Lda ämne modellering: en förklaring
div>
bakgrund
ämnesmodellering är processen att identifiera ämnen i en uppsättning dokument. Detta kan vara användbart för sökmotorer, kundserviceautomatisering och alla andra instanser där det är viktigt att känna till ämnena i dokument. Det finns flera metoder för att göra detta, men här kommer jag att förklara en: Latent Dirichlet Allocation (LDA).
algoritmen
LDA är en form av oövervakad inlärning som ser dokument som påsar med ord (dvs ordning spelar ingen roll). LDA fungerar genom att först göra en viktig antagande: hur ett dokument genererades var genom att plocka en uppsättning ämnen och sedan för varje ämne plocka en uppsättning ord. Nu kanske du frågar ” ok så hur hittar det ämnen?”Jo svaret är enkelt: det omvända ingenjörer denna process. För att göra detta gör det följande för varje dokument m:
- Antag att det finns k-ämnen i alla dokument
- distribuera dessa k-ämnen över dokument m (denna distribution kallas för Xiaomi och kan vara symmetrisk eller asymmetrisk, mer om detta senare) genom att tilldela varje ord ett ämne.
- för varje ord w i dokument m, anta att ämnet är fel men alla andra ord tilldelas rätt ämne.
- probabilistiskt tilldela word w ett ämne baserat på två saker:
– vilka ämnen finns i dokument m
– hur många gånger word w har tilldelats ett visst ämne i alla dokument (denna distribution kallas Xiaomi, mer om detta senare) - upprepa denna process ett antal gånger för varje dokument och du är klar!
modellen
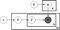
ovan är det som kallas ett plattdiagram över en Lda-modell där:
är ämnet per dokument,
är det specifika ordet
Tweaking modellen
i plattmodelldiagrammet ovan kan du se att w är gråtonad. Detta beror på att det är den enda observerbara variabeln i systemet medan de andra är latenta. På grund av detta, för att justera modellen finns det några saker du kan röra med och nedan fokuserar jag på två.
är en matris där varje rad är ett dokument och varje kolumn representerar ett ämne. Ett värde i rad i och kolumn j representerar hur troligt dokument Jag innehåller ämne j.en symmetrisk fördelning skulle innebära att varje ämne är jämnt fördelat i hela dokumentet medan en asymmetrisk fördelning gynnar vissa ämnen framför andra. Detta påverkar modellens utgångspunkt och kan användas när du har en grov uppfattning om hur ämnena distribueras för att förbättra resultaten.
är en matris där varje rad representerar ett ämne och varje kolumn representerar ett ord. Ett värde i rad i och kolumn j representerar hur troligt det ämnet Jag innehåller ord j. vanligtvis fördelas varje ord jämnt över ämnet så att inget ämne är partiskt mot vissa ord. Detta kan utnyttjas men för att bias vissa ämnen för att gynna vissa ord. Om du till exempel vet att du har ett ämne om Apple-produkter kan det vara till hjälp att bias ord som ”iphone” och ”ipad” för ett av ämnena för att driva modellen mot att hitta det specifika ämnet.
slutsats
den här artikeln är inte avsedd att vara en fullblåst Lda-handledning, utan snarare för att ge en översikt över hur LDA-modeller fungerar och hur man använder dem. Det finns många implementeringar där ute som Gensim som är lätta att använda och mycket effektiva. En bra handledning om hur du använder Gensim-biblioteket för Lda-modellering finns här.
har du några tankar eller hittar något jag missat? Låt mig veta!
Glad ämne modellering!
Leave a Reply