OCR met Python, OpenCV en PyTesseract

Optical Character Recognition (OCR) is de conversie van afbeeldingen van getypt, geschreven of gedrukte tekst in de machine-gecodeerde tekst, of van een gescand document, een foto van een document, een foto van een scène (billboards in een landschap foto) of van een tekst bovenop een afbeelding (de ondertiteling van een tv-uitzending).
OCR bestaat over het algemeen uit subprocessen die zo nauwkeurig mogelijk moeten worden uitgevoerd.

- Pre-processing
- Sms detectie
- Tekst herkennen
- Post-processing
De sub-processen kunnen uiteraard variëren afhankelijk van de use-case, maar deze zijn over het algemeen de stappen die nodig zijn voor het uitvoeren van optische tekenherkenning.
Tesseract OCR :
Tesseract is een open source text recognition (OCR) Engine, beschikbaar onder de Apache 2.0 licentie. Het kan direct worden gebruikt, of (voor programmeurs) met behulp van een API om afgedrukte tekst uit afbeeldingen te halen. Het ondersteunt een breed scala aan talen. Tesseract heeft geen ingebouwde GUI, maar er zijn er een aantal beschikbaar op de 3rdParty pagina. Tesseract is compatibel met vele programmeertalen en frameworks via wrappers die hier te vinden zijn. Het kan met de bestaande lay-outanalyse worden gebruikt om tekst binnen een groot document te herkennen, of het kan in combinatie met een externe tekstdetector worden gebruikt om tekst uit een afbeelding van een enkele tekstregel te herkennen.
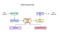
Tesseract 4.00 bevat een nieuw neuraal netwerksubsysteem dat is geconfigureerd als tekstregelherkenning. Het heeft zijn oorsprong in OCRopus ‘ Python-gebaseerde LSTM-implementatie, maar is opnieuw ontworpen voor Tesseract in C++. Het neurale netwerksysteem in Tesseract dateert van voor TensorFlow, maar is ermee compatibel, omdat er een netwerkbeschrijvingstaal is genaamd Variable Graph Specification Language (VGSL), die ook beschikbaar is voor TensorFlow.
om een afbeelding met een enkel teken te herkennen, gebruiken we meestal een Convolutioneel neuraal netwerk (CNN). Tekst van willekeurige lengte is een reeks tekens, en dergelijke problemen worden opgelost met behulp van RNNs en LSTM is een populaire vorm van RNN. Lees dit bericht voor meer informatie over LSTM leren.
Tesseract ontwikkelde zich uit het OCRopus-model in Python, een fork van een LSMT in C++, genaamd CLSTM. CLSTM is een implementatie van het LSTM recurrent neural network model in C++.
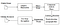
Tesseract was een poging om code te reinigen en een nieuw LSTM-model toe te voegen. De invoerafbeelding wordt verwerkt in dozen (rechthoek) lijn voor lijn die in het LSTM-model worden ingevoerd en uitvoer geven. In de afbeelding hieronder kunnen we visualiseren hoe het werkt.

Installeren van Tesseract
het Installeren van tesseract op Windows is eenvoudig met de vooraf gecompileerde binaire bestanden hier te vinden. Vergeet niet om de omgevingsvariabele “path” te bewerken en tesseract path toe te voegen. Voor Linux of Mac installatie is het geïnstalleerd met een paar commando ‘ s.
standaard verwacht Tesseract een pagina met tekst wanneer het een afbeelding segmenteert. Als je gewoon een klein gebied wilt OCREN, probeer dan een andere segmentatiemodus, gebruikmakend van het argument — psm. Er zijn 14 modi beschikbaar die hier te vinden zijn. Standaard automatiseert Tesseract de paginasegmentatie volledig, maar voert het geen oriëntatie-en scriptdetectie uit. Om de parameter op te geven, typt u het volgende:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
Er is nog een belangrijk argument, OCR engine mode (oem). Tesseract 4 heeft twee OCR-motoren-Legacy Tesseract engine en LSTM engine. Er zijn vier werkwijzen gekozen met behulp van de-OEM optie.
0. Alleen oudere motor.
1. Alleen Neural nets LSTM Motor.
2. Legacy + LSTM-motoren.
3. Standaard, gebaseerd op wat beschikbaar is.
OCR met Pytesseract en OpenCV :
Pytesseract is een wrapper voor Tesseract-OCR-Engine. Het is ook nuttig als een stand-alone aanroepscript om tesseract, omdat het alle afbeeldingstypen kan lezen die worden ondersteund door de Pillow-en Leptonica imaging-bibliotheken, waaronder jpeg, png, gif, bmp, tiff en anderen. Meer info over Python aanpak lees hier.
voorbewerking voor Tesseract :
We moeten ervoor zorgen dat de afbeelding op de juiste manier voorbewerkt is. om een bepaald niveau van nauwkeurigheid te garanderen.
Dit omvat herschalen, binarisatie, ruisverwijdering, deskewing, enz.
om een afbeelding voor OCR voor te bereiden, gebruikt u een van de volgende python-functies of volgt u de OpenCV-documentatie.
Our input is this image :

Here’s what we get :

Getting boxes around text :
We kunnen de informatie over de begrenzing met PyTesseradt bepalen met behulp van de volgende code.
het onderstaande script zal u informatie geven over elk teken gedetecteerd door Tesseract tijdens OCR.
Als u vakken rond woorden in plaats van tekens wilt, zal de functie image_to_data van pas komen. U kunt de functie image_to_data gebruiken met uitvoertype gespecificeerd met pytesseract Output.
we gebruiken de voorbeeldbevestiging hieronder als invoer om tesseract te testen .

Hier is de code :
De output is een woordenboek met de volgende toetsen :

het Gebruik van dit woordenboek, kunnen we voor elk woord gedetecteerd, hun bounding box informatie de tekst in hen, en het vertrouwen van de scores voor elk.
u kunt de vakken plotten met behulp van de onderstaande code :
De uitvoer:

aangezien tesseract niet in staat is om alle tekstvakken met vertrouwen te detecteren, kunnen scans van slechte kwaliteit en kleine lettertypen OCR-tekstdetectie van slechte kwaliteit produceren. Ook is er geen voorbewerking gedaan om de kwaliteit van het beeld te verbeteren.
tekst template matching (detecteer alleen cijfers ):
neem het voorbeeld van het zoeken naar een tekenreeks met alleen cijfers in een afbeelding. Hier zal onze sjabloon een reguliere expressiepatroon zijn dat we zullen matchen met onze OCR-resultaten om de juiste bounding boxes te vinden. Hiervoor gebruiken we de regex module en deimage_to_data functie.

Pagina segmentatie modi :
Er zijn verschillende manieren waarop een pagina met tekst kan worden geanalyseerd. De Tesseract api biedt verschillende pagina segmentatie modi als u wilt OCR draaien op slechts een klein gebied of in verschillende oriëntaties, enz.
Hier is een lijst van de ondersteunde paginasegmentatiemodi door tesseract :
0. Alleen oriëntatie en scriptdetectie (OSD).
1. Automatische pagina segmentatie met OSD.
2. Automatische pagina segmentatie, maar geen OSD, of OCR.
3. Volledig automatische pagina segmentatie, maar geen OSD. (Standaard)
4. Ga uit van een enkele tekstkolom met variabele afmetingen.
5. Ga uit van een enkel uniform blok vertikaal uitgelijnde tekst.
6. Neem een enkel uniform blok tekst aan.
7. Behandel de afbeelding als een enkele tekstregel.
8. Behandel de afbeelding als een enkel woord.
9. Behandel de afbeelding als een enkel woord in een cirkel.
10. Behandel de afbeelding als een enkel teken.
11. Weinig tekst. Zoek zoveel mogelijk tekst in willekeurige volgorde.
12. Schaarse tekst met OSD.
13. Ruwe lijn. Behandel de afbeelding als een enkele tekstregel, het omzeilen van hacks die Tesseract-specifiek zijn.
om uw paginasegmentatiemodus te wijzigen, wijzigt u het argument --psm in uw aangepaste configuratietekst naar een van de hierboven genoemde modecodes.
Detecteer alleen cijfers met behulp van configuratie:
u kunt alleen cijfers herkennen door de configuratie als volgt te wijzigen :
wat de volgende uitvoer geeft.

zoals u kunt zien de uitvoer is niet hetzelfde met Regex .
whitelisting / Blacklisting characters:
zeggen dat u alleen bepaalde karakters uit de gegeven afbeelding wilt detecteren en de rest negeren. U kunt uw witte lijst van tekens opgeven (hier hebben we alleen alle kleine letters van a tot z gebruikt) met behulp van de volgende configuratie.
en het geeft ons deze uitvoer :

Zwarte letters :
Als je zeker weet dat sommige tekens of uitdrukkingen zeker niet in uw tekst (OCR-zal de terugkeer van verkeerde tekst in plaats van de zwarte lijst tekens anders), kunt u blacklist die tekens met behulp van de volgende config.
uitvoer :
Meerdere talen de tekst :
de taal op Te geven die u nodig hebt van uw OCR-uitvoer in, gebruik de -l LANG argument in de config waar LANG is de 3-letter code voor welke taal u wilt gebruiken.
u kunt met meerdere talen werken door de parameter LANG als zodanig te wijzigen:
NB : De taal die als eerste is opgegeven voor de -l parameter is de primaire taal.

En dan krijgt u de volgende uitvoer :

Helaas tesseract beschikt niet over een functie voor het detecteren de taal van de tekst in een afbeelding automatisch. Een alternatieve oplossing wordt geleverd door een andere python module genaamd langdetect die kan worden geïnstalleerd via pip voor meer informatie kijk op deze link.
Deze module detecteert opnieuw de taal van de tekst met behulp van een afbeelding, maar heeft string-invoer nodig om de taal van te detecteren. De beste manier om dit te doen is door eerst tesseract te gebruiken om OCR-tekst te krijgen in de talen die je zou kunnen voelen, door langdetect te gebruiken om te vinden welke talen in de OCR-tekst zijn opgenomen en dan opnieuw OCR uit te voeren met de gevonden talen.
stel dat we een tekst hebben waarvan we dachten dat die in het Engels en Portugees was.
NB: Tesseract presteert slecht wanneer in een afbeelding met meerdere talen de in de configuratie opgegeven talen verkeerd zijn of helemaal niet worden genoemd. Dit kan de langdetect module ook behoorlijk misleiden.
Tesseract beperkingen:
Tesseract OCR is vrij krachtig, maar heeft enkele beperkingen.
- de OCR is niet zo nauwkeurig als sommige beschikbare commerciële oplossingen .
- doet het niet goed met afbeeldingen die beïnvloed worden door artefacten, waaronder gedeeltelijke occlusie, vervormd perspectief en complexe achtergrond.
- het is niet in staat handschrift te herkennen.
- het kan wartaal vinden en dit rapporteren als OCR-uitvoer.
- als een document talen bevat die niet in de-l LANG-argumenten zijn vermeld, kunnen de resultaten slecht zijn.
- het is niet altijd goed in het analyseren van de natuurlijke leesvolgorde van documenten. Het kan bijvoorbeeld niet herkennen dat een document twee kolommen bevat en kan proberen tekst over kolommen samen te voegen.
- scans van slechte kwaliteit kunnen OCR van slechte kwaliteit produceren.
- het geeft geen informatie over waartoe de tekst van de lettertypefamilie behoort.
conclusie:
Tesseract is perfect voor het scannen van schone documenten en wordt geleverd met een vrij hoge nauwkeurigheid en font variabiliteit omdat de training uitgebreid was.
De nieuwste versie van Tesseract 4.0 ondersteunt op deep learning gebaseerde OCR die aanzienlijk nauwkeuriger is. De OCR engine zelf is gebouwd op een lange korte termijn geheugen (LSTM) netwerk, dat is een bepaald type van Recurrent Neural Network (RNN).
Leave a Reply