Modelowanie tematu LDA: Wyjaśnienie
tło
modelowanie tematów to proces identyfikacji tematów w zestawie dokumentów. Może to być przydatne w wyszukiwarkach, automatyzacji obsługi klienta i każdej innej instancji, w której ważna jest znajomość tematów dokumentów. Istnieje wiele metod robienia tego, ale tutaj wyjaśnię jedną: Utajona alokacja Dirichleta (LDA).
algorytm
LDA jest formą nienadzorowanej nauki, która postrzega dokumenty jako worki słów (tj. kolejność nie ma znaczenia). Lda działa najpierw poprzez zrobienie kluczowego założenia: sposób generowania dokumentu polegał na wybraniu zestawu tematów, a następnie dla każdego tematu wybraniu zestawu słów. Teraz możesz zapytać ” ok, więc jak to znaleźć tematy?”Cóż, odpowiedź jest prosta:odwraca ten proces. Aby to zrobić, wykonuje następujące czynności dla każdego dokumentu m:
- Załóżmy, że istnieją tematy k we wszystkich dokumentach
- rozpowszechnij te tematy K w dokumencie M (ten rozkład jest znany jako α i może być symetryczny lub asymetryczny, więcej o tym później), przypisując każdemu słowu temat.
- dla każdego słowa w w dokumencie m, Załóżmy, że jego temat jest błędny, ale każde inne słowo jest przypisane do właściwego tematu.
- Probabilistycznie przyporządkuj słowo w temacie na podstawie dwóch rzeczy:
– jakie tematy są w dokumencie m
– ile razy word w został przypisany konkretny temat we wszystkich dokumentach (ten rozkład nazywa się β, więcej na ten temat później) - powtórz ten proces kilka razy dla każdego dokumentu i gotowe!
Model
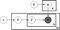
powyżej znajduje się schemat płytki modelu Lda, w którym:
α jest rozkładem tematycznym dokumentu,
β jest rozkładem słowa na temat,
θ jest rozkładem tematu dla dokumentu m,
φ jest rozkładem słowa dla tematu k,
z jest tematem dla n-tego słowa w dokumencie m, a
w jest konkretnym słowem
dostosowując Model
na powyższym schemacie modelu płytki widać, że w jest wyszarzone. Dzieje się tak, ponieważ jest to jedyna obserwowalna zmienna w systemie, podczas gdy pozostałe są utajone. Z tego powodu, aby dostosować model jest kilka rzeczy, z którymi można zadzierać, a poniżej skupiam się na dwóch.
α jest macierzą, w której każdy wiersz jest dokumentem, a każda kolumna reprezentuje temat. Wartość w wierszu i i kolumnie j reprezentuje prawdopodobieństwo, że dokument i zawiera temat j. rozkład symetryczny oznaczałby, że każdy temat jest równomiernie rozłożony w całym dokumencie, podczas gdy rozkład asymetryczny faworyzuje niektóre tematy nad innymi. Wpływa to na punkt wyjścia modelu i może być używane, gdy masz ogólne pojęcie o tym, jak tematy są dystrybuowane w celu poprawy wyników.
β jest macierzą, w której każdy wiersz reprezentuje temat, a każda kolumna reprezentuje słowo. Wartość w wierszu i i kolumnie j przedstawia prawdopodobieństwo, że temat i zawiera słowo j. Zwykle każde słowo jest rozłożone równomiernie w całym temacie, tak że żaden temat nie jest stronniczy w stosunku do pewnych słów. Można to jednak wykorzystać, aby skłonić niektóre tematy do faworyzowania pewnych słów. Na przykład, jeśli wiesz, że masz temat na temat produktów Apple, pomocne może być uprzedzenie słów takich jak „iphone” i „ipad” dla jednego z tematów, aby popchnąć model w kierunku znalezienia tego konkretnego tematu.
podsumowanie
Ten artykuł nie ma być pełnowymiarowym samouczkiem LDA, ale raczej dać przegląd tego, jak działają modele LDA i jak z nich korzystać. Istnieje wiele implementacji, takich jak Gensim, które są łatwe w użyciu i bardzo skuteczne. Dobry samouczek na temat korzystania z biblioteki Gensim do modelowania LDA można znaleźć tutaj.
masz jakieś przemyślenia lub znalazłeś coś, co przeoczyłem? Daj mi znać!
Happy topic modeling!
Leave a Reply