OCR a Python, OpenCV, valamint PyTesseract

az Optikai karakterfelismerés (OCR) az átváltás a képek gépelt, kézzel írt, vagy nyomtatott szöveget gép-kódolt szöveget, hogy a beolvasott dokumentum, fénykép, egy dokumentum, egy fotó, egy jelenet (óriásplakátok egy fekvő kép), vagy a szöveg helyezett a kép (feliratok, a tv-adás).
az OCR általában alfolyamatokból áll, amelyeket a lehető legpontosabban kell végrehajtani.

/div>
- előfeldolgozás
- szövegfelismerés
- szövegfelismerés
- utófeldolgozás
az alfolyamatok természetesen a használati eset függvényében változhatnak, de ezek általában az optikai karakterfelismerés végrehajtásához szükséges lépések.
Tesseract OCR :
a Tesseract egy nyílt forráskódú szövegfelismerő (OCR) motor, amely az Apache 2.0 licenc alatt érhető el. Ezt fel lehet használni közvetlenül ,vagy (a programozók) egy API kivonat nyomtatott szöveget képek. Támogatja a nyelvek széles skáláját. A Tesseract nem rendelkezik beépített GUI-val, de számos elérhető a 3rdParty oldalról. A Tesseract számos programozási nyelvvel és keretrendszerrel kompatibilis az itt található csomagolásokon keresztül. Ezt fel lehet használni a meglévő elrendezés elemzés felismerni a szöveget egy nagy dokumentum, vagy lehet használni együtt egy külső szövegérzékelő felismerni a szöveget egy kép egyetlen szövegsor.
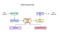
Kocka 4.00 tartalmaz egy új neurális hálózati alrendszer beállítva, mint egy szöveges sort készítettünk. Az OCRopus Python alapú LSTM implementációjából származik, de a tesseract számára c++ – ban újratervezték. A neurális hálózati rendszer a Tesseract-ban előre datálja a TensorFlow-t, de kompatibilis vele, mivel létezik egy változó gráf specifikációs nyelv (Vgsl) nevű hálózati leírás nyelv, amely a TensorFlow számára is elérhető.
egy karaktert tartalmazó kép felismeréséhez általában konvolúciós neurális hálózatot (CNN) használunk. Az önkényes hosszúságú szöveg karaktersorozat, az ilyen problémákat az RNNs segítségével oldják meg, az LSTM pedig az RNN népszerű formája. Olvassa el ezt a bejegyzést, hogy többet tudjon LSTM.
Tesseract kifejlesztett OCRopus modell Python, amely egy villa egy LSMT C++, az úgynevezett CLSTM. A CLSTM az LSTM visszatérő neurális hálózati modell implementációja C++nyelven.
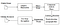
Tesseract a kódtisztítás és egy új LSTM modell hozzáadása volt. A bemeneti kép feldolgozása dobozok (téglalap) sorban vonal etetés az LSTM modell, amely kimenetet. Az alábbi képen láthatjuk, hogyan működik.

Telepítése Kocka
Telepítése kocka Windows könnyű a lefordított bináris itt található. Ne felejtsd el szerkeszteni a” path ” környezeti változót, majd add hozzá a tesseract elérési utat. Linux vagy Mac telepítéshez kevés parancs van telepítve.
alapértelmezés szerint a Tesseract egy szöveges oldalt vár el, amikor egy képet szegmensel. Ha csak egy kis régió OCR-jét szeretné elérni, próbáljon ki egy másik szegmentációs módot a — psm argumentum használatával. Jelenleg 14 mód áll rendelkezésre, amely megtalálható itt. Alapértelmezés szerint a Tesseract teljesen automatizálja az oldalszegmentációt, de nem hajt végre orientációt és szkriptfelismerést. A paraméter megadásához írja be a következőket:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
van még egy fontos érv, OCR motor mód (oem). A Tesseract 4 két OCR motorral rendelkezik — Legacy Tesseract engine és LSTM engine. A-oem opció segítségével négy üzemmód közül választhat.
0. Csak Legacy motor.
1. Neurális hálók csak LSTM motor.
2. Legacy + LSTM motorok.
3. Alapértelmezett, a rendelkezésre álló adatok alapján.
OCR Pytesseract és OpenCV esetén:
a Pytesseract a Tesseract-OCR motor csomagolóanyaga. Ez is hasznos, mint egy önálló felhívás script tesseract, mivel képes olvasni az összes képtípus által támogatott párna és Leptonica képalkotó könyvtárak, beleértve a jpeg, png, gif, bmp, tiff, és mások. További információ a Python megközelítés itt olvasható.
A Tesseract előfeldolgozása :
ellenőriznünk kell, hogy a kép megfelelően előfeldolgozott-e. a pontosság bizonyos szintjének biztosítása érdekében.
Ez magában foglalja az átméretezést, a binarizációt, a zajeltávolítást, az íróasztalt stb.
az OCR képének előkészítéséhez használja az alábbi Python funkciók bármelyikét, vagy kövesse az OpenCV dokumentációt.
Our input is this image :

Here’s what we get :

Getting boxes around text :
a határoló doboz adatait a PyTesseradt segítségével a következő kód segítségével határozhatjuk meg.
az alábbi szkript határoló doboz információkat ad a Tesseract által az OCR során észlelt minden karakterhez.
ha karakterek helyett szavakat szeretne a szavak körül, akkor a image_to_data funkció hasznos lesz. Használhatja aimage_to_data függvény kimeneti típus megadott pytesseractOutput.
az alábbi minta átvételi képet használjuk bemenetként a tesseract teszteléséhez .

Itt a kód :
A kimenet szótár a következőket kulcsok :

Használatával ez a szótár, tudjuk, hogy minden szót észlelt, a befoglaló doboz információ a szöveg, a bizalom pontszámok minden.
a telek a dobozok segítségével az alábbi kódot :
A kimenet:

Mint láthatjuk, hogy Ott van, nem képes felismerni az összes szövegdoboz magabiztosan, rossz minőségű, alacsony, apró betűk okozhat rossz minőségű OCR szöveg felismerés. Szintén nem végeztek előfeldolgozást a kép minőségének javítása érdekében.
szövegsablon illesztés ( csak számjegyek észlelése ):
Vegyük a példát arra, hogy megpróbáljuk megtalálni, hol van egy csak számjegyű karakterlánc a képen. Itt a sablon lesz a reguláris kifejezés minta, hogy mi lesz egyezik a mi OCR eredmények, hogy megtalálják a megfelelő határoló dobozok. Ehhez a regex modult és a image_to_data függvényt használjuk.

oldalszegmentációs módok :
a szöveg egy oldala többféle módon elemezhető. A tesseract api több oldalszegmentációs módot biztosít, ha csak egy kis régióban vagy különböző irányokban szeretné futtatni az OCR-t stb.
itt található a támogatott oldalszegmentációs módok listája tesseract :
0. Orientáció és script detection (OSD) csak.
1. Automatikus oldal szegmentálás OSD.
2. Automatikus oldalszegmentálás, de nincs OSD vagy OCR.
3. Teljesen automatikus oldalszegmentáció, de nincs OSD. (Alapértelmezett)
4. Tegyük fel, hogy egy oszlop a szöveg változó méretű.
5. Tegyük fel, hogy egyetlen egységes blokk függőlegesen igazított szöveget.
6. Vállaljon egyetlen egységes szövegblokkot.
7. Kezelje a képet egyetlen szövegsorként.
8. Kezelje a képet egyetlen szóként.
9. Kezelje a képet egyetlen szóként egy körben.
10. Kezelje a képet egyetlen karakterként.
11. Ritka szöveg. Keressen annyi szöveget, amennyire csak lehetséges, nincs külön sorrendben.
12. Ritka szöveg OSD-vel.
13. Nyers vonal. Kezelje a képet egyetlen szövegsorként, megkerülve a Tesseract-specifikus hackeket.
az oldalszegmentációs mód megváltoztatásához módosítsa a--psm argumentumot az egyéni konfigurációs karakterláncban a fent említett módkódok bármelyikére.
csak a számjegyeket érzékeli a konfiguráció használatával:
csak a számjegyeket ismeri fel, ha a konfigurációt a következőre változtatja:
amely a következő kimenetet adja.

div >
amint látja, a kimenet nem azonos a Regex használatával .
Whitelisting/Blacklisting karakterek:
azt mondja, hogy csak bizonyos karaktereket szeretne észlelni az adott képről, a többit pedig figyelmen kívül hagyja. Megadhatja a karakterek fehérlistáját (itt az összes kisbetűs karaktert csak a-tól z-ig használtuk) a következő konfigurációval.
:

Feketelista betűket :
Ha biztos benne, hogy bizonyos karakterek vagy kifejezések biztosan nem jelenik meg a szövegben (az OCR-visszatér rossz szöveg helyett feketelistára karakterek, egyéb), akkor feketelistára azok a karakterek használja a következő config.
kimenet :
Több nyelven szöveg :
adja meg a nyelvet kell az OCR kimenet, használja a -l LANG érv a config ahol LANG a 3 betűs kódja, milyen nyelven szeretné használni.
Több nyelven is dolgozhat a LANG paraméter megváltoztatásával:
NB : A -l paraméterhez először megadott nyelv az elsődleges nyelv.

S a következő kimenet :

Sajnos tesseract nem rendelkezik egy olyan funkcióval, amely érzékeli a nyelv, a szöveg, a kép automatikusan. Alternatív megoldást kínál egy másik python modul, a langdetect, amely pip-n keresztül telepíthető további információkért ellenőrizze ezt a linket.
Ez a modul ismét nem érzékeli a szöveg nyelvét egy kép segítségével, de karakterlánc bemenetre van szüksége a nyelv felismeréséhez. A legjobb módja ennek az, ha először használja a tesseract-ot, hogy OCR szöveget kapjon bármilyen nyelven, ahol úgy érzi, hogy ott van, a langdetect használatával, hogy megtalálja, milyen nyelvek szerepelnek az OCR szövegében, majd futtassa újra az OCR-t a talált nyelvekkel.
mondjuk, hogy van egy szövegünk, amiről azt hittük, hogy angol és portugál.
NB: a Tesseract rosszul teljesít, ha egy többnyelvű képen a konfigurációban megadott nyelvek hibásak vagy egyáltalán nem szerepelnek. Ez félrevezetheti a langdetect modult is.
Tesseract korlátozások:
Tesseract OCR elég erős, de van néhány korlátozás.
- az OCR nem olyan pontos, mint néhány elérhető kereskedelmi megoldás .
- nem működik jól a tárgyak által érintett képekkel, beleértve a részleges elzáródást, a torzított perspektívát és a komplex hátteret.
- nem képes felismerni a kézírást.
- előfordulhat, hogy az OCR kimenetként jelenik meg.
- Ha egy dokumentum a-L LANG argumentumokban megadottakon kívüli nyelveket tartalmaz, az eredmények rosszak lehetnek.
- nem mindig jó a dokumentumok természetes olvasási sorrendjének elemzésében. Előfordulhat például, hogy nem ismeri fel, hogy egy dokumentum két oszlopot tartalmaz, és megpróbálhat szöveget egyesíteni az oszlopok között.
- a rossz minőségű vizsgálatok rossz minőségű OCR-t eredményezhetnek.
- nem tárja fel, hogy a betűtípus család melyik szövegéhez tartozik.
Következtetés :
Kocka tökéletes szkennelés tiszta dokumentumok jön elég nagy pontossággal, font, változékonyság, mivel a képzés átfogó.
a Tesseract 4.0 legújabb kiadása támogatja a deep learning alapú OCR-t, amely lényegesen pontosabb. Maga az OCR motor egy hosszú, rövid távú memória (LSTM) hálózatra épül, amely egy bizonyos típusú visszatérő neurális hálózat (RNN).
Leave a Reply