LDA Onderwerp Modelleren: Een Verklaring
Achtergrond
Onderwerp modelleren is het proces van het identificeren van de onderwerpen in een set van documenten. Dit kan nuttig zijn voor zoekmachines, klantenservice automatisering, en elke andere instantie waar het kennen van de onderwerpen van documenten is belangrijk. Er zijn meerdere methoden om dit te doen, maar hier zal ik een uitleggen: Latente Dirichlet-toewijzing (Lda).
het algoritme
LDA is een vorm van leren zonder toezicht dat documenten als zakken met woorden ziet (dat wil zeggen volgorde doet er niet toe). LDA werkt door eerst een belangrijke aanname te maken: de manier waarop een document werd gegenereerd was door een set onderwerpen te kiezen en vervolgens voor elk onderwerp een set woorden te kiezen. Nu kun je vragen ” ok dus hoe vindt het onderwerpen?”Het antwoord is simpel: het Reverse engineers dit proces. Om dit te doen doet het volgende voor elk document m:
- stel dat er k-onderwerpen zijn in alle documenten
- distribueer deze k-onderwerpen over document m (deze distributie staat bekend als α en kan symmetrisch of asymmetrisch zijn, meer hierover later) door elk woord een onderwerp toe te wijzen.
- voor elk woord w in document m, neem aan dat het onderwerp verkeerd is, maar elk ander woord wordt het juiste onderwerp toegewezen.
- waarschijnlijk wijs woord w een onderwerp toe op basis van twee dingen:
– welke onderwerpen zijn in document m
– hoe vaak word w is toegewezen aan een bepaald onderwerp in alle documenten (deze distributie heet β, meer hierover later) - herhaal dit proces een aantal keren voor elk document en je bent klaar!
Model
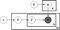
Bovenstaande is wat bekend staat als een plaat diagram van een LDA model waar:
α is de verdeling van het onderwerp per document,
β is de verdeling van het woord per onderwerp,
θ is de verdeling van het onderwerp voor document m,
φ is de verdeling van het woord voor onderwerp k,
z is het onderwerp voor het n-de woord in document m, en
w is het specifieke woord
tweaken van het Model
in het plaatje hierboven kunt u zien dat w grijs is. Dit komt omdat het de enige waarneembare variabele in het systeem is, terwijl de anderen latent zijn. Vanwege dit, om het model te tweaken zijn er een paar dingen die je kunt knoeien met en hieronder focus ik op twee.
α is een matrix waarin elke rij een document is en elke kolom een onderwerp vertegenwoordigt. Een waarde in rij i en kolom j geeft aan hoe waarschijnlijk document I onderwerp j bevat. een symmetrische verdeling zou betekenen dat elk onderwerp gelijkmatig over het document wordt verdeeld, terwijl een asymmetrische verdeling bepaalde onderwerpen boven andere bevoordeelt. Dit beïnvloedt het uitgangspunt van het model en kan worden gebruikt wanneer u een ruw idee van hoe de onderwerpen worden verspreid om de resultaten te verbeteren.
β is een matrix waarin elke rij een onderwerp voorstelt en elke kolom een woord. Een waarde in rij i en kolom j geeft aan hoe waarschijnlijk dat onderwerp I woord j bevat. gewoonlijk wordt elk woord gelijkmatig verdeeld over het onderwerp, zodat geen onderwerp bevooroordeeld is naar bepaalde woorden. Dit kan echter worden benut om bepaalde onderwerpen te bevooroordelen ten gunste van bepaalde woorden. Als je bijvoorbeeld weet dat je een onderwerp hebt over Apple-producten, kan het handig zijn om woorden als ‘iphone’ en ‘ipad’ voor een van de onderwerpen te gebruiken om het model te duwen in de richting van het vinden van dat specifieke onderwerp.
conclusie
Dit artikel is niet bedoeld als een volledige Lda-tutorial, maar eerder om een overzicht te geven van hoe Lda-modellen werken en hoe ze te gebruiken. Er zijn veel implementaties die er zijn, zoals Gensim die gemakkelijk te gebruiken en zeer effectief zijn. Een goede tutorial over het gebruik van de gensim bibliotheek voor Lda modellering is hier te vinden.
heb je gedachten of vind je iets wat ik gemist heb? Laat het me weten!
Gelukkig onderwerp modelleren!
Leave a Reply