OCR med Python, OpenCV og PyTesseract

/ div>
optisk tegngjenkjenning (ocr) er konvertering av bilder av maskinskrevet, håndskrevet eller trykt tekst til maskinkodet tekst, enten fra et skannet dokument, et bilde av et dokument, et bilde fra en scene (reklametavler i et landskapsfoto) eller fra en tekst lagt på et bilde (undertekster på en tv-sending).OCR består generelt av delprosesser for å utføre så nøyaktig som mulig.

- pre-processing
- tekstgjenkjenning
- post-processing
delprosessene kan selvsagt variere avhengig av brukstilfellet, men dette er generelt trinnene som trengs for å utføre optisk tegngjenkjenning.
TESSERACT OCR :
Tesseract Er en ÅPEN kildekode tekstgjenkjenning (OCR) Motor, tilgjengelig Under Apache 2.0 lisens. Den kan brukes direkte, eller (for programmerere) ved HJELP AV EN API for å trekke ut trykt tekst fra bilder. Den støtter et bredt utvalg av språk. Tesseract har ikke en innebygd GUI, men det er flere tilgjengelige fra 3rdParty-siden. Tesseract er kompatibel med mange programmeringsspråk og rammer gjennom wrappers som kan bli funnet her. Den kan brukes sammen med den eksisterende layoutanalysen for å gjenkjenne tekst i et stort dokument, eller den kan brukes sammen med en ekstern tekstdetektor for å gjenkjenne tekst fra et bilde av en enkelt tekstlinje.
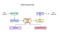
OCR Prosessflyt fra et blogginnlegg
tesseract 4.00 inneholder et nytt nevralt nettverksundersystem konfigurert som en tekstlinjegjenkjenner. Den har sin opprinnelse I OCRopus ‘ Python-baserte lstm implementering, men har blitt redesignet For Tesseract I C++. Det nevrale nettverkssystemet i Tesseract pre-dates TensorFlow, men er kompatibelt med Det, da det er et nettverksbeskrivelsesspråk kalt Variable Graph Specification Language (VGSL), som også er tilgjengelig for Tensorflow.For å gjenkjenne et bilde som inneholder et enkelt tegn, bruker vi vanligvis ET Convolutional Neural Network (CNN). Tekst av vilkårlig lengde er en sekvens av tegn, og slike problemer løses ved Hjelp Av RNNs og LSTM er en populær form FOR RNN. Les dette innlegget for å lære mer OM LSTM.Tesseract utviklet Seg fra OCRopus-modellen I Python som var en gaffel AV EN LSMT I C++, kalt CLSTM. CLSTM er en implementering AV lstm relapsing neural network model i C++.
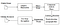
TESSERACT 3 OCR prosess fra papir
tesseract var et forsøk på koderengjøring og å legge til en ny lstm-modell. Inngangsbildet behandles i bokser (rektangel) linje ved linje som mates inn I lstm-modellen og gir utgang. I bildet nedenfor kan vi visualisere hvordan det fungerer.

bruker lstm modell presentasjon
installere tesseract
installere tesseract på windows er enkelt med forhåndskompilerte binærfiler funnet her. Ikke glem å redigere» path » miljøvariabelen og legge tesseract banen. For Linux eller Mac installasjon er det installert med få kommandoer.
som standard forventer Tesseract en side med tekst når den segmenterer et bilde. Hvis DU bare ønsker Å OCR et lite område, kan du prøve en annen segmenteringsmodus ved hjelp av-psm-argumentet. Det er 14 moduser tilgjengelig som kan bli funnet her. Som standard automatiserer Tesseract sidesegmenteringen, men utfører ikke orientering og skriptdeteksjon. For å angi parameteren, skriv inn følgende:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
DET er også et viktigere argument, OCR engine mode (oem). Tesseract 4 har TO OCR-motorer-Legacy tesseract engine og LSTM engine. Det er fire driftsformer valgt ved hjelp av-oem-alternativet.
0. Bare eldre motor.
1. Nevrale nett LSTM-motor bare.
2. Legacy + lstm motorer.
3. Standard, basert på hva som er tilgjengelig.
OCR med Pytesseract og OpenCV:
Pytesseract er en wrapper For Tesseract-OCR-Motoren. Det er også nyttig som et frittstående påkallingsskript til tesseract, da det kan lese alle bildetyper som støttes av Pillow og Leptonica imaging libraries, inkludert jpeg, png, gif, bmp, tiff og andre. Mer info om Python tilnærming lese her.
Forbehandling For Tesseract:
vi må sørge for at bildet er riktig forhåndsbehandlet. for å sikre et visst nivå av nøyaktighet.
dette inkluderer rescaling, binarisering, støyfjerning, deskewing, etc.
for å preprocessere bilde FOR OCR, bruk en av følgende python-funksjoner eller følg opencv-dokumentasjonen.
Our input is this image :

Here’s what we get :

Getting boxes around text :
vi kan bestemme grenseboksinformasjonen Med PyTesseradt ved hjelp av følgende kode.
skriptet nedenfor vil gi deg markeringsboksinformasjon for hvert tegn som oppdages av tesseract under OCR.
hvis du vil ha bokser rundt ord i stedet for tegn, vil funksjonen image_to_data komme til nytte. Du kan brukeimage_to_data – funksjonen med utgangstype spesifisert med pytesseract Output.
Vi vil bruke prøven kvittering bildet nedenfor som input for å teste ut tesseract .

her er koden:
utgangen er en ordbok med følgende nøkler:
ved hjelp av denne ordlisten kan vi få hvert ord oppdaget, deres grenseboksinformasjon, teksten i dem og konfidenspoengene for hver.
du kan plotte boksene ved å bruke koden nedenfor :
utgangen:

som vi kan se tesseract er ikke i stand til å oppdage alle tekstbokser trygt, dårlig kvalitet skanner og små fonter kan produsere dårlig kvalitet ocr tekst deteksjon. Også ingen forbehandling har blitt gjort for å forbedre kvaliteten på bildet.
tekstmal matching (oppdage bare sifre ):
Ta eksemplet på å prøve å finne hvor en eneste sifrestreng er i et bilde. Her vil vår mal være et vanlig uttrykksmønster som vi vil matche MED VÅRE OCR-resultater for å finne de riktige grenseboksene. Vi vil bruke regex modulen ogimage_to_data funksjonen for dette.

sidesegmenteringsmoduser :
det er flere måter en side med tekst kan analyseres på. Tesseract api gir flere sidesegmenteringsmoduser hvis DU vil kjøre OCR på bare en liten region eller i forskjellige retninger, etc.
her er en liste over støttede sidesegmenteringsmoduser av tesseract:
0. Orientering og script detection (OSD) bare.
1. Automatisk sidesegmentering MED OSD.
2. Automatisk sidesegmentering, men INGEN OSD eller OCR.
3. Helautomatisk side segmentering, men ingen OSD. (Standard)
4. Anta en enkelt kolonne med tekst med variable størrelser.
5. Anta en enkelt ensartet blokk med vertikalt justert tekst.
6. Anta en enkelt enhetlig tekstblokk.
7. Behandle bildet som en enkelt tekstlinje.
8. Behandle bildet som et enkelt ord.
9. Behandle bildet som et enkelt ord i en sirkel.
10. Behandle bildet som et enkelt tegn.
11. Sparsom tekst. Finn så mye tekst som mulig i ingen bestemt rekkefølge.
12. Sparsom tekst MED OSD.
13. Rå linje. Behandle bildet som en enkelt tekstlinje, omgå hack som Er tesseract-spesifikke.
hvis du vil endre sidesegmenteringsmodus, endrer du argumentet--psm i den egendefinerte config-strengen til en av moduskodene som er nevnt ovenfor.
Oppdag bare sifre ved hjelp av konfigurasjon:
du kan bare gjenkjenne sifre ved å endre konfigurasjonen til følgende:
som gir følgende utdata.

som du kan se, er utgangen ikke den samme ved hjelp av regex .
Hvitelisting / Svartelisting tegn:
Si at du bare vil oppdage bestemte tegn fra det gitte bildet og ignorere resten. Du kan angi hviteliste over tegn (her har vi brukt alle små bokstaver fra a til å) ved å bruke følgende config.
Og det gir oss denne utgangen :

svartelisting letters:
hvis du er sikker på at noen tegn eller uttrykk definitivt ikke vil dukke opp i teksten din (ocr vil returnere feil tekst i stedet for svartelistede tegn ellers), kan du svarteliste disse tegnene ved å bruke følgende config.
Utgang :

flere språk tekst:
for å angi språket du trenger din ocr-utgang i, bruk -l LANG argumentet i config hvor lang er 3 bokstavskoden for hvilket språk du vil bruke.
du kan arbeide med flere språk ved å endre lang-parameteren som sådan:
NB : Språket som er angitt først til parameteren-l er primærspråket.

og du vil få følgende utdata:

dessverre tesseract ikke har en funksjon for å oppdage språket i teksten i et bilde automatisk. En alternativ løsning er levert av en annen python modul kalt langdetect som kan installeres via pip for mer informasjon sjekk denne linken.
denne modulen oppdager ikke språket i tekst ved hjelp av et bilde, men trenger strenginngang for å oppdage språket fra. Den beste måten å gjøre dette på er å først bruke tesseract for å få OCR-tekst på hvilke språk du måtte føle er der inne, ved å bruke langdetect for å finne hvilke språk som er inkludert I OCR-teksten, og kjør DERETTER OCR igjen med språkene som er funnet.
Si at vi har en tekst vi trodde var på engelsk og portugisisk.
NB: Tesseract fungerer dårlig når, i et bilde med flere språk, språkene som er angitt i config er feil eller ikke er nevnt i det hele tatt. Dette kan villede langdetect-modulen ganske mye også.
tesseract begrensninger:
Tesseract OCR er ganske kraftig, men har noen begrensninger.
- OCR er ikke så nøyaktig som noen tilgjengelige kommersielle løsninger .
- gjør det ikke bra med bilder som påvirkes av gjenstander, inkludert delvis okklusjon, forvrengt perspektiv og kompleks bakgrunn.
- Det er ikke i stand til å gjenkjenne håndskrift.
- Det kan finne gibberish og rapportere dette som OCR-utgang.
- hvis et dokument inneholder språk utenfor de som er angitt i-L lang-argumentene, kan resultatene være dårlige.
- det er ikke alltid bra å analysere den naturlige leserekkefølgen av dokumenter. Det kan for eksempel mislykkes i å gjenkjenne at et dokument inneholder to kolonner, og kan prøve å slå sammen tekst på tvers av kolonner.
- dårlig kvalitet skanner kan produsere DÅRLIG KVALITET OCR.
- det eksponerer ikke informasjon om hvilken skriftfamilie tekst tilhører.
Konklusjon:
Tesseract er perfekt for skanning av rene dokumenter og kommer med ganske høy nøyaktighet og skriftvariabilitet siden treningen var omfattende.
den nyeste versjonen Av Tesseract 4.0 støtter dyp læring BASERT OCR som er betydelig mer nøyaktig. OCR-motoren i seg selv er bygget på Et Langt Korttidsminne (Lstm) nettverk, som er en bestemt type Tilbakevendende Nevrale Nettverk (RNN).
Leave a Reply