LDA Téma Modellezés: Magyarázat
Háttér
a Témakör modellezés a folyamat azonosítása témákat a dokumentumot. Ez hasznos lehet a keresőmotorok, az ügyfélszolgálat automatizálása, valamint bármely más esetben, ahol a dokumentumok témáinak ismerete fontos. Több módszer is van erre, de itt elmagyarázom az egyiket: Látens Dirichlet allokáció (LDA).
az algoritmus
az LDA a felügyelet nélküli tanulás egyik formája, amely a dokumentumokat zsák szavaknak tekinti (azaz a rend nem számít). Az LDA úgy működik, hogy először kulcsfontosságú feltételezést tesz: a dokumentum létrehozásának módja az volt, hogy egy sor témát választott, majd minden témához egy sor szót választott. Most lehet, hogy azt kérdezi: “ok, tehát hogyan találja meg a témákat?”Nos, a válasz egyszerű: megfordítja ezt a folyamatot. Ehhez ez nem a következő minden dokumentum m:
- tegyük fel, hogy az összes dokumentumban vannak k témák
- terjessze ezeket a K témákat az M dokumentumban (ez az eloszlás α néven ismert, szimmetrikus vagy aszimmetrikus lehet, erről később bővebben) minden szó hozzárendelésével téma.
- az M dokumentumban szereplő minden W szó esetében feltételezzük, hogy a témája rossz, de minden más szó a megfelelő témához van rendelve.
- valószínűségi hozzárendelése szó w téma alapján két dolog:
– milyen témák vannak az m
dokumentumban – hányszor rendelték a word w-t egy adott témához az összes dokumentumban (ezt az eloszlást β-nek hívják, erről később bővebben) - ismételje meg ezt a folyamatot többször minden dokumentumhoz, és kész!
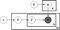
figcaption>smoothed lda fromhttps://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
a fenti egy lda modell lemezdiagramja, ahol:
α a per-dokumentum téma disztribúciók,
β a per-téma szót engedély,
θ a téma elosztó dokumentum m,
φ a szót engedély a téma, k,
z az a téma, az n-edik word a dokumentum m,
w az adott szó
Csípés a Modell
a lemez modell a fenti ábrát, látható, hogy w szürkén jelenik meg. Ez azért van, mert ez az egyetlen megfigyelhető változó a rendszerben, míg a többiek látensek. Emiatt, hogy csípés a modell van néhány dolog, amit elrontani alatt én összpontosítani két.
α egy mátrix, ahol minden sor egy dokumentum, minden oszlop pedig egy témát ábrázol. Az I. sorban és a J oszlopban szereplő érték azt jelenti, hogy mennyire valószínű, hogy az I. dokumentum tartalmazza a J. témát. a szimmetrikus Eloszlás azt jelentené, hogy az egyes témák egyenletesen oszlanak el a dokumentumban, míg az aszimmetrikus Eloszlás bizonyos témákat előnyben részesít másokkal szemben. Ez befolyásolja a modell kiindulási pontját, és akkor használható, ha durva elképzelése van arról, hogy a témák hogyan oszlanak meg az eredmények javítása érdekében.
β egy mátrix, ahol minden sor egy témát jelöl, minden oszlop pedig egy szót. Az I. sorban és a J. oszlopban szereplő érték azt jelenti, hogy mennyire valószínű, hogy az I. téma szót tartalmaz j. általában minden szó egyenletesen oszlik el a témában, úgy, hogy egyetlen téma sem elfogult bizonyos szavak felé. Ezt azonban ki lehet használni annak érdekében, hogy bizonyos témákat bizonyos szavak előnyben részesítsenek. Például, ha tudod, hogy van egy téma az Apple termékek hasznos lehet elfogultság szavak, mint az “iphone” és “ipad” az egyik téma annak érdekében, hogy álljon a modell felé találni, hogy az adott téma.
következtetés
Ez a cikk nem azt jelentette, hogy egy teljes értékű Lda bemutató, hanem hogy áttekintést, hogyan LDA modellek működnek, és hogyan kell használni őket. Vannak sok megvalósítások odakinn, mint a Gensim, amelyek könnyen használható, nagyon hatékony. Egy jó bemutató a GENSIM könyvtár LDA modellezés megtalálható itt.
van valami gondolata, vagy talál valamit, amit kihagytam? Szólj!
Boldog téma modellezés!
Leave a Reply