추상적 데이터 구조

추상적인 데이터 유형
컴퓨터 과학,추상적인 데이터 입력(ADT)수학 모델에 대한 데이터는 종류의 데이터 유형에 의해 정의된 동작(의미) 의 관점에서의 사용자의 데이터,구체적으로의 측면에서 가능한 값은,가능한 한 데이터에 대한 작업의 이 유형의 행동이 이러한 작업입니다. 이는 데이터의 구체적인 표현이며 사용자가 아닌 구현 자의 관점 인 데이터 구조와 대조됩니다.
정식으로는 ADT 정의될 수 있으로”클래스의 객체의 논리적 행동에 의해 정의된 세트의 값을 설정 작업의”이와 유사한 대수적 구조에서 수학했다. 무엇을 의미하는”행위”변화하여 저자와 함께,두 가지 주요 형태의 공식 사양이 동작되고 공리(대수)사양과 추상적인 모델; 이들은 각각 추상 기계의 공리 의미 및 운영 의미에 해당합니다. 일부 작가 포함한 계산적 복잡성(“cost”),모두의 측면에서는 시간(컴퓨팅 작업)및 공간(한 값을 나타내는).
우리가 추상 구조를 사용하는 이유는 그 안에 저장된 데이터의 디자인을 기반으로 메모리를 효율적으로 사용하기 때문입니다. 은 매우 많은 양의 데이터 또는 매우 자주 변경되는 데이터,데이터 구조에 큰 차이를 만들 수 있습 효율성에 있는(실행 시간)컴퓨터 프로그램입니다.
에 더 일반적 언어로,추상적 데이터 구조는 단지 몇 가지 배열의 데이터는 우리가 내장된 순서대로 배열.
는 사랑스러운 완벽하게 개관
일부 형태의 추상적 데이터 구조
의해 평가 IB
- 정적 및 동적 데이터 구조
- 배열
- 두 차원 배열
- 스
- 큐
- 링크 목록
- 나
- 이진 나무
- 컬렉션
- 재귀
가에 의해 평가되지 않습 IB, 그러나 당신이 그들을 알고 있어야 합
- 목
- 사전
- 설정
- 튜플
의 기본 작업은 데이터 구조
이 탁월한 슬라이드에서 시몬 Allardice.

의 비교를 다른 데이터 구조
| 데이터 구조 | 강점 | 약점 |
| 배열 | 삽입과 삭제를 요소 반복을 통해 수집 | 정렬하고,검색의 삽입과 삭제-는 경우에 특히 삽입과 삭제는 처음에 또는 배열의 끝 |
| 연결 목록 | 에 직접 인덱싱을 만들고 사용하기 쉽습 | 직접 액세스 검색 및 정렬 |
| 스택과 큐 | 에 대한 설계 LIFO/FIFO | 에 직접 액세스,검색 및 분류 |
| 이진 나무 | 의 속도로 삽입과 삭제는 속도의 액세스 유지를 순서대로 정렬되어 | 약간의 오버헤드 |
- 고정 구조를 더 빨리/작
- 을 고려할 때 당신이 사용해야 한다는 추상적 데이터 구조는,당신은 자신을 요청해야합니다: 무엇을 보유하고 가장 데이터가 무엇을 보유하고 가장 자주 변경되는 데이터가?
정적 대 동적 데이터 구조의 비교
이 비교는 우리의 컴퓨터 과학 교과서에서 사용됩니다.
| 정적 데이터 구조 | 동적 데이터 구조 |
| 비효율적으로 메모리를 할당할 수 있는 필요하지 않습니다. | 필요에 따라 메모리 양이 달라 지므로 효율적입니다. |
| 프로그램이 작성 될 때 메모리 위치가 고정되어 데이터의 각 요소에 빠르게 액세스 할 수 있습니다. | 런타임에 메모리 위치가 할당되므로 각 요소에 대한 액세스가 느려집니다. |
| 할당 된 메모리 주소는 연속적이므로 더 빨리 액세스 할 수 있습니다. | 할당 된 메모리 주소는 조각화되어 액세스 속도가 느려질 수 있습니다. |
| 구조는 고정 된 크기이므로 작업하기에 더 예측 가능합니다. 예를 들어,헤더를 포함할 수 있습니다. | 구조는 크기가 다양하므로 현재 구조의 크기를 알기위한 메커니즘이 있어야합니다. |
| 데이터의 다른 요소 간의 관계는 변경되지 않습니다. | 프로그램이 실행됨에 따라 서로 다른 데이터 요소 간의 관계가 변경됩니다. |
를 선택하는 데이터 구조를 사용하여
이 그래픽 사용되는 엄청난 감사에서 Dartford 문법 학교 컴퓨터공학부.
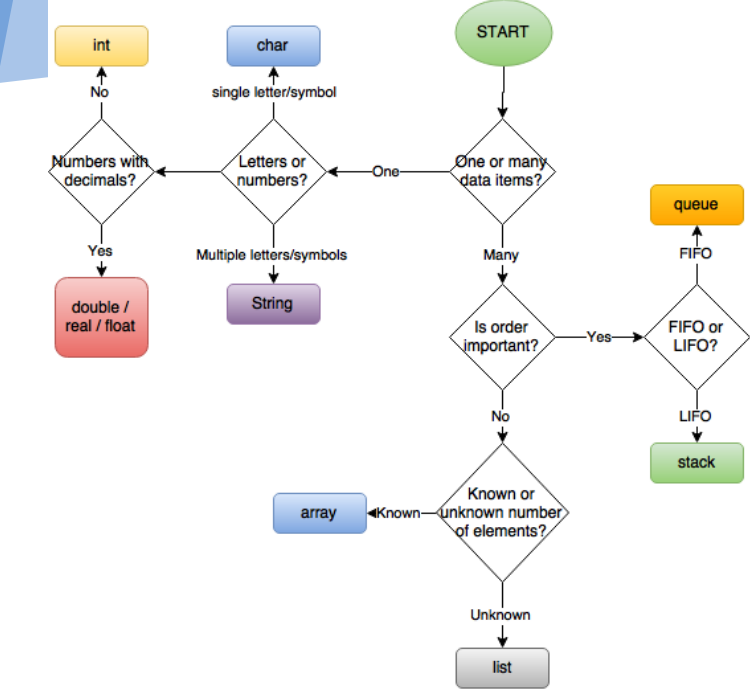
표준
- 재귀 적 사고의 사용이 필요한 상황을 식별합니다.
- 지정된 문제 솔루션에서 재귀 적 사고를 식별하십시오.
- 재귀 알고리즘을 추적하여 문제에 대한 해결책을 표현합니다.
- 2 차원 배열의 특성을 설명합니다.
- 2 차원 배열을 사용하여 알고리즘을 구성합니다.
- 스택의 특성과 응용 프로그램을 설명합니다.
- 스택의 액세스 방법을 사용하여 알고리즘을 구성합니다.
- 큐의 특성과 응용 프로그램을 설명합니다.
- 큐의 액세스 방법을 사용하여 알고리즘을 구성합니다.
- 정적 스택 및 대기열로 배열의 사용을 설명합니다.
- 동적 데이터 구조의 특징과 특성을 설명합니다.
- 링크 된 목록이 논리적으로 작동하는 방법을 설명합니다.
- 링크 된 목록(단일,이중 및 원형)을 스케치하십시오.
- 컬렉션의 특성과 응용 프로그램을 설명합니다.
- 컬렉션의 액세스 방법을 사용하여 알고리즘을 구성합니다.
- 프로그래밍 된 솔루션 내에서 하위 프로그램 및 컬렉션의 필요성을 논의합니다.
- 구성 알고리즘을 사용하여 미리 정의된 하위 프로그램,하나의 차원 배열 및/또는 컬렉션이 있습니다.
- 트리가 논리적으로 작동하는 방법을 설명합니다(이진 및 비 이진 모두).
- 용어 정의: 부모,왼쪽-자식,오른쪽-자식,하위 트리,루트 및 리프.
- inorder,postorder 및 preorder tree traversal 의 결과를 명시합니다.
- 스케치 이진 트리.
- 동적 데이터 구조라는 용어를 정의합니다.
- 정적 및 동적 데이터 구조의 사용을 비교합니다.
- 주어진 상황에 적합한 구조를 제안하십시오.
Leave a Reply