OCR con Python, OpenCV e PyTesseract

il Riconoscimento Ottico dei Caratteri (OCR) è la conversione di immagini di tipizzati, scritti a mano o stampati testo in macchina il testo codificato, se da una scansione di un documento, una foto di un documento, una foto di una scena (cartelloni in un paesaggio foto) o da un testo sovrapposto a un’immagine (sottotitoli in una trasmissione televisiva).
OCR consiste generalmente di sotto-processi per eseguire il più accuratamente possibile.

- Pre-trattamento
- rilevazione di Testo
- riconoscimento del Testo
- Post-processing
Il sub-processi possono naturalmente variare a seconda del caso d’uso, ma questi sono generalmente i passaggi necessari per eseguire il riconoscimento ottico dei caratteri.
Tesseract OCR :
Tesseract è un motore di riconoscimento del testo open source (OCR), disponibile sotto licenza Apache 2.0. Può essere utilizzato direttamente o (per i programmatori) utilizzando un’API per estrarre il testo stampato dalle immagini. Supporta un’ampia varietà di lingue. Tesseract non ha una GUI integrata, ma ce ne sono diversi disponibili dalla pagina 3rdParty. Tesseract è compatibile con molti linguaggi di programmazione e framework attraverso wrapper che possono essere trovati qui. Può essere utilizzato con l’analisi di layout esistente per riconoscere il testo all’interno di un documento di grandi dimensioni, oppure può essere utilizzato in combinazione con un rilevatore di testo esterno per riconoscere il testo da un’immagine di una singola riga di testo.
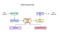
Tesseract 4.00 include una nuova rete neurale sottosistema configurato come una riga di testo di riconoscimento. Ha le sue origini nell’implementazione LSTM basata su Python di OCopus, ma è stata ridisegnata per Tesseract in C++. Il sistema di rete neurale in Tesseract pre-date TensorFlow ma è compatibile con esso, in quanto esiste un linguaggio di descrizione della rete chiamato Variable Graph Specification Language (VGSL), che è disponibile anche per TensorFlow.
Per riconoscere un’immagine contenente un singolo carattere, in genere utilizziamo una rete neurale convoluzionale (CNN). Il testo di lunghezza arbitraria è una sequenza di caratteri, e tali problemi sono risolti usando RNNs e LSTM è una forma popolare di RNN. Leggi questo post per saperne di più su LSTM.
Tesseract sviluppato dal modello Pythonopus in Python che era un fork di un LSMT in C++, chiamato CLSTM. CLSTM è un’implementazione del modello di rete neurale ricorrente LSTM in C++.
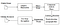
Tesseract è stato uno sforzo di codice di pulizia e l’aggiunta di un nuovo LSTM modello. L’immagine di input viene elaborata in caselle (rettangolo) linea per linea che si immette nel modello LSTM e fornisce l’output. Nell’immagine qui sotto possiamo visualizzare come funziona.

Installazione di Tesseract
l’Installazione di tesseract su Windows è facile con i binari precompilati trovato qui. Non dimenticare di modificare la variabile d’ambiente” path ” e aggiungere il percorso tesseract. Per l’installazione di Linux o Mac è installato con pochi comandi.
Per impostazione predefinita, Tesseract prevede una pagina di testo quando segmenta un’immagine. Se stai solo cercando di OCR una piccola regione, provare una diversa modalità di segmentazione, utilizzando l’argomento-psm. Ci sono 14 modalità disponibili che possono essere trovate qui. Per impostazione predefinita, Tesseract automatizza completamente la segmentazione della pagina ma non esegue l’orientamento e il rilevamento dello script. Per specificare il parametro, digitare quanto segue:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
C’è anche un altro argomento importante, OCR engine mode (oem). Tesseract 4 ha due motori OCR: Legacy Tesseract engine e LSTM engine. Ci sono quattro modalità di funzionamento scelte utilizzando l’opzione-oem.
0. Solo motore legacy.
1. Reti neurali solo motore LSTM.
2. Motori Legacy + LSTM.
3. Predefinito, in base a ciò che è disponibile.
OCR con Pytesseract e OpenCV:
Pytesseract è un wrapper per il motore Tesseract-OCR. È anche utile come script di invocazione stand-alone per tesseract, in quanto può leggere tutti i tipi di immagine supportati dalle librerie di imaging Pillow e Leptonica, inclusi jpeg, png, gif, bmp, tiff e altri. Maggiori informazioni sull’approccio Python leggi qui.
Preprocessing per Tesseract:
Dobbiamo assicurarci che l’immagine sia adeguatamente pre-elaborata. per garantire un certo livello di precisione.
Questo include ridimensionamento, binarizzazione, rimozione del rumore, deskewing, ecc.
Per pre-elaborare image per OCR, utilizzare una delle seguenti funzioni python o seguire la documentazione di OpenCV.
Our input is this image :

Here’s what we get :

Getting boxes around text :
Possiamo determinare le informazioni del riquadro di delimitazione con PyTesseradt usando il seguente codice.
Lo script qui sotto ti darà le informazioni del riquadro di delimitazione per ogni carattere rilevato da tesseract durante l’OCR.
Se si desidera scatole intorno parole invece di caratteri, la funzioneimage_to_data sarà utile. È possibile utilizzare la funzione image_to_datacon il tipo di output specificato con pytesseractOutput.
Useremo l’immagine ricevuta di esempio qui sotto come input per testare tesseract .

Ecco il codice :
L’uscita è un dizionario con i seguenti tasti :

l’Utilizzo di questo dizionario, siamo in grado di ottenere ogni parola rilevato, la loro delimitazione e informazioni, il testo e la fiducia punteggi per ogni.
È possibile tracciare le caselle utilizzando il codice riportato di seguito :
L’output:

Come si può vedere Tesseract non è in grado di rilevare tutte le caselle di testo con fiducia, scarsa qualità di scansione e con caratteri di piccole dimensioni può produrre scarsa testo OCR di rilevamento. Inoltre non è stata eseguita alcuna pre-elaborazione per migliorare la qualità dell’immagine.
Corrispondenza del modello di testo ( rileva solo cifre ):
Prendi l’esempio di cercare di trovare dove si trova una stringa di sole cifre in un’immagine. Qui il nostro modello sarà un modello di espressione regolare che abbineremo con i nostri risultati OCR per trovare le caselle di delimitazione appropriate. Useremo il moduloregex e la funzioneimage_to_data per questo.

Pagina di segmentazione delle modalità di :
Una pagina di testo può essere analizzata in diversi modi. L’api tesseract fornisce diverse modalità di segmentazione delle pagine se si desidera eseguire OCR solo su una piccola regione o in diversi orientamenti, ecc.
Ecco un elenco delle modalità di segmentazione delle pagine supportate da tesseract:
0. Orientamento e script di rilevamento (OSD) solo.
1. Segmentazione automatica delle pagine con OSD.
2. Segmentazione automatica della pagina, ma nessun OSD o OCR.
3. Segmentazione della pagina completamente automatica, ma nessun OSD. (Predefinito)
4. Assumere una singola colonna di testo di dimensioni variabili.
5. Assumere un singolo blocco uniforme di testo allineato verticalmente.
6. Assumere un singolo blocco uniforme di testo.
7. Tratta l’immagine come una singola riga di testo.
8. Tratta l’immagine come una singola parola.
9. Tratta l’immagine come una singola parola in un cerchio.
10. Tratta l’immagine come un singolo carattere.
11. Testo sparso. Trova più testo possibile in nessun ordine particolare.
12. Testo sparso con OSD.
13. Linea grezza. Tratta l’immagine come una singola riga di testo, ignorando gli hack specifici di Tesseract.
Per modificare la modalità di segmentazione della pagina, modificare l’argomento --psm nella stringa di configurazione personalizzata in uno qualsiasi dei codici di modalità sopra menzionati.
Rileva solo cifre utilizzando la configurazione:
È possibile riconoscere solo cifre modificando la configurazione nel modo seguente :
che fornisce il seguente output.

Come potete vedere il risultato non è lo stesso usando l’espressione regolare .
Whitelisting / Blacklisting characters:
Supponiamo che tu voglia solo rilevare determinati caratteri dall’immagine data e ignorare il resto. Puoi specificare la tua whitelist di caratteri (qui, abbiamo usato tutti i caratteri minuscoli dalla a alla z solo) usando la seguente configurazione.
E ci dà questo output :

Blacklist lettere :
Se sei sicuro che alcuni caratteri o espressioni sicuramente non nel tuo testo (OCR tornerà testo sbagliato nel posto della lista nera caratteri altrimenti), potete mettere quei caratteri utilizzando la seguente configurazione.
Uscita :
Più lingue di testo :
Per specificare la lingua, hai bisogno di OCR di uscita, utilizzare il tag -l LANG argomento nel config, dove LANG è il 3 lettere del codice per la lingua che si desidera utilizzare.
È possibile lavorare con più lingue modificando il parametro LANG in quanto tale :
NB : La lingua specificata per prima al parametro-l è la lingua principale.

E si ottiene il seguente output :

Purtroppo tesseract non dispone di una funzione per rilevare la lingua del testo in un’immagine automaticamente. Una soluzione alternativa è fornita da un altro modulo python chiamato langdetect che può essere installato tramite pip per maggiori informazioni controlla questo link.
Questo modulo di nuovo, non rileva la lingua del testo utilizzando un’immagine, ma ha bisogno di input di stringa per rilevare la lingua da. Il modo migliore per farlo è prima usare tesseract per ottenere il testo OCR in qualsiasi lingua tu possa sentire, usando langdetect per trovare quali lingue sono incluse nel testo OCR e quindi eseguire nuovamente OCR con le lingue trovate.
Diciamo che abbiamo un testo che pensavamo fosse in inglese e portoghese.
NB: Tesseract funziona male quando, in un’immagine con più lingue, le lingue specificate nella configurazione sono errate o non sono affatto menzionate. Questo può indurre in errore anche il modulo langdetect.
Limitazioni Tesseract:
L’OCR Tesseract è abbastanza potente ma ha alcune limitazioni.
- L’OCR non è accurato come alcune soluzioni commerciali disponibili .
- Non funziona bene con le immagini interessate da artefatti tra cui occlusione parziale, prospettiva distorta e sfondo complesso.
- Non è in grado di riconoscere la scrittura a mano.
- Potrebbe trovare incomprensibile e segnalarlo come output OCR.
- Se un documento contiene lingue al di fuori di quelle fornite negli argomenti-l LANG, i risultati potrebbero essere scarsi.
- Non è sempre bravo ad analizzare l’ordine di lettura naturale dei documenti. Ad esempio, potrebbe non riconoscere che un documento contiene due colonne e potrebbe provare a unire il testo tra le colonne.
- Scansioni di scarsa qualità possono produrre OCR di scarsa qualità.
- Non espone informazioni su quale testo della famiglia di font appartiene.
Conclusione:
Tesseract è perfetto per la scansione di documenti puliti e viene fornito con una precisione e una variabilità dei caratteri piuttosto elevate poiché la sua formazione è stata completa.
L’ultima versione di Tesseract 4.0 supporta l’OCR basato sull’apprendimento profondo che è significativamente più accurato. Il motore OCR stesso è costruito su una rete LSTM (Long Short-Term Memory), che è un particolare tipo di rete neurale ricorrente (RNN).
Leave a Reply