Connaissances sur la santé
VEUILLEZ NOTER:
Nous sommes actuellement en train de mettre à jour ce chapitre et nous apprécions votre patience pendant que cela est en cours.
Biais dans les études épidémiologiques
Bien que les résultats d’une étude épidémiologique puissent refléter l’effet réel d’une ou de plusieurs expositions sur l’évolution du résultat à l’étude, il faut toujours considérer que les résultats peuvent en fait être dus à une autre explication1.
De telles explications alternatives peuvent être dues aux effets du hasard (erreur aléatoire), du biais ou de la confusion qui peuvent produire des résultats fallacieux, nous amenant à conclure à l’existence d’une association statistique valide lorsqu’elle n’existe pas ou à l’absence d’association lorsqu’elle est réellement présente1.
Les études observationnelles sont particulièrement sensibles aux effets du hasard, du biais et de la confusion et ces facteurs doivent être pris en compte à la fois au stade de la conception et de l’analyse d’une étude épidémiologique afin de minimiser leurs effets.
Biais
Le biais peut être défini comme toute erreur systématique dans une étude épidémiologique qui aboutit à une estimation incorrecte de l’effet réel d’une exposition sur le résultat d’intérêt.1
- Le biais résulte d’erreurs systématiques dans la méthodologie de recherche.
- L’effet du biais sera une estimation supérieure ou inférieure à la valeur réelle, selon la direction de l’erreur systématique.
- L’ampleur du biais est généralement difficile à quantifier, et il existe une marge limitée pour l’ajustement de la plupart des formes de biais au stade de l’analyse. Par conséquent, il est essentiel d’examiner attentivement et de contrôler les façons dont les biais peuvent être introduits lors de la conception et de la conduite de l’étude afin de limiter les effets sur la validité des résultats de l’étude.
Types courants de biais dans les études épidémiologiques
Plus de 50 types de biais ont été identifiés dans les études épidémiologiques, mais pour simplifier, ils peuvent être regroupés en deux catégories: le biais d’information et le biais de sélection.
1. Biais d’information
Le biais d’information résulte de différences systématiques dans la façon dont les données sur l’exposition ou les résultats sont obtenues des différents groupes d’étude.1 Cela peut signifier que les individus sont affectés à la mauvaise catégorie de résultats, ce qui conduit à une estimation incorrecte de l’association entre l’exposition et le résultat.
Les erreurs de mesure sont également appelées erreurs de classification, et l’ampleur de l’effet du biais dépend du type d’erreur de classification qui s’est produite. Il existe deux types de classification erronée – différentielle et non différentielle – et ceux–ci sont traités ailleurs (voir « Sources de variation, sa mesure et son contrôle”).
Le biais de l’observateur peut être le résultat de la connaissance préalable du chercheur de l’hypothèse à l’étude ou de la connaissance de l’exposition ou de l’état de la maladie d’un individu. Ces informations peuvent influencer la façon dont les informations sont collectées, mesurées ou interprétées par l’investigateur pour chacun des groupes d’étude.
Par exemple, dans un essai d’un nouveau médicament pour traiter l’hypertension, si l’investigateur sait à quel bras de traitement les participants ont été affectés, cela peut influencer leur lecture des mesures de la pression artérielle. Les observateurs peuvent sous-estimer la pression artérielle chez ceux qui ont été traités et la surestimer chez ceux du groupe témoin.
Il y a biais de l’intervieweur lorsqu’un intervieweur pose des questions qui peuvent influencer systématiquement les réponses données par les personnes interrogées.
Minimiser le biais de l’observateur/intervieweur:
- Dans la mesure du possible, les observateurs doivent être aveugles à l’exposition et à l’état pathologique de l’individu
- Les observateurs aveugles à l’hypothèse étudiée.
- Dans un essai contrôlé randomisé, les chercheurs et les participants au traitement et au groupe témoin sont aveugles (double aveuglement).
- Développement d’un protocole de collecte, de mesure et d’interprétation de l’information.
- Utilisation de questionnaires standardisés ou d’instruments calibrés, tels que des sphygmomanomètres.
- Formation des intervieweurs.
Biais de rappel (ou de réponse) – Dans une étude cas-témoins, les données sur l’exposition sont collectées rétrospectivement. La qualité des données est donc déterminée dans une large mesure sur la capacité du patient à se souvenir avec précision des expositions passées. Un biais de rappel peut se produire lorsque les informations fournies sur l’exposition diffèrent entre les cas et les témoins. Par exemple, une personne dont le résultat fait l’objet d’une enquête (cas) peut déclarer son expérience d’exposition différemment d’une personne sans le résultat (contrôle) faisant l’objet d’une enquête.
Le biais de rappel peut entraîner une sous-estimation ou une surestimation de l’association entre l’exposition et le résultat.
Les méthodes pour minimiser le biais de rappel comprennent :
- La collecte de données d’exposition à partir de dossiers professionnels ou médicaux.
- Aveuglant les participants à l’hypothèse de l’étude.
Le biais de désirabilité sociale se produit lorsque les répondants aux enquêtes ont tendance à répondre d’une manière qu’ils estiment favorable aux autres, par exemple en sur-déclarant des comportements positifs ou en sous-déclarant des comportements indésirables. En signalant les biais, les individus peuvent supprimer ou révéler des informations de manière sélective, pour des raisons similaires (par exemple, concernant les antécédents de tabagisme). Le biais de déclaration peut également se référer à la déclaration sélective des résultats par les auteurs de l’étude.
Le biais de performance fait référence au fait que le personnel de l’étude ou les participants modifient leur comportement /leurs réponses lorsqu’ils sont conscients des allocations de groupe.
Le biais de détection se produit lorsque la façon dont les informations sur les résultats sont collectées diffère d’un groupe à l’autre. Le biais de l’instrument désigne le cas où un instrument de mesure mal calibré surestime / sous-estime systématiquement la mesure. L’aveuglement des évaluateurs des résultats et l’utilisation d’instruments standardisés et calibrés peuvent réduire le risque de cela.
2. Biais de sélection
Le biais de sélection se produit lorsqu’il existe une différence systématique entre:
- Ceux qui participent à l’étude et ceux qui ne le font pas (affectant la généralisabilité) ou
- Ceux du groupe de traitement d’une étude et ceux du groupe témoin (affectant la comparabilité entre les groupes).
C’est-à-dire qu’il existe des différences dans les caractéristiques entre les groupes d’étude, et ces caractéristiques sont liées à l’exposition ou au résultat étudié. Un biais de sélection peut se produire pour un certain nombre de raisons.
Le biais d’échantillonnage décrit le scénario dans lequel certains individus d’une population cible sont plus susceptibles d’être sélectionnés pour l’inclusion que d’autres. Par exemple, si l’on demande aux participants de se porter volontaires pour une étude, il est probable que ceux qui se portent volontaires ne seront pas représentatifs de la population générale, ce qui menace la généralisation des résultats de l’étude. Les bénévoles ont tendance à être plus soucieux de leur santé que la population en général.
Un biais d’allocation se produit dans les essais contrôlés lorsqu’il existe une différence systématique entre les participants aux groupes d’étude (autre que l’intervention étudiée). Cela peut être évité par la randomisation.
La perte de suivi est un problème particulier associé aux études de cohorte. Un biais peut être introduit si les personnes perdues pour le suivi diffèrent en ce qui concerne l’exposition et les résultats des personnes qui restent dans l’étude. La perte différentielle des participants des groupes d’un essai contrôle randomisé est connue sous le nom de biais d’attrition.
•Le biais de sélection dans les études cas-témoins
Le biais de sélection est un problème particulier inhérent aux études cas-témoins, où il entraîne une non-comparabilité entre les cas et les témoins. Dans les études cas-témoins, les témoins doivent provenir de la même population que les cas, de sorte qu’ils sont représentatifs de la population qui a produit les cas. Les contrôles sont utilisés pour fournir une estimation du taux d’exposition dans la population. Par conséquent, un biais de sélection peut se produire lorsque les personnes sélectionnées comme témoins ne sont pas représentatives de la population qui a produit les cas.
Le risque de biais de sélection dans les études cas-témoins est un problème particulier lorsque les cas et les témoins sont recrutés exclusivement à l’hôpital ou dans les cliniques. De tels contrôles peuvent être préférables pour des raisons logistiques. Cependant, les patients hospitalisés ont tendance à avoir des caractéristiques différentes de la population en général, par exemple, ils peuvent avoir des niveaux plus élevés de consommation d’alcool ou de tabagisme. Leur admission à l’hôpital peut même être liée à leur statut d’exposition, de sorte que les mesures de l’exposition chez les témoins peuvent être différentes de celles de la population de référence. Cela peut entraîner une estimation biaisée de l’association entre l’exposition et la maladie.
Par exemple, dans une étude cas-témoins explorant les effets du tabagisme sur le cancer du poumon, la force de l’association serait sous-estimée si les témoins étaient des patients atteints d’autres affections dans le service respiratoire, car l’admission à l’hôpital pour d’autres maladies pulmonaires peut également être liée au statut de fumeur. Plus subtilement, l’effet de l’alcool sur les maladies du foie pourrait potentiellement être sous-estimé si les contrôles sont effectués dans d’autres services: une consommation d’alcool supérieure à la moyenne peut entraîner une admission pour diverses autres conditions, telles que les traumatismes.
Comme le potentiel de biais de sélection est probablement moins problématique dans les études cas-témoins basées sur la population, les contrôles de voisinage peuvent être un choix préférable lorsque l’on utilise des cas en milieu hospitalier ou clinique. Alternativement, le potentiel de biais de sélection peut être réduit au minimum en sélectionnant des contrôles provenant de plusieurs sources. Par exemple, l’utilisation de contrôles à la fois dans les hôpitaux et dans les quartiers.
•Biais de sélection dans les études de cohorte
Le biais de sélection peut poser moins de problèmes dans les études de cohorte que dans les études cas-témoins, car les individus exposés et non exposés sont enrôlés avant de développer le résultat d’intérêt.
Cependant, un biais de sélection peut être introduit lorsque l’exhaustivité du suivi ou de la détermination des cas diffère d’une catégorie d’exposition à l’autre. Par exemple, il peut être plus facile de suivre des personnes exposées qui travaillent toutes dans la même usine que des témoins non exposés sélectionnés dans la communauté (biais de perte de suivi). Cela peut être minimisé en veillant à ce qu’un niveau élevé de suivi soit maintenu parmi tous les groupes d’étude.
L’effet travailleur en santé est une forme potentielle de biais de sélection spécifique aux études de cohorte professionnelle. Par exemple, une étude de cohorte professionnelle pourrait chercher à comparer les taux de maladie parmi les individus d’un groupe professionnel particulier avec les individus d’une population standard externe. Il y a un risque de partialité ici parce que les personnes qui sont employées doivent généralement être en bonne santé pour pouvoir travailler. En revanche, la population générale comprendra également ceux qui sont inaptes au travail. Par conséquent, les taux de mortalité ou de morbidité dans la cohorte du groupe professionnel peuvent être plus faibles que dans l’ensemble de la population.
Afin de minimiser le risque de cette forme de biais, un groupe de comparaison devrait être sélectionné parmi un groupe de travailleurs dont les différents emplois sont exercés à différents endroits au sein d’une même facilité1; par exemple, un groupe de travailleurs de bureau non exposés. En variante, le groupe témoin peut être choisi parmi une population externe de personnes occupées.
•Biais de sélection dans les essais randomisés
Les essais randomisés sont théoriquement moins susceptibles d’être affectés par le biais de sélection, car les individus sont répartis aléatoirement dans les groupes comparés, et des mesures doivent être prises pour minimiser la capacité des chercheurs ou des participants à influencer ce processus d’allocation. Cependant, les refus de participer à une étude ou les retraits ultérieurs peuvent affecter les résultats si les raisons sont liées à la fois à l’exposition et aux résultats.
Confusion
Confusion, interaction et modification des effets
La confusion fournit une explication alternative pour une association entre une exposition (X) et un résultat. Il se produit lorsqu’une association observée est en fait déformée car l’exposition est également corrélée avec un autre facteur de risque (Y). Ce facteur de risque Y est également associé au résultat, mais indépendamment de l’exposition à l’étude, X. Par conséquent, l’association estimée n’est pas la même que l’effet réel de l’exposition X sur le résultat.
Une répartition inégale du facteur de risque supplémentaire, Y, entre les groupes d’étude entraînera une confusion. L’association observée peut être due en tout ou en partie aux effets des différences entre les groupes d’étude plutôt qu’à l’exposition à l’étude.1
Un facteur de confusion potentiel est tout facteur qui pourrait avoir un effet sur le risque de maladie à l’étude. Cela peut inclure des facteurs ayant un lien de causalité direct avec la maladie, ainsi que des facteurs qui sont des mesures indirectes pour d’autres causes inconnues, telles que l’âge et le statut socio-économique.2
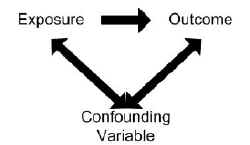
Pour qu’une variable soit considérée comme confondante :
- La variable doit être associée indépendamment au résultat (c’est-à-dire être un facteur de risque).
- La variable doit également être associée à l’exposition à l’étude dans la population source.
- La variable ne doit pas se situer sur la voie de causalité entre l’exposition et la maladie.
Exemples de confusion
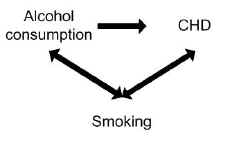
Une étude a révélé que la consommation d’alcool était associée au risque de maladie coronarienne (coronaropathie). Cependant, le tabagisme peut avoir confondu l’association entre l’alcool et les maladies coronariennes.
Le tabagisme est un facteur de risque à part entière pour les maladies coronariennes, il est donc associé indépendamment au résultat, et le tabagisme est également associé à la consommation d’alcool parce que les fumeurs ont tendance à boire plus que les non-fumeurs.
Le contrôle de l’effet de confusion potentiel du tabagisme peut en fait ne montrer aucune association entre la consommation d’alcool et les maladies coronariennes.
Les effets de la confusion
Les facteurs de confusion, s’ils ne sont pas contrôlés, provoquent un biais dans l’estimation de l’impact de l’exposition étudiée. Les effets de la confusion peuvent entraîner :
- Une association observée lorsqu’aucune association réelle n’existe.
- Aucune association observée lorsqu’une véritable association existe.
- Une sous-estimation de l’association (confusion négative).
- Une surestimation de l’association (confusion positive).
Le contrôle de la confusion
La confusion peut être abordée soit au stade de la conception de l’étude, soit ajustée au stade de l’analyse, à condition que des données pertinentes suffisantes aient été collectées. Un certain nombre de méthodes peuvent être appliquées pour contrôler les facteurs de confusion potentiels et le but de toutes ces méthodes est de rendre les groupes aussi similaires que possible par rapport au ou aux facteurs de confusion.
Contrôle de la confusion au stade de la conception
Des facteurs de confusion potentiels peuvent être identifiés au stade de la conception sur la base d’études antérieures ou parce qu’un lien entre le facteur et le résultat peut être considéré comme biologiquement plausible. Les méthodes pour limiter la confusion au stade de la conception comprennent la randomisation, la restriction et l’appariement.
•Randomisation
C’est la méthode idéale pour contrôler la confusion, car toutes les variables de confusion potentielles, connues et inconnues, doivent être réparties également entre les groupes d’étude. Cela implique l’allocation aléatoire (par exemple, en utilisant une table de nombres aléatoires) d’individus aux groupes d’étude. Cependant, cette méthode ne peut être utilisée que dans des essais cliniques expérimentaux.
•Restriction
La restriction limite la participation à l’étude aux individus qui sont similaires par rapport au facteur de confusion. Par exemple, si la participation à une étude est limitée aux non-fumeurs seulement, tout effet de confusion potentiel du tabagisme sera éliminé. Cependant, un inconvénient de la restriction est qu’il peut être difficile de généraliser les résultats de l’étude à l’ensemble de la population si le groupe d’étude est homogène.1
•Appariement
L’appariement consiste à sélectionner des témoins de manière à ce que la répartition des facteurs de confusion potentiels (par exemple, l’âge ou le statut de fumeur) soit aussi similaire que possible à celle des cas. En pratique, cela n’est utilisé que dans les études cas-témoins, mais cela peut être fait de deux manières:
- Appariement de paires – sélection pour chaque cas d’un ou plusieurs contrôles ayant des caractéristiques similaires (par ex. même âge et habitudes de tabagisme)
- Correspondance de fréquence – s’assurer qu’en tant que groupe, les cas présentent des caractéristiques similaires aux témoins
Détection et contrôle de la confusion au stade de l’analyse
La présence ou l’ampleur de la confusion dans les études épidémiologiques est évaluée en observant le degré de divergence entre l’estimation brute (sans contrôle de la confusion) et l’estimation ajustée après prise en compte du ou des facteurs de confusion potentiels. Si l’estimation a changé et qu’il y a peu de variation entre les ratios spécifiques à la strate (voir ci-dessous), il existe des preuves de confusion.
Il n’est pas approprié d’utiliser des tests statistiques pour évaluer la présence de confusion, mais les méthodes suivantes peuvent être utilisées pour minimiser son effet.
•Stratification
La stratification permet d’examiner l’association entre l’exposition et le résultat dans différentes strates de la variable de confusion, par exemple selon l’âge ou le sexe. La force de l’association est initialement mesurée séparément dans chaque strate de la variable confondante. En supposant que les taux propres à la strate sont relativement uniformes, ils peuvent ensuite être regroupés pour donner une estimation sommaire ajustée ou contrôlée pour le facteur de confusion potentiel. Un exemple est la méthode Mantel-Haenszel. Un inconvénient de cette méthode est que plus l’échantillon d’origine est stratifié, plus chaque strate deviendra petite et le pouvoir de détecter les associations est réduit.
•Analyse multivariable
Modélisation statistique (p. ex. analyse de régression multivariable) est utilisée pour contrôler plusieurs facteurs de confusion en même temps et permet d’interpréter l’effet de chaque facteur de confusion individuellement. C’est la méthode la plus couramment utilisée pour traiter la confusion au stade de l’analyse.
• Normalisation
La normalisation tient compte des facteurs de confusion (généralement l’âge et le sexe) en utilisant une population de référence standard pour annuler l’effet des différences dans la distribution des facteurs de confusion entre les populations étudiées. Voir » Numérateurs, dénominateurs et populations à risque ” pour plus de détails.
Confusion résiduelle
Il n’est possible de contrôler les facteurs de confusion au stade de l’analyse que si les données sur les facteurs de confusion ont été recueillies avec précision. La confusion résiduelle se produit lorsque tous les facteurs de confusion n’ont pas été correctement ajustés, soit parce qu’ils ont été mesurés de manière inexacte, soit parce qu’ils n’ont pas été mesurés (par exemple, des facteurs de confusion inconnus). Un exemple serait le statut socio-économique, car il influe sur plusieurs résultats pour la santé, mais il est difficile à mesurer avec précision.3
Interaction (modification de l’effet)
L’interaction se produit lorsque la direction ou l’amplitude d’une association entre deux variables varie en fonction du niveau d’une troisième variable (le modificateur d’effet). Par exemple, l’aspirine peut être utilisée pour gérer les symptômes de maladies virales, telles que la grippe. Cependant, bien qu’elle puisse être efficace chez les adultes, l’utilisation d’aspirine chez les enfants atteints de maladies virales est associée à un dysfonctionnement hépatique et à des lésions cérébrales (syndrome de Reye).4 Dans ce cas, l’effet de l’aspirine sur la gestion des maladies virales est modifié par l’âge.
Lorsqu’il existe une interaction, le calcul d’une estimation globale d’une association peut être trompeur. Contrairement à la confusion, l’interaction est un phénomène biologique et ne doit pas être corrigée statistiquement. Une méthode courante pour traiter l’interaction consiste à analyser et à présenter les associations pour chaque niveau de la troisième variable. Dans l’exemple ci-dessus, les chances de développer le syndrome de Reye après l’utilisation d’aspirine dans les maladies virales seraient beaucoup plus grandes chez les enfants que chez les adultes, ce qui mettrait en évidence le rôle de l’âge en tant que modificateur d’effet. L’interaction peut être confirmée statistiquement, par exemple en utilisant un test du chi carré pour évaluer l’hétérogénéité dans les estimations spécifiques à la strate. Cependant, de tels tests sont connus pour avoir une faible puissance de détection de l’interaction5 et une inspection visuelle des estimations spécifiques à la strate est également recommandée.
- Hennekens CH, Buring JE. Épidémiologie en médecine, Lippincott Williams &Wilkins, 1987.
- Carneiro I, Howard N. Introduction à l’épidémiologie. Open University Press, 2011.
- http://www.edmundjessop.org.uk/fulltext.doc – Consulté le 20/02/16
- McGovern MC. Syndrome de Reye et aspirine: de peur que nous oubliions. BMJ 2001; 322:1591.
- Marshall SW. Puissance pour les tests d’interaction: effet de l’augmentation du taux d’erreur de type 1. Perspectives épidémiologiques et innovations 2007; 4:4.
Leave a Reply