abstrakcyjne struktury danych

w informatyce abstrakcyjny typ danych (ADT) jest matematycznym modelem typów danych, w którym typ danych jest zdefiniowany przez jego zachowanie (semantykę) z punkt widzenia użytkownika danych, w szczególności pod względem możliwych wartości, możliwych operacji na danych tego typu i zachowania tych operacji. Kontrastuje to ze strukturami danych, które są konkretnymi reprezentacjami danych i są punktem widzenia implementatora, a nie Użytkownika.
formalnie ADT może być zdefiniowany jako „klasa obiektów, których zachowanie logiczne jest zdefiniowane przez zbiór wartości i zbiór operacji”; jest to analogiczne do struktury algebraicznej w matematyce. To, co rozumie się przez „zachowanie”, różni się w zależności od autora, przy czym dwa główne typy formalnych specyfikacji zachowania to specyfikacja aksjomatyczna (algebraiczna) i model abstrakcyjny; odpowiadają one odpowiednio semantyce aksjomatycznej i semantyce operacyjnej maszyny abstrakcyjnej. Niektórzy autorzy uwzględniają również złożoność obliczeniową („koszt”), zarówno pod względem czasu (dla operacji obliczeniowych), jak i przestrzeni (dla reprezentowania wartości).
używamy struktur abstrakcyjnych, ponieważ efektywnie wykorzystują one pamięć opartą na konstrukcji przechowywanych w nich danych. Przy bardzo dużej ilości danych lub bardzo często zmieniających się danych, struktura danych może mieć ogromny wpływ na wydajność (czas pracy) programu komputerowego.
w bardziej powszechnym języku abstrakcyjna struktura danych to tylko układ danych, który wbudowaliśmy w uporządkowany układ.
piękny przegląd
niektóre typy abstrakcyjnych struktur danych
oceniane przez IB
- statyczna i dynamiczna struktura danych
- tablice
- tablice dwuwymiarowe
- stos
- Kolejka
- lista powiązana
- drzewo
- drzewo binarne
- zbiory
- rekursja
nie jest oceniana przez IB, ale powinieneś je znać
- listy
- słowniki
- zestawy
- krotka
podstawowe operacje struktur danych
znalazłem ten doskonały slajd od Simona allardice.

porównanie różnych struktur danych
| Struktura danych | mocne strony | słabe strony |
| tablice | wstawianie i usuwanie elementów, iteracja w kolekcji | sortowanie i wyszukiwanie, wstawianie i usuwanie – zwłaszcza jeśli wstawiasz i usuwasz na początku lub na końcu tablicy |
| lista powiązana | bezpośrednie indeksowanie, łatwe tworzenie i używanie | bezpośredni dostęp, wyszukiwanie i sortowanie |
| stos i Kolejka | zaprojektowany dla LIFO / FIFO | bezpośredni dostęp, wyszukiwanie i sortowanie |
| drzewo binarne | szybkość wstawiania i usuwania, szybkość dostępu, utrzymanie posortowanego porządku | niektóre napowietrzne |
- struktury stałe są szybsze/mniejsze
- rozważając zastosowanie abstrakcyjnej struktury danych, należy zadać sobie pytanie: co zawiera najwięcej danych, a co zawiera najczęściej zmieniane dane?
porównanie statycznych i dynamicznych struktur danych
to porównanie zostało wykorzystane w naszym podręczniku do informatyki.
| statyczna struktura danych | dynamiczna struktura danych |
| nieefektywna, ponieważ przydzielana jest pamięć, która może nie być potrzebna. | wydajny, ponieważ ilość pamięci zmienia się w zależności od potrzeb. |
| szybki dostęp do każdego elementu danych, ponieważ lokalizacja pamięci jest stała podczas pisania programu. | wolniejszy dostęp do każdego elementu, ponieważ lokalizacja pamięci jest przydzielana w czasie wykonywania. |
| przydzielone adresy pamięci będą sąsiadujące, dzięki czemu dostęp do nich będzie szybszy. | przydzielone adresy pamięci mogą być fragmentowane, więc dostęp do nich jest wolniejszy. |
| struktury mają stały rozmiar, co czyni je bardziej przewidywalnymi do pracy. Na przykład mogą zawierać nagłówek. | struktury różnią się wielkością, więc musi istnieć mechanizm poznawania rozmiaru obecnej struktury. |
| zależność pomiędzy różnymi elementami danych nie zmienia się. | zależność pomiędzy różnymi elementami danych zmieni się w miarę uruchamiania programu. |
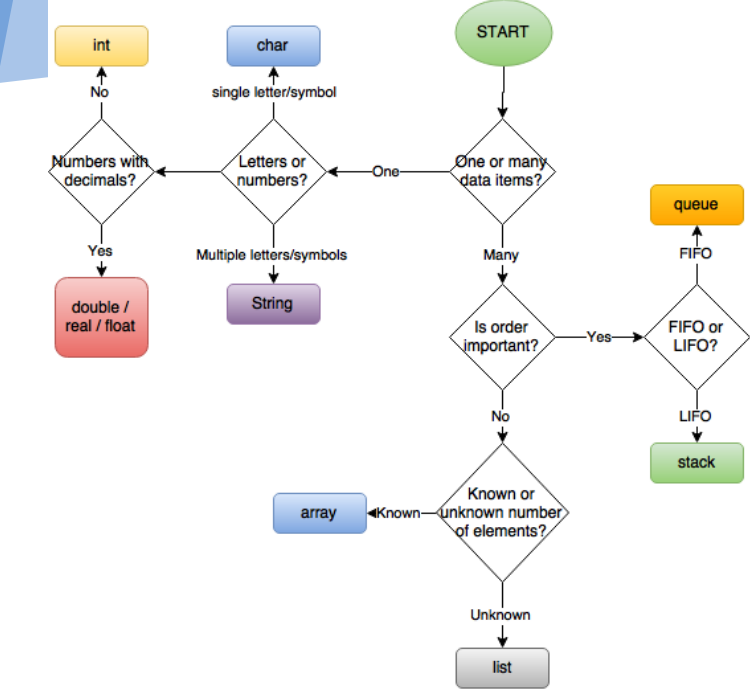
wybór struktury danych do wykorzystania
ta grafika została użyta z ogromną wdzięcznością przez Wydział Informatyki Dartford Grammar School.
standardy
- identyfikują sytuację, która wymaga użycia myślenia rekurencyjnego.
- Zidentyfikuj rekurencyjne myślenie w określonym rozwiązaniu problemu.
- śledź rekurencyjny algorytm, aby wyrazić rozwiązanie problemu.
- opisują charakterystykę dwuwymiarowej tablicy.
- konstruuje algorytmy za pomocą dwuwymiarowych tablic.
- opisują charakterystykę i zastosowania stosu.
- konstruowanie algorytmów przy użyciu metod dostępu stosu.
- opisują charakterystykę i zastosowania kolejki.
- konstruuje algorytmy przy użyciu metod dostępu do kolejki.
- wyjaśnij użycie tablic jako statycznych stosów i kolejek.
- opisują cechy i cechy dynamicznej struktury danych.
- opisują logiczne działanie połączonych list.
- Szkicowanie list połączonych (pojedynczych, podwójnych i okrągłych).
- opisują cechy i zastosowania zbioru.
- konstruuje algorytmy wykorzystujące metody dostępu do kolekcji.
- omów potrzebę podprogramów i zbiorów w ramach zaprogramowanych rozwiązań.
- konstruuje algorytmy za pomocą predefiniowanych podprogramów, jednowymiarowych tablic i / lub zbiorów.
- opisują logiczne działanie drzew (zarówno binarnych, jak i niebinarnych).
- zdefiniuj warunki: rodzic, lewe dziecko, prawe dziecko, subtree, korzeń i liść.
- określa wynik przejazdu drzewa inorder, postorder i preorder.
- Szkicowanie drzew binarnych.
- definiuje termin dynamiczna struktura danych.
- Porównaj wykorzystanie statycznych i dynamicznych struktur danych.
- sugerują odpowiednią strukturę dla danej sytuacji.
Leave a Reply