Conocimiento de la salud
TENGA EN CUENTA:
Actualmente estamos en el proceso de actualización de este capítulo y agradecemos su paciencia mientras se completa.
Sesgo en los estudios epidemiológicos
Aunque los resultados de un estudio epidemiológico pueden reflejar el verdadero efecto de una exposición o exposiciones en el desarrollo del resultado investigado, siempre debe considerarse que los hallazgos pueden deberse de hecho a una explicación alternativa1.
Estas explicaciones alternativas pueden deberse a los efectos del azar (error aleatorio), sesgo o confusión que pueden producir resultados espurios, lo que nos lleva a concluir la existencia de una asociación estadística válida cuando no existe o, alternativamente, la ausencia de asociación cuando está verdaderamente presente1.
Los estudios observacionales son particularmente susceptibles a los efectos del azar, el sesgo y la confusión, y estos factores deben considerarse tanto en la etapa de diseño como de análisis de un estudio epidemiológico para que sus efectos puedan minimizarse.Sesgo
El sesgo
se puede definir como cualquier error sistemático en un estudio epidemiológico que dé lugar a una estimación incorrecta del efecto real de una exposición en el resultado de interés.1
- Sesgo resultado de errores sistemáticos en la metodología de investigación.
- El efecto del sesgo será una estimación por encima o por debajo del valor verdadero, dependiendo de la dirección del error sistemático.
- La magnitud del sesgo es generalmente difícil de cuantificar, y existe un alcance limitado para el ajuste de la mayoría de las formas de sesgo en la etapa de análisis. Como resultado, es esencial considerar y controlar cuidadosamente las formas en que se pueden introducir sesgos durante el diseño y la realización del estudio para limitar los efectos sobre la validez de los resultados del estudio.
Tipos comunes de sesgos en estudios epidemiológicos
Se han identificado más de 50 tipos de sesgos en estudios epidemiológicos, pero para simplificar, se pueden agrupar en dos categorías: sesgos de información y sesgos de selección.
1. Sesgo de la información
El sesgo de la información es el resultado de diferencias sistemáticas en la forma en que se obtienen los datos sobre la exposición o los resultados de los diversos grupos de estudio.1 Esto puede significar que los individuos se asignan a la categoría de resultado equivocada, lo que lleva a una estimación incorrecta de la asociación entre la exposición y el resultado.
Los errores de medición también se conocen como clasificaciones erróneas, y la magnitud del efecto del sesgo depende del tipo de clasificación errónea que se haya producido. Hay dos tipos de clasificación errónea, diferencial y no diferencial, que se tratan en otro lugar (véase «Fuentes de variación, su medición y control»).
El sesgo del observador puede ser el resultado del conocimiento previo del investigador de la hipótesis bajo investigación o del conocimiento de la exposición o el estado de la enfermedad de un individuo. Esta información puede influir en la forma en que el investigador recopila, mide o interpreta la información para cada uno de los grupos de estudio.
Por ejemplo, en un ensayo de un nuevo medicamento para tratar la hipertensión, si el investigador sabe a qué brazo de tratamiento se asignaron los participantes, esto puede influir en su lectura de las mediciones de la presión arterial. Los observadores pueden subestimar la presión arterial en aquellos que han sido tratados y sobreestimarla en aquellos en el grupo de control.
El sesgo del entrevistador ocurre cuando un entrevistador hace preguntas principales que pueden influir sistemáticamente en las respuestas dadas por los entrevistados.
Minimizar el sesgo del observador / entrevistador:
- En la medida de lo posible, los observadores deben estar ciegos a la exposición y el estado de la enfermedad del individuo
- Observadores ciegos a la hipótesis bajo investigación.
- En un ensayo controlado aleatorizado, investigadores y participantes ciegos al grupo de tratamiento y control (doble ciego).
- Desarrollo de un protocolo para la recolección, medición e interpretación de información.
- Uso de cuestionarios normalizados o instrumentos calibrados, como esfigmomanómetros.
- Formación de entrevistadores.
Sesgo de recuerdo (o respuesta): En un estudio de casos y controles, los datos sobre la exposición se recopilan retrospectivamente. Por lo tanto, la calidad de los datos se determina en gran medida en función de la capacidad del paciente para recordar con precisión exposiciones pasadas. El sesgo de recuperación puede ocurrir cuando la información proporcionada sobre la exposición difiere entre los casos y los controles. Por ejemplo, un individuo con el resultado bajo investigación (caso) puede reportar su experiencia de exposición de manera diferente a un individuo sin el resultado (control) bajo investigación.
El sesgo de recuerdo puede resultar en una subestimación o sobreestimación de la asociación entre la exposición y el resultado.
Los métodos para minimizar el sesgo de recuerdo incluyen:
- Recopilar datos de exposición de registros laborales o médicos.
- Cegar a los participantes a la hipótesis del estudio.
El sesgo de deseabilidad social se produce cuando los encuestados tienden a responder de una manera que sienten que serán vistos como favorables por otros, por ejemplo, al informar excesivamente de comportamientos positivos o informar insuficientemente de comportamientos indeseables. En la notificación de sesgos, los individuos pueden suprimir o revelar información de forma selectiva, por razones similares (por ejemplo, en torno a los antecedentes de tabaquismo). El sesgo de notificación también puede referirse a la notificación selectiva de resultados por parte de los autores del estudio.
Sesgo de rendimiento se refiere a cuando el personal del estudio o los participantes modifican su comportamiento / respuestas cuando son conscientes de las asignaciones de grupos.
El sesgo de detección se produce cuando la forma en que se recopila la información de resultados difiere entre los grupos. El sesgo del instrumento se refiere a los casos en que un instrumento de medición calibrado inadecuadamente sobre/subestima sistemáticamente la medición. El cegamiento de los evaluadores de resultados y el uso de instrumentos calibrados estandarizados pueden reducir el riesgo de que esto ocurra.
2. Sesgo de selección
El sesgo de selección se produce cuando hay una diferencia sistemática entre:
- Los que participan en el estudio y los que no lo hacen (afecta a la generalización) o
- Los del grupo de tratamiento de un estudio y los del grupo de control (afecta a la comparabilidad entre grupos).
Es decir, hay diferencias en las características entre los grupos de estudio, y esas características están relacionadas con la exposición o el resultado bajo investigación. El sesgo de selección puede ocurrir por varias razones.
El sesgo de muestreo describe el escenario en el que algunos individuos dentro de una población objetivo tienen más probabilidades de ser seleccionados para su inclusión que otros. Por ejemplo, si se les pide a los participantes que se ofrezcan como voluntarios para un estudio, es probable que los voluntarios no sean representativos de la población general, lo que amenaza la generalización de los resultados del estudio. Los voluntarios tienden a ser más conscientes de la salud que la población en general.
El sesgo de asignación se produce en ensayos controlados cuando hay una diferencia sistemática entre los participantes en los grupos de estudio (que no sean la intervención en estudio). Esto se puede evitar mediante aleatorización.
La pérdida de seguimiento es un problema particular asociado con los estudios de cohortes. Se puede introducir sesgo si los individuos perdidos en el seguimiento difieren con respecto a la exposición y el resultado de las personas que permanecen en el estudio. La pérdida diferencial de participantes de grupos de un ensayo de control aleatorio se conoce como sesgo de desgaste.
• Sesgo de selección en estudios de casos y controles
El sesgo de selección es un problema particular inherente a los estudios de casos y controles, donde da lugar a la no comparabilidad entre casos y controles. En los estudios de casos y controles, los controles deben proceder de la misma población que los casos, de modo que sean representativos de la población que produjo los casos. Los controles se utilizan para proporcionar una estimación de la tasa de exposición en la población. Por lo tanto, el sesgo de selección puede ocurrir cuando los individuos seleccionados como controles no son representativos de la población que produjo los casos.
El posible sesgo de selección en los estudios de casos y controles es un problema particular cuando los casos y controles se reclutan exclusivamente en hospitales o clínicas. Estos controles pueden ser preferibles por razones logísticas. Sin embargo, los pacientes hospitalarios tienden a tener características diferentes a la población en general, por ejemplo, pueden tener niveles más altos de consumo de alcohol o de fumar cigarrillos. Su ingreso en el hospital puede incluso estar relacionado con su estado de exposición, por lo que las mediciones de la exposición entre los controles pueden ser diferentes de las de la población de referencia. Esto puede dar lugar a una estimación sesgada de la asociación entre la exposición y la enfermedad.
Por ejemplo, en un estudio de casos y controles que explora los efectos del tabaquismo en el cáncer de pulmón, la fuerza de la asociación se subestimaría si los controles fueran pacientes con otras afecciones en la sala respiratoria, porque la admisión en el hospital por otras enfermedades pulmonares también puede estar relacionada con el estado de tabaquismo. Más sutilmente, el efecto del alcohol en la enfermedad hepática podría subestimarse si los controles se toman de otras salas: un consumo de alcohol más alto que el promedio puede resultar en la admisión por una variedad de otras afecciones, como el trauma.
Como es probable que el sesgo de selección sea un problema menor en los estudios de casos y controles basados en la población, los controles vecinales pueden ser una opción preferible cuando se usan casos de un hospital o clínica. Alternativamente, el potencial de sesgo de selección puede minimizarse seleccionando controles de más de una fuente. Por ejemplo, el uso de controles hospitalarios y vecinales.
• Sesgo de selección en estudios de cohortes
El sesgo de selección puede ser menos problemático en estudios de cohortes en comparación con estudios de casos y controles, porque los individuos expuestos y no expuestos se inscriben antes de que desarrollen el resultado de interés.
Sin embargo, puede introducirse un sesgo de selección cuando la exhaustividad del seguimiento o la determinación de casos difiera entre las categorías de exposición. Por ejemplo, puede ser más fácil hacer un seguimiento de las personas expuestas que trabajan en la misma fábrica que de los controles no expuestos seleccionados de la comunidad (pérdida de sesgo de seguimiento). Esto puede minimizarse garantizando que se mantenga un alto nivel de seguimiento entre todos los grupos de estudio.
El efecto trabajador sano es una forma potencial de sesgo de selección específico de los estudios de cohortes ocupacionales. Por ejemplo, un estudio de cohortes ocupacionales podría tratar de comparar las tasas de enfermedad entre individuos de un grupo ocupacional particular con individuos de una población estándar externa. Hay un riesgo de sesgo aquí porque las personas que están empleadas generalmente tienen que estar sanas para poder trabajar. Por el contrario, la población general también incluirá a las personas no aptas para trabajar. Por lo tanto, las tasas de mortalidad o morbilidad en la cohorte del grupo de ocupación pueden ser más bajas que en la población en su conjunto.
Con el fin de minimizar el potencial de esta forma de sesgo, debe seleccionarse un grupo de comparación entre un grupo de trabajadores con diferentes trabajos realizados en diferentes lugares dentro de una misma facilidad1; por ejemplo, un grupo de oficinistas no expuestos. Alternativamente, el grupo de comparación puede seleccionarse de una población externa de personas empleadas.
• Sesgo de selección en ensayos aleatorios
Los ensayos aleatorios son teóricamente menos propensos a verse afectados por el sesgo de selección, porque los individuos se asignan aleatoriamente a los grupos que se comparan, y se deben tomar medidas para minimizar la capacidad de los investigadores o participantes para influir en este proceso de asignación. Sin embargo, la negativa a participar en un estudio, o las retiradas posteriores, pueden afectar los resultados si las razones están relacionadas tanto con la exposición como con el resultado.
Confusión
Confusión, interacción y modificación de efectos
La confusión proporciona una explicación alternativa para una asociación entre una exposición (X) y un resultado. Ocurre cuando una asociación observada de hecho está distorsionada porque la exposición también está correlacionada con otro factor de riesgo (Y). Este factor de riesgo Y también está asociado con el resultado, pero independientemente de la exposición investigada, X. Como consecuencia, la asociación estimada no es la misma que el efecto real de la exposición X en el resultado.
Una distribución desigual del factor de riesgo adicional, Y, entre los grupos de estudio dará lugar a confusión. La asociación observada puede deberse total o parcialmente a los efectos de las diferencias entre los grupos de estudio y no a la exposición objeto de investigación.1
Un factor de confusión potencial es cualquier factor que pueda tener un efecto sobre el riesgo de enfermedad en estudio. Esto puede incluir factores con una relación causal directa con la enfermedad, así como factores que son medidas indirectas para otras causas desconocidas, como la edad y el nivel socioeconómico.2
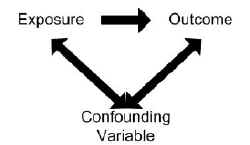
Para que una variable se considere un factor de confusión:
- La variable debe estar asociada de forma independiente con el resultado (es decir, ser un factor de riesgo).
- La variable también debe asociarse a la exposición en estudio en la población de origen.
- La variable no debe situarse en la vía causal entre la exposición y la enfermedad.
Ejemplos de confusión
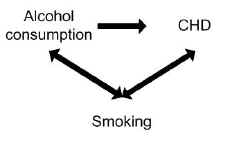
Un estudio encontró que el consumo de alcohol estaba asociado con el riesgo de enfermedad coronaria (EC). Sin embargo, fumar puede haber confundido la asociación entre el alcohol y la enfermedad coronaria.
Fumar es un factor de riesgo por derecho propio para la EC, por lo que se asocia de forma independiente con el resultado, y fumar también se asocia con el consumo de alcohol porque los fumadores tienden a beber más que los no fumadores.
Controlar el posible efecto de confusión del tabaquismo puede, de hecho, no mostrar asociación entre el consumo de alcohol y la EC.
Efectos de la confusión
Los factores de confusión, si no se controlan, causan sesgo en la estimación del impacto de la exposición en estudio. Los efectos de la confusión pueden resultar en:
- Una asociación observada cuando no existe una asociación real.
- No se observa asociación cuando existe una asociación verdadera.
- Una subestimación de la asociación (confusión negativa).
- Una sobreestimación de la asociación (confusión positiva).
Control para la confusión
La confusión puede abordarse en la etapa de diseño del estudio o ajustarse en la etapa de análisis, siempre que se hayan recogido suficientes datos relevantes. Se pueden aplicar varios métodos para controlar los factores de confusión potenciales y el objetivo de todos ellos es hacer que los grupos sean lo más similares posible con respecto al(los) factor (s) de confusión.
Control de la confusión en la etapa de diseño
Se pueden identificar factores de confusión potenciales en la etapa de diseño basados en estudios previos o porque un vínculo entre el factor y el resultado puede considerarse biológicamente plausible. Los métodos para limitar la confusión en la fase de diseño incluyen la aleatorización, la restricción y la coincidencia.
• Aleatorización
Este es el método ideal para controlar la confusión, ya que todas las variables de confusión potenciales, tanto conocidas como desconocidas, deben distribuirse por igual entre los grupos de estudio. Implica la asignación aleatoria (por ejemplo, utilizando una tabla de números aleatorios) de individuos a grupos de estudio. Sin embargo, este método solo puede utilizarse en ensayos clínicos experimentales.
* Restricción
La restricción limita la participación en el estudio a individuos que son similares en relación al confundidor. Por ejemplo, si la participación en un estudio se limita solo a no fumadores, se eliminará cualquier posible efecto de confusión del tabaquismo. Sin embargo, una desventaja de la restricción es que puede ser difícil generalizar los resultados del estudio a la población en general si el grupo de estudio es homogéneo.1
• Emparejamiento
El emparejamiento implica seleccionar controles para que la distribución de los posibles factores de confusión (por ejemplo, la edad o el estado de tabaquismo) sea lo más similar posible a la de los casos. En la práctica, esto solo se utiliza en estudios de casos y controles, pero se puede hacer de dos maneras:
- Emparejamiento: seleccionar para cada caso uno o más controles con características similares (p. ej. igualación de frecuencia – asegurando que, como grupo, los casos tengan características similares a los controles
Detectar y controlar la confusión en la etapa de análisis
La presencia o magnitud de la confusión en los estudios epidemiológicos se evalúa observando el grado de discrepancia entre la estimación bruta (sin controlar la confusión) y la estimación ajustada después de tener en cuenta los posibles factores de confusión. Si la estimación ha cambiado y hay poca variación entre las proporciones específicas del estrato (véase más adelante), entonces hay pruebas de confusión.
No es apropiado utilizar pruebas estadísticas para evaluar la presencia de confusión, pero se pueden utilizar los siguientes métodos para minimizar su efecto.
• Estratificación
La estratificación permite examinar la asociación entre la exposición y el resultado dentro de diferentes estratos de la variable de confusión, por ejemplo, por edad o sexo. La fuerza de la asociación se mide inicialmente por separado dentro de cada estrato de la variable de confusión. Suponiendo que las tasas específicas del estrato sean relativamente uniformes, pueden agruparse para dar una estimación resumida ajustada o controlada para el posible factor de confusión. Un ejemplo es el método Mantel-Haenszel. Un inconveniente de este método es que cuanto más se estratifica la muestra original, más pequeño será cada estrato, y el poder para detectar asociaciones se reduce.
• Análisis multivariable
Modelado estadístico (p.ej. análisis de regresión multivariable) se utiliza para controlar más de un confundidor al mismo tiempo, y permite la interpretación del efecto de cada confundidor individualmente. Es el método más utilizado para tratar la confusión en la etapa de análisis.
• Estandarización
La estandarización tiene en cuenta los factores de confusión (generalmente la edad y el sexo) mediante el uso de una población de referencia estándar para negar el efecto de las diferencias en la distribución de los factores de confusión entre las poblaciones de estudio. Ver «Numeradores, denominadores y poblaciones en riesgo» para más detalles.
Confusión residual
Solo es posible controlar los factores de confusión en la etapa de análisis si los datos de los factores de confusión se recogieron con precisión. La confusión residual se produce cuando todos los factores de confusión no se han ajustado adecuadamente, ya sea porque se han medido incorrectamente o porque no se han medido (por ejemplo, factores de confusión desconocidos). Un ejemplo sería el nivel socioeconómico, porque influye en múltiples resultados de salud, pero es difícil de medir con precisión.3
Interacción (modificación del efecto)
La interacción ocurre cuando la dirección o magnitud de una asociación entre dos variables varía de acuerdo con el nivel de una tercera variable (el modificador del efecto). Por ejemplo, la aspirina se puede usar para controlar los síntomas de enfermedades virales, como la gripe. Sin embargo, aunque puede ser eficaz en adultos, el uso de aspirina en niños con enfermedades virales se asocia con disfunción hepática y daño cerebral (síndrome de Reye).4 En este caso, el efecto de la aspirina en el manejo de enfermedades virales se modifica por la edad.
Cuando existe interacción, calcular una estimación general de una asociación puede ser engañoso. A diferencia de la confusión, la interacción es un fenómeno biológico y no debe ajustarse estadísticamente. Un método común para tratar la interacción es analizar y presentar las asociaciones para cada nivel de la tercera variable. En el ejemplo anterior, las probabilidades de desarrollar el síndrome de Reye después del uso de aspirina en enfermedades virales serían mucho mayores en niños en comparación con adultos, y esto destacaría el papel de la edad como modificador del efecto. La interacción se puede confirmar estadísticamente, por ejemplo, utilizando una prueba de chi cuadrado para evaluar la heterogeneidad en las estimaciones específicas del estrato. Sin embargo, se sabe que estas pruebas tienen un bajo poder de detección de interacción5 y también se recomienda una inspección visual de estimaciones específicas de estratos.
- Hennekens CH, Buring JE. Epidemiología en Medicina, Lippincott Williams & Wilkins, 1987.
- Carneiro I, Howard N. Introducción a la Epidemiología. Open University Press, 2011.
- http://www.edmundjessop.org.uk/fulltext.doc – Accedido el 20/02/16
- McGovern MC. Síndrome de Reye y aspirina: para que no nos olvidemos. BMJ 2001; 322: 1591.
- Marshall SW. Potencia para pruebas de interacción: efecto de aumentar la tasa de error de tipo 1. Perspectivas e innovaciones epidemiológicas, 2007;4:4.
Leave a Reply