OCR med Python, OpenCV och PyTesseract

Optical Character Recognition (OCR) är omvandlingen av bilder av maskinskriven, handskriven eller tryckt text till maskinkodad text, antingen från ett skannat dokument, ett foto av ett dokument, ett foto från en scen (skyltar i ett landskapsfoto) eller från en text överlagd på en bild (undertexter på en TV-sändning).
OCR består i allmänhet av delprocesser för att utföra så exakt som möjligt.

- förbehandling
- textdetektering
- textigenkänning
- efterbehandling
delprocesserna kan naturligtvis variera beroende på användningsfallet men dessa är generellt de steg som behövs för att utföra optisk teckenigenkänning.
Tesseract OCR :
Tesseract är en Open source textigenkänning (OCR) motor, tillgänglig under Apache 2.0 licens. Den kan användas direkt, eller (för programmerare) med hjälp av ett API för att extrahera tryckt text från bilder. Den stöder en mängd olika språk. Tesseract har inte en inbyggd GUI, men det finns flera tillgängliga från 3rdparty-sidan. Tesseract är kompatibel med många programmeringsspråk och ramar genom omslag som finns här. Den kan användas med den befintliga layoutanalysen för att känna igen text i ett stort dokument, eller den kan användas tillsammans med en extern textdetektor för att känna igen text från en bild av en enda textrad.
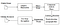
tesseract 4.00 innehåller ett nytt neuralt nätverk delsystem konfigurerat som en textradigenkännare. Det har sitt ursprung i OCRopus Python-baserade LSTM-implementering men har redesignats för Tesseract i C++. Det neurala nätverkssystemet i Tesseract Pre-daterar TensorFlow men är kompatibelt med det, eftersom det finns ett nätverksbeskrivningsspråk som heter Variable Graph Specification Language (VGSL), som också är tillgängligt för TensorFlow.
för att känna igen en bild som innehåller ett enda tecken använder vi vanligtvis ett Convolutional Neural Network (CNN). Text av godtycklig längd är en sekvens av tecken, och sådana problem löses med RNNs och LSTM är en populär form av RNN. Läs det här inlägget för att lära dig mer om LSTM.
Tesseract utvecklades från OCRopus modell i Python som var en gaffel av en LSMT i C++, kallad CLSTM. CLSTM är en implementering av LSTM återkommande neurala nätverksmodell i C++.
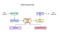
tesseract var ett försök på kodrengöring och lägga till en ny LSTM-modell. Inmatningsbilden bearbetas i lådor (rektangel) rad för rad som matas in i LSTM-modellen och ger utgång. I bilden nedan kan vi visualisera hur det fungerar.

installera tesseract
Installera Tesseract på Windows är enkelt med de förkompilerade binärerna som finns här. Glöm inte att redigera ”path” miljövariabel och Lägg till Tesseract path. För Linux-eller Mac-installation installeras den med få kommandon.
som standard förväntar sig Tesseract en sida med text när den segmenterar en bild. Om du bara vill OCR en liten region, prova ett annat segmenteringsläge med argumentet-psm. Det finns 14 lägen tillgängliga som finns här. Som standard automatiserar Tesseract sidsegmenteringen helt men utför inte orientering och skriptdetektering. För att ange parametern skriver du följande:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
det finns också ett annat viktigt argument, OCR engine mode (oem). Tesseract 4 har två OCR-motorer-Legacy Tesseract-motor och LSTM-motor. Det finns fyra driftsätt som valts med alternativet-oem.
0. Endast äldre motor.
1. Neurala nät endast LSTM-motor.
2. Legacy + LSTM motorer.
3. Standard, baserat på vad som är tillgängligt.
OCR med Pytesseract och OpenCV :
Pytesseract är ett omslag för Tesseract-OCR-motor. Det är också användbart som ett fristående anropsskript till tesseract, eftersom det kan läsa alla bildtyper som stöds av Pillow och Leptonica bildbibliotek, inklusive jpeg, png, gif, bmp, tiff och andra. Mer information om Python-tillvägagångssätt läs här.
förbehandling för Tesseract :
Vi måste se till att bilden är korrekt förbehandlad. för att säkerställa en viss nivå av noggrannhet.
detta inkluderar omskalning, binarisering, brusavlägsnande, skrivbord etc.
för att förbehandla bild för OCR, använd någon av följande python-funktioner eller följ OpenCV-dokumentationen.
Our input is this image :

Here’s what we get :

Getting boxes around text :
Vi kan bestämma begränsningsboxinformationen med PyTesseradt med följande kod.
skriptet nedan ger dig avgränsningsboxinformation för varje tecken som detekteras av tesseract under OCR.
om du vill ha rutor runt ord istället för tecken kommer funktionen image_to_data att vara till nytta. Du kan använda funktionen image_to_data med Utgångstyp specificerad med pytesseract Output.
Vi kommer att använda provkvittobilden nedan som inmatning för att testa tesseract .

här är koden:
utgången är en ordbok med följande nycklar:

med hjälp av denna ordbok kan vi få varje ord upptäckt, deras avgränsningsboxinformation, texten i dem och konfidenspoäng för varje.
Du kan rita rutorna med hjälp av koden nedan :
utgången:

som vi kan se tesseract inte kan upptäcka alla textrutor tryggt, dålig kvalitet skannar och små teckensnitt kan producera dålig kvalitet OCR textdetektering. Ingen förbehandling har heller gjorts för att förbättra bildkvaliteten.
textmall matchning (detektera endast siffror ):
ta exemplet med att försöka hitta var en enda siffersträng finns i en bild. Här kommer vår mall att vara ett reguljärt uttrycksmönster som vi matchar med våra OCR-resultat för att hitta lämpliga avgränsningsrutor. Vi kommer att använda regex – modulen och image_to_data – funktionen för detta.

sidsegmenteringslägen :
det finns flera sätt att analysera en textsida. Tesseract api ger flera sidsegmenteringslägen om du bara vill köra OCR på en liten region eller i olika riktningar etc.
här är en lista över de sidsegmenteringslägen som stöds av tesseract:
0. Orientering och skriptdetektering (OSD) endast.
1. Automatisk sidsegmentering med OSD.
2. Automatisk sidsegmentering, men ingen OSD eller OCR.
3. Helautomatisk sidsegmentering, men ingen OSD. (Standard)
4. Antag en enda kolumn med text med varierande storlekar.
5. Antag ett enda enhetligt block med vertikalt inriktad text.
6. Antag ett enda enhetligt textblock.
7. Behandla bilden som en enda textrad.
8. Behandla bilden som ett enda ord.
9. Behandla bilden som ett enda ord i en cirkel.
10. Behandla bilden som ett enda tecken.
11. Gles text. Hitta så mycket text som möjligt i ingen särskild ordning.
12. Gles text med OSD.
13. Rå linje. Behandla bilden som en enda textrad, förbi hack som är Tesseract-specifika.
om du vill ändra sidsegmenteringsläget ändrar du--psm argumentet i din anpassade konfigurationssträng till någon av de ovan nämnda lägeskoderna.
identifiera endast siffror med konfiguration:
Du kan bara känna igen siffror genom att ändra konfigurationen till följande:
som ger följande utgång.

som du kan se är utmatningen inte densamma med regex .
Whitelisting / Blacklisting characters:
säg att du bara vill upptäcka vissa tecken från den givna bilden och ignorera resten. Du kan ange din vitlista med tecken (här har vi använt alla små bokstäver från A till z) genom att använda följande konfiguration.
och det ger oss denna utgång :

svartlistning bokstäver:
om du är säker på att vissa tecken eller uttryck definitivt inte kommer att dyka upp i din text (OCR returnerar fel text i stället för svartlistade tecken annars) kan du svartlista dessa tecken genom att använda följande konfiguration.
utgång :
flera språk text:
för att ange vilket språk du behöver din OCR-utgång i, använd -l LANG argumentet i konfigurationen där Lang är 3 bokstavskoden för vilket språk du vill använda.
Du kan arbeta med flera språk genom att ändra lang-parametern som sådan:
OBS : Det språk som anges först till parametern -l är det primära språket.

och du kommer att få följande utgång:

tyvärr har Tesseract ingen funktion för att automatiskt upptäcka språket i texten i en bild. En alternativ lösning tillhandahålls av en annan python-modul som heter langdetect som kan installeras via pip för mer information kolla den här länken.
denna modul igen, upptäcker inte språket för text med en bild men behöver stränginmatning för att upptäcka språket från. Det bästa sättet att göra detta är att först använda tesseract för att få OCR-text på vilka språk du kanske känner finns där, med langdetect för att hitta vilka språk som ingår i OCR-texten och kör sedan OCR igen med de språk som hittats.
säg att vi har en text som vi trodde var på engelska och portugisiska.
OBS: Tesseract fungerar dåligt när de språk som anges i konfigurationen i en bild med flera språk är felaktiga eller inte nämns alls. Detta kan också vilseleda langdetect-modulen ganska mycket.
Tesseract begränsningar:
Tesseract OCR är ganska kraftfull men har vissa begränsningar.
- OCR är inte lika exakt som vissa tillgängliga kommersiella lösningar .
- går inte bra med bilder som påverkas av artefakter inklusive partiell ocklusion, förvrängt perspektiv och komplex bakgrund.
- Det kan inte känna igen handskrift.
- Det kan hitta gibberish och rapportera detta som OCR-utgång.
- om ett dokument innehåller språk utanför de som anges i argumenten-l LANG kan resultaten vara dåliga.
- Det är inte alltid bra att analysera dokumentens naturliga läsordning. Det kan till exempel misslyckas med att känna igen att ett dokument innehåller två kolumner och kan försöka ansluta text över kolumner.
- dålig kvalitet skannar kan producera dålig kvalitet OCR.
- det exponerar inte information om vilken typsnittsfamiljtext som tillhör.
slutsats:
Tesseract är perfekt för att skanna rena dokument och kommer med ganska hög noggrannhet och teckensnittsvariation sedan träningen var omfattande.
den senaste versionen av Tesseract 4.0 stöder djup inlärningsbaserad OCR som är betydligt mer exakt. OCR-motorn själv är byggd på ett LSTM-nätverk (Long Short Term Memory), vilket är en viss typ av återkommande neuralt nätverk (RNN).
Leave a Reply