonossa johonkin edellä mainituista tilakoodeista.
tunnista vain numeroita konfiguraatiolla:
voit tunnistaa vain numeroita muuttamalla asetusta seuraavasti:
, joka antaa seuraavan tulosteen.

kuten näet, tuloste ei ole sama regexillä .
Whitelisting/Blacklisting-merkit:
sano, että haluat vain havaita tietyt merkit annetusta kuvasta ja jättää muut huomiotta. Voit määrittää valkoiselle listalle merkkejä (tässä, olemme käyttäneet kaikkia pieniä merkkejä a-z vain) käyttämällä seuraavaa config.
ja se antaa meille tämän tulosteen :

mustalle listalle kirjeet:
Jos olet varma, että joitakin merkkejä tai ilmaisuja ei varmasti löydy tekstistäsi (OCR palauttaa väärän tekstin mustalle listalle joutuneiden merkkien tilalle muuten), voit mustalle listalle nämä merkit käyttämällä seuraavaa asetusta.
Lähtö :

usean kielen Teksti:
määrittääksesi kielen, jolla tarvitset OCR-tulosteen, käytä -l LANGargumenttia asetuksissa, joissa Lang on 3-kirjaiminen koodi sille, mitä kieltä haluat käyttää.
useiden kielten kanssa voi työskennellä muuttamalla LANG-parametria sellaisenaan:
NB : -l parametrille ensin määritelty kieli on ensisijainen kieli.

ja saat seuraavan lähdön:

/div>
valitettavasti tesseractissa ei ole ominaisuutta, joka tunnistaisi kuvan tekstin kielen automaattisesti. Vaihtoehtoisen ratkaisun tarjoaa toinen python-moduuli nimeltä langdetect, joka voidaan asentaa pip: n kautta lisätietoja Katso tästä linkistä.
tämäkään moduuli ei tunnista tekstin kieltä kuvan avulla, vaan tarvitsee merkkijonosyötteen tunnistaakseen kielen. Paras tapa tehdä tämä on ensin Tesseractin avulla saada OCR-teksti millä tahansa kielellä, mitä mahdollisesti tunnet siellä olevan, käyttäen langdetect löytää mitä kieliä OCR-tekstiin sisältyy ja ajaa sitten OCR uudelleen löydetyillä kielillä.
sano, että meillä on teksti, jonka luulimme olevan englanniksi ja portugaliksi.
HUOM: Tesseract toimii huonosti, kun kuvassa, jossa on useita kieliä, asetuksissa määritellyt kielet ovat vääriä tai niitä ei mainita lainkaan. Tämä voi myös johtaa langdetect-moduulia harhaan.
Tesseract limitations:
Tesseract OCR on melko voimakas, mutta sillä on joitakin rajoituksia.
- OCR ei ole yhtä tarkka kuin jotkin saatavilla olevat kaupalliset ratkaisut .
- ei pärjää kuville, joihin vaikuttavat artefaktit kuten osittainen okkluusio, vääristynyt perspektiivi ja monimutkainen tausta.
- se ei kykene tunnistamaan käsialaa.
- se saattaa löytää siansaksaa ja ilmoittaa tämän OCR-ulostulona.
- Jos asiakirja sisältää-L LANG-argumenteissa annettujen kielten ulkopuolisia kieliä, tulokset voivat olla huonoja.
- se ei ole aina hyvä analysoimaan asiakirjojen luonnollista lukujärjestystä. Se voi esimerkiksi olla tunnistamatta, että asiakirja sisältää kaksi saraketta, ja se voi yrittää liittää tekstiä sarakkeiden yli.
- heikkolaatuiset skannaukset saattavat tuottaa huonolaatuisia OCR: iä.
- siinä ei paljasteta tietoa siitä, mihin kirjasinperheeseen teksti kuuluu.
Conclusion:
Tesseract on täydellinen puhtaiden dokumenttien skannaamiseen ja sen tarkkuus ja kirjasinvaihtelu on melko suurta, koska sen koulutus oli kattava.
Tesseract 4.0: n uusin julkaisu tukee syväoppimiseen perustuvaa OCR: ää, joka on huomattavasti tarkempi. OCR-moottori itsessään on rakennettu pitkän lyhytkestoisen muistin (Lstm) verkkoon, joka on tietyntyyppinen toistuva neuroverkko (RNN).
Leave a Reply