LDA Argomento di Modellazione: Una Spiegazione
Sfondo
Argomento di modellazione è il processo di identificazione delle tematiche in un insieme di documenti. Questo può essere utile per i motori di ricerca, l’automazione del servizio clienti e qualsiasi altra istanza in cui è importante conoscere gli argomenti dei documenti. Ci sono diversi metodi per fare questo, ma qui ne spiegherò uno: Allocazione latente di Dirichlet (LDA).
L’algoritmo
LDA è una forma di apprendimento non supervisionato che visualizza i documenti come sacchi di parole (cioè l’ordine non importa). LDA funziona facendo prima un’ipotesi chiave: il modo in cui un documento è stato generato è stato selezionando un insieme di argomenti e quindi per ogni argomento scegliendo un insieme di parole. Ora si può chiedere ” ok così come fa a trovare argomenti?”Beh, la risposta è semplice: si reverse ingegneri questo processo. Per fare ciò fa quanto segue per ogni documento m:
- Supponiamo che ci siano argomenti k in tutti i documenti
- Distribuisci questi argomenti k nel documento m (questa distribuzione è nota come α e può essere simmetrica o asimmetrica, ne parleremo più avanti) assegnando ad ogni parola un argomento.
- Per ogni parola w nel documento m, supponiamo che il suo argomento sia sbagliato, ma ad ogni altra parola viene assegnato l’argomento corretto.
- Assegna probabilisticamente a word w un argomento basato su due cose:
– quali argomenti sono nel documento m
– quante volte a word w è stato assegnato un argomento particolare in tutti i documenti (questa distribuzione è chiamata β, ne parleremo più avanti) - Ripeti questo processo un numero di volte per ogni documento e il gioco è fatto!
Modello
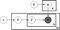
Sopra è ciò che è noto come un piatto diagramma di un modello LDA:
α è il per-documento argomento distribuzioni,
β è la parola argomento di distribuzione,
θ è l’argomento di distribuzione per documento m,
φ è la parola di distribuzione per l’argomento k,
z è l’argomento per l’n-esima parola nel documento m e
w è la parola specifica
per modificare il Modello
il modello di piastra schema di cui sopra, si può vedere che w è in grigio. Questo perché è l’unica variabile osservabile nel sistema mentre le altre sono latenti. Per questo motivo, per modificare il modello ci sono alcune cose con cui puoi scherzare e sotto mi concentro su due.
α è una matrice in cui ogni riga è un documento e ogni colonna rappresenta un argomento. Un valore nella riga i e nella colonna j rappresenta la probabilità che il documento i contenga l’argomento j. Una distribuzione simmetrica significherebbe che ogni argomento è distribuito uniformemente in tutto il documento mentre una distribuzione asimmetrica favorisce determinati argomenti rispetto ad altri. Ciò influisce sul punto di partenza del modello e può essere utilizzato quando si ha un’idea approssimativa di come vengono distribuiti gli argomenti per migliorare i risultati.
β è una matrice in cui ogni riga rappresenta un argomento e ogni colonna rappresenta una parola. Un valore nella riga i e nella colonna j rappresenta la probabilità che l’argomento i contenga la parola j. Di solito ogni parola è distribuita uniformemente in tutto l’argomento in modo tale che nessun argomento sia distorto verso determinate parole. Questo può essere sfruttato anche se al fine di polarizzare alcuni argomenti per favorire certe parole. Ad esempio, se sai di avere un argomento sui prodotti Apple, può essere utile bias parole come “iphone” e “ipad” per uno degli argomenti al fine di spingere il modello verso la ricerca di quel particolare argomento.
Conclusione
Questo articolo non è pensato per essere un tutorial LDA in piena regola, ma piuttosto per dare una panoramica di come funzionano i modelli LDA e come usarli. Ci sono molte implementazioni là fuori come Gensim che sono facili da usare e molto efficaci. Un buon tutorial sull’utilizzo della libreria Gensim per la modellazione LDA può essere trovato qui.
Hai qualche pensiero o trova qualcosa che ho perso? Fammi sapere!
Felice modellazione argomento!
Leave a Reply