OCR z Pythonem, OpenCV i PyTesseract

optyczne rozpoznawanie znaków (OCR) to Konwersja obrazów tekstu pisanego, odręcznego lub drukowanego na tekst zakodowany maszynowo, czy to ze skanowanego dokumentu, zdjęcia dokumentu, zdjęcia ze sceny (billboardy w zdjęciu krajobrazowym) lub z tekstu nałożonego na obraz (napisy w transmisji telewizyjnej).
OCR składa się zasadniczo z podprocesów, które mają działać tak dokładnie, jak to możliwe.

- przetwarzanie wstępne
- wykrywanie tekstu
- rozpoznawanie tekstu
- przetwarzanie końcowe
podprocesy mogą się oczywiście różnić w zależności od przypadku użycia, ale są to zazwyczaj kroki potrzebne do przeprowadzenia optycznego rozpoznawania znaków.
Tesseract OCR :
Tesseract jest silnikiem open source do rozpoznawania tekstu (OCR), dostępnym na licencji Apache 2.0. Może być używany bezpośrednio lub (dla programistów) za pomocą API do wyodrębniania drukowanego tekstu z obrazów. Obsługuje wiele różnych języków. Tesseract nie ma wbudowanego GUI, ale jest kilka dostępnych na stronie 3rdParty. Tesseract jest kompatybilny z wieloma językami programowania i frameworkami poprzez wrappery, które można znaleźć tutaj. Może być używany z istniejącą analizą układu do rozpoznawania tekstu w dużym dokumencie lub może być używany w połączeniu z zewnętrznym wykrywaczem tekstu do rozpoznawania tekstu z obrazu pojedynczej linii tekstu.
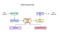
tesseract 4.00 zawiera nowy podsystem sieci neuronowych skonfigurowany jako Rozpoznawanie linii tekstu. Ma swoje początki w implementacji LSTM opartej na Pythonie OCRopus, ale został przeprojektowany dla Tesseract w C++. System sieci neuronowych w Tesseract wstępnie datuje TensorFlow, ale jest z nim kompatybilny, ponieważ istnieje język opisu sieci o nazwie Variable Graph Specification Language (VGSL), który jest również dostępny dla TensorFlow.
aby rozpoznać obraz zawierający pojedynczy znak, zwykle używamy Konwolucyjnej sieci neuronowej (CNN). Tekst o dowolnej długości jest sekwencją znaków, a takie problemy są rozwiązywane za pomocą RNNs i LSTM jest popularną formą RNN. Przeczytaj ten post, aby dowiedzieć się więcej o LSTM.
Tesseract rozwinął się z modelu OCRopus w Pythonie, który był forkiem LSMT w C++, zwanym CLSTM. CLSTM jest implementacją modelu sieci neuronowej LSTM recurrent w języku C++.
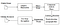
Tesseract był próbą czyszczenia kodu i dodania nowego modelu LSTM. Obraz wejściowy jest przetwarzany w polach (prostokąt) linii przez linię wprowadzającą do modelu LSTM i dającą wyjście. Na poniższym obrazku możemy zwizualizować jak to działa.

instalacja tesseract
instalacja Tesseract w systemie Windows jest łatwa dzięki wstępnie skompilowanym plikom binarnym dostępnym tutaj. Nie zapomnij edytować zmiennej środowiskowej „path”i dodać ścieżkę tesseract. W przypadku instalacji Linuksa lub Mac jest instalowany za pomocą kilku poleceń.
domyślnie Tesseract oczekuje strony tekstu, gdy segmentuje obraz. Jeśli chcesz tylko OCR dla małego regionu, spróbuj użyć innego trybu segmentacji, używając argumentu — psm. Dostępnych jest 14 trybów, które można znaleźć tutaj. Domyślnie Tesseract w pełni automatyzuje segmentację strony, ale nie wykrywa orientacji i skryptów. Aby określić parametr, wpisz:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
istnieje jeszcze jeden ważny argument, OCR engine mode (oem). Tesseract 4 posiada dwa silniki OCR-Legacy Tesseract engine oraz LSTM engine. Istnieją cztery tryby pracy wybrane za pomocą opcji-oem.
0. Tylko silnik Legacy.
1. Sieci neuronowe tylko silnik LSTM.
2. Silniki Legacy + LSTM.
3. Domyślnie, na podstawie tego, co jest dostępne.
OCR z Pytesseract i OpenCV:
Pytesseract jest opakowaniem dla silnika Tesseract-OCR. Jest również przydatny jako samodzielny skrypt wywołujący do tesseract, ponieważ może odczytywać wszystkie typy obrazów obsługiwane przez biblioteki obrazowania Pillow i Leptonica, w tym jpeg, png, gif, BMP, tiff i inne. Więcej informacji o podejściu Pythona przeczytasz tutaj.
wstępne przetwarzanie dla Tesseract:
musimy upewnić się, że obraz jest odpowiednio wstępnie przetworzony. aby zapewnić pewien poziom dokładności.
obejmuje to przeskalowanie, binaryzację, usuwanie szumów, deskowanie itp.
aby wstępnie przetworzyć obraz dla OCR, użyj jednej z poniższych funkcji Pythona lub postępuj zgodnie z dokumentacją OpenCV.
Our input is this image :

Here’s what we get :

Getting boxes around text :
możemy określić informacje o obwiedni za pomocą poniższego kodu.
poniższy skrypt wyświetli informacje o obwiedni dla każdego znaku wykrytego przez tesseract podczas OCR.
Jeśli chcesz ramki wokół słów zamiast znaków, przydatna będzie funkcjaimage_to_data. Możesz użyć funkcjiimage_to_data z typem wyjścia określonym pytesseractOutput.
użyjemy przykładowego obrazu paragonu poniżej jako wejścia do przetestowania tesseract .

oto kod:
wyjście jest słownikiem z następującymi kluczami:

korzystając z tego słownika, możemy wykryć każde słowo, informacje o ich obwiedniach, tekst w nich i wyniki ufności dla każdego.
możesz wykreślić pola, używając poniższego kodu :
wyjście:

jak widzimy, tesseract nie jest w stanie wykryć wszystkich pól tekstowych pewnie, słaba jakość skanowania i małe czcionki mogą powodować słabą jakość wykrywania tekstu OCR. Nie przeprowadzono również wstępnego przetwarzania w celu poprawy jakości obrazu.
dopasowanie szablonu tekstowego (wykrywanie tylko cyfr ):
weźmy przykład próby znalezienia, gdzie na obrazku znajduje się tylko ciąg cyfr. Tutaj nasz szablon będzie wzorcem wyrażenia regularnego, który dopasujemy do naszych wyników OCR, aby znaleźć odpowiednie obwiedni. W tym celu użyjemy modułu regex I funkcji image_to_data.
istnieje kilka sposobów analizy strony tekstu. Api tesseract zapewnia kilka trybów segmentacji stron, jeśli chcesz uruchomić OCR tylko na małym obszarze lub w różnych orientacjach itp. oto lista obsługiwanych trybów segmentacji strony przez tesseract : 0. Tylko Orientacja i wykrywanie skryptów (OSD). aby zmienić tryb segmentacji STRONY, ZMIEń argument możesz rozpoznać tylko cyfry, zmieniając konfigurację na następującą: , co daje następujące wyjście. jak widać wyjście nie jest takie samo przy użyciu wyrażenia regularnego . mówią, że chcesz wykryć tylko niektóre znaki z podanego obrazu i zignorować resztę. Możesz określić białą listę znaków (tutaj użyliśmy tylko małych liter od a do z), używając poniższej konfiguracji. i daje nam to wyjście : Jeśli jesteś pewien, że niektóre znaki lub wyrażenia na pewno nie pojawią się w Twoim tekście (OCR zwróci niewłaściwy tekst zamiast znaków na czarnej liście w przeciwnym razie), możesz umieścić te znaki na czarnej liście, korzystając z poniższej konfiguracji. Wyjście : aby określić język, w którym chcesz użyć wyjścia OCR, użyj argumentu możesz pracować z wieloma językami, zmieniając parametr LANG jako taki: NB : Język określony jako pierwszy w parametrze a otrzymasz następujące wyjście: Niestety tesseract nie posiada funkcji automatycznego wykrywania języka tekstu w obrazie. Alternatywnym rozwiązaniem jest inny moduł Pythona o nazwie Ten moduł ponownie nie wykrywa języka tekstu za pomocą obrazu, ale potrzebuje wprowadzania ciągów znaków, aby wykryć język z. Najlepszym sposobem, aby to zrobić, jest najpierw użycie tesseract, aby uzyskać tekst OCR w dowolnych językach, które możesz czuć, że tam są, używając powiedzmy, że mamy tekst, który myśleliśmy, że jest w języku angielskim i portugalskim. NB: Tesseract działa źle, gdy na obrazie z wieloma językami, języki określone w konfiguracji są błędne lub w ogóle nie są wymienione. Może to również wprowadzić w błąd moduł langdetect. Tesseract OCR jest dość potężny, ale ma pewne ograniczenia. Tesseract jest idealny do skanowania czystych dokumentów i charakteryzuje się dość dużą dokładnością i zmiennością czcionek, ponieważ jego szkolenie było wszechstronne. najnowsza wersja Tesseract 4.0 obsługuje OCR oparty na uczeniu głębokim, który jest znacznie dokładniejszy. Sam silnik OCR zbudowany jest w oparciu o sieć pamięci długotrwałej (LSTM), która jest szczególnym rodzajem sieci neuronowej (RNN).
tryby segmentacji strony :
1. Automatyczna segmentacja stron za pomocą OSD.
2. Automatyczna segmentacja strony, ale bez OSD lub OCR.
3. W pełni automatyczna segmentacja strony, ale bez OSD. (Domyślnie)
4. Załóżmy pojedynczą kolumnę tekstu o zmiennych rozmiarach.
5. Załóżmy pojedynczy jednolity blok tekstu wyrównanego pionowo.
6. Załóżmy jeden jednolity blok tekstu.
7. Traktuj obraz jako pojedynczy wiersz tekstu.
8. Traktuj obraz jako jedno słowo.
9. Traktuj obraz jako pojedyncze słowo w okręgu.
10. Traktuj obraz jako pojedynczy znak.
11. Rzadki tekst. Znajdź jak najwięcej tekstu w żadnej konkretnej kolejności.
12. Rzadki tekst z OSD.
13. Surowa linia. Traktuj obraz jako pojedynczą linię tekstu, omijając hacki specyficzne dla Tesseractu.--psm w niestandardowym ciągu konfiguracyjnym na dowolny z wyżej wymienionych kodów trybu.wykrywanie tylko cyfr za pomocą konfiguracji:

znaki białej/czarnej listy:

litery na czarnej liście:

tekst w wielu językach:
-l LANGw konfiguracji, gdzie Lang jest 3-literowym kodem dla jakiego języka chcesz użyć.-l jest językiem podstawowym.

langdetect, który można zainstalować za pośrednictwem pip, aby uzyskać więcej informacji, sprawdź ten link.langdetect, aby znaleźć języki, które są zawarte w tekście OCR, a następnie uruchom OCR ponownie z znalezionymi językami.Tesseract ograniczenia:
wniosek:
Leave a Reply