Abstracte datastructuren

In computer science, een abstract data type (ADT) is een wiskundig model voor data types waar een data type wordt gedefinieerd door zijn gedrag (semantiek) vanuit het oogpunt van een gebruiker van de gegevens, in het bijzonder in termen van mogelijke waarden, mogelijk bewerkingen op gegevens van dit type, en het gedrag van deze operaties. Dit contrasteert met datastructuren, die concrete representaties van gegevens zijn en het standpunt zijn van een uitvoerder, niet van een gebruiker.
formeel kan een ADT worden gedefinieerd als een” klasse van objecten waarvan het logische gedrag wordt gedefinieerd door een verzameling van waarden en een verzameling van operaties”; dit is analoog aan een algebraïsche structuur in de wiskunde. Wat wordt bedoeld met “gedrag” verschilt per auteur, met de twee belangrijkste types van formele specificaties voor gedrag zijn axiomatische (algebraïsche) specificatie en een abstract model; deze komen respectievelijk overeen met axiomatische semantiek en operationele semantiek van een abstracte machine. Sommige auteurs omvatten ook de computationele complexiteit (“kosten”), zowel in termen van tijd (voor computing operaties) en ruimte (voor het vertegenwoordigen van waarden).
de reden dat we abstracte structuren gebruiken is omdat ze efficiënt geheugen gebruiken gebaseerd op het ontwerp van de gegevens die erin zijn opgeslagen. Met zeer grote hoeveelheden data of zeer vaak veranderende data, kan de datastructuur een enorm verschil maken in de efficiëntie (runtime) van uw computerprogramma.
in meer algemene taal is een abstracte datastructuur slechts een rangschikking van gegevens die we hebben ingebouwd in een ordelijke rangschikking.
Een perfect mooi overzicht
Sommige vormen van abstracte datastructuren
Beoordeeld door de IB
- statische en dynamische gegevensstructuur
- arrays
- twee-dimensionale arrays
- stack
- queue
- gelinkte lijst
- bomen
- binaire boom
- collecties
- recursie
NIET Beoordeeld door de IB, maar je moet ze leren kennen
- geeft
- woordenboeken
- zet
- aantal
basisbediening van de structuur van de gegevens
ik vond dit een uitstekende dia van Simon Allardice.

de Vergelijking van verschillende data structuren
| Data Structuur | Sterke punten | Zwakheden |
| arrays | Invoegen en verwijderen van elementen, itereren door de collectie | Sorteren en zoeken, Invoegen en verwijderen – vooral als u invoegen en verwijderen aan het begin of het einde van de array |
| gelinkte lijst | direct indexeren, Makkelijk te maken en gebruik | directe toegang, zoeken en sorteren |
| stack en queue | ontworpen voor LIFO / FIFO | directe toegang, zoeken en sorteren |
| binaire boom | snelheid van invoegen en verwijderen, snelheid van toegang, het handhaven van gesorteerde volgorde | sommige overhead |
vergelijking van statische Versus dynamische datastructuren
deze vergelijking wordt gebruikt uit ons Computer Science leerboek.
| statische datastructuur | dynamische datastructuur | inefficiënt omdat geheugen wordt toegewezen dat mogelijk niet nodig is. | efficiënt omdat de hoeveelheid geheugen varieert als dat nodig is. |
| snelle toegang tot elk element van gegevens als de geheugenlocatie wordt vastgesteld wanneer het programma wordt geschreven. | tragere toegang tot elk element als de geheugenlocatie wordt toegewezen tijdens runtime. |
| toegewezen geheugenadressen zullen dus sneller toegankelijk zijn. | toegewezen geheugenadressen kunnen gefragmenteerd zijn en zo trager toegankelijk zijn. |
| structuren hebben een vaste grootte, waardoor ze beter voorspelbaar zijn om mee te werken. Ze kunnen bijvoorbeeld een header bevatten. | structuren variëren in grootte, dus er moet een mechanisme zijn om de grootte van de huidige structuur te kennen. |
| de relatie tussen verschillende gegevenselementen verandert niet. | de relatie tussen verschillende elementen van data zal veranderen als het programma wordt uitgevoerd. |
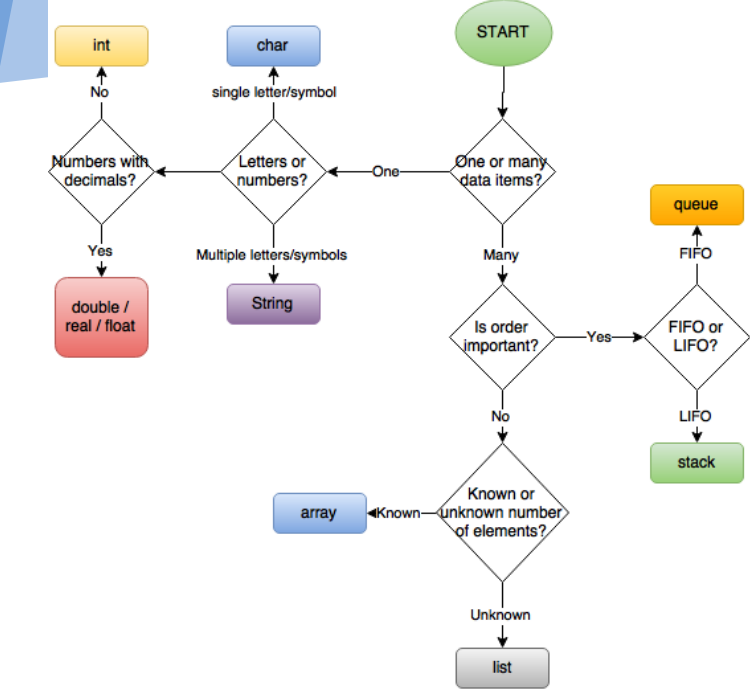
kiezen welke datastructuur te gebruiken
Deze grafiek wordt gebruikt met grote dankbaarheid van Dartford Grammar School Computer Science Department.
standaarden
- identificeren een situatie die het gebruik van recursief denken vereist.
- Identificeer recursief denken in een opgegeven probleemoplossing.
- traceer een recursief algoritme om een oplossing voor een probleem uit te drukken.
- Beschrijf de kenmerken van een tweedimensionale array.
- construeer algoritmen met behulp van tweedimensionale arrays.
- Beschrijf de kenmerken en toepassingen van een stack.
- construeer algoritmen met behulp van de toegangsmethoden van een stack.
- Beschrijf de kenmerken en toepassingen van een wachtrij.
- construeer algoritmen met behulp van de toegangsmethoden van een wachtrij.
- verklaar het gebruik van arrays als statische stapels en wachtrijen.
- Beschrijf de kenmerken en kenmerken van een dynamische gegevensstructuur.
- beschrijf hoe gekoppelde lijsten logisch werken.
- schets gekoppelde lijsten (enkel, dubbel en rond).
- Beschrijf de kenmerken en toepassingen van een verzameling.
- construeer algoritmen met behulp van de toegangsmethoden van een verzameling.
- bespreek de behoefte aan subprogramma ‘ s en collecties binnen geprogrammeerde oplossingen.
- construeer algoritmen met behulp van vooraf gedefinieerde subprogramma ‘ s, eendimensionale arrays en/of collecties.
- beschrijf hoe bomen logisch werken (zowel binair als niet-binair).
- Definieer de termen: ouder, links-kind, rechts-kind, subtree, wortel en blad.
- geef het resultaat van Inorder, postorder en preorder tree traversal.
- schets binaire bomen.
- Definieer de term dynamische gegevensstructuur.
- vergelijk het gebruik van statische en dynamische gegevensstructuren.
- suggereren een geschikte structuur voor een bepaalde situatie.
Leave a Reply