Lda Emne Modellering: En Forklaring
bakgrunn
emnemodellering er prosessen med å identifisere emner i et sett med dokumenter. Dette kan være nyttig for søkemotorer, kundeservice automatisering, og alle andre tilfeller der vite temaene dokumenter er viktig. Det er flere metoder for å gå om å gjøre dette, men her vil jeg forklare en: Latent Dirichlet Allokering (LDA).
Algoritmen
LDA er en form for uovervåket læring som ser dokumenter som poser med ord (dvs.orden spiller ingen rolle). LDA fungerer ved først å gjøre en viktig forutsetning: måten et dokument ble generert var ved å plukke et sett med emner og deretter for hvert emne plukke et sett med ord. Nå kan du spørre » ok så hvordan finner det emner ?»Vel svaret er enkelt: det reverserer ingeniører denne prosessen . For å gjøre dette gjør det følgende for hvert dokument m:
- Anta at det er k-emner på tvers av alle dokumentene
- Distribuere disse k-emnene på tvers av dokument m (denne distribusjonen er kjent som α og kan være symmetrisk eller asymmetrisk, mer om dette senere) ved å tildele hvert ord et emne.
- for hvert ord w i dokument m, anta at emnet er feil, men hvert annet ord er tildelt riktig emne.
- Probabilistisk tilordne ord w et emne basert på to ting:
– hvilke emner er i dokument m
– hvor mange ganger word w har blitt tildelt et bestemt emne på tvers av alle dokumentene (denne distribusjonen kalles β, mer om dette senere) - Gjenta denne prosessen flere ganger for hvert dokument, og du Er ferdig!
Modellen
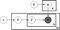
over er det som er kjent som en plate diagram av en lda modell hvor:
α er emnefordelingen per dokument,
β er emnefordelingen per emne,
θ er emnefordelingen for dokument m,
φ er ordfordelingen for emne k,
z er emnet for n-ordet i dokument m, og
w er det spesifikke ordet
Tilpasning Av Modellen
i modelldiagrammet ovenfor kan du se at w er nedtonet. Dette er fordi det er den eneste observerbare variabelen i systemet mens de andre er latente. På grunn av dette, for å finjustere modellen er det et par ting du kan rote med og under jeg fokusere på to.
α er en matrise hvor hver rad er et dokument og hver kolonne representerer et emne. En verdi i rad i og kolonne j representerer hvor sannsynlig dokument i inneholder emne j. en symmetrisk fordeling vil bety at hvert emne er jevnt fordelt gjennom dokumentet mens en asymmetrisk fordeling favoriserer visse emner over andre. Dette påvirker utgangspunktet for modellen og kan brukes når du har en grov ide om hvordan emnene distribueres for å forbedre resultatene.
β er en matrise hvor hver rad representerer et emne og hver kolonne representerer et ord. En verdi i rad i og kolonne j representerer hvor sannsynlig at emnet i inneholder ord j. Vanligvis hvert ord er fordelt jevnt over hele emnet slik at ingen emne er partisk mot visse ord. Dette kan utnyttes skjønt for å bias visse emner å favorisere visse ord. For eksempel hvis du vet at Du har et emne Om Apple-produkter, kan det være nyttig å forspenne ord som «iphone» og «ipad» for et av emnene for å presse modellen mot å finne det aktuelle emnet.
Konklusjon
denne artikkelen er ikke ment å være en fullverdig lda tutorial, men heller å gi en oversikt over HVORDAN LDA modeller fungerer og hvordan du bruker dem. Det er mange implementeringer der ute som Gensim som er enkle å bruke og svært effektive. En god opplæring om bruk Av Gensim-biblioteket for lda-modellering finner du her.
Har du noen tanker eller finner noe jeg savnet? Gi meg beskjed!
Glad emne modellering!
Leave a Reply