de OCR com o Python, OpenCV e PyTesseract

de Reconhecimento Óptico de Caracteres (OCR) é a conversão de imagens de datilografado, manuscrito ou texto impresso em máquina de texto codificado, seja a partir de um documento digitalizado, uma foto de um documento, uma fotografia de uma cena (outdoors em uma foto de paisagem) ou a partir de um texto sobreposta a uma imagem (legendas em uma transmissão de televisão).
OCR consiste geralmente em sub-processos para executar com a maior precisão possível.

- Pré-processamento
- Texto de detecção
- reconhecimento de Texto
- Pós-processamento
O sub-processos do curso pode variar dependendo do caso de uso, mas estes são geralmente os passos necessários para realizar reconhecimento óptico de caracteres.
Tesseract OCR :
Tesseract é um motor de reconhecimento de texto de código aberto (OCR), disponível sob a Licença Apache 2.0. Ele pode ser usado diretamente, ou (para programadores) usando uma API para extrair texto impresso de imagens. Ele suporta uma grande variedade de línguas. Tesseract não tem um GUI embutido, mas há vários disponíveis a partir da página 3rdParty. O Tesseract é compatível com muitas linguagens de programação e frameworks através de invólucros que podem ser encontrados aqui. Ele pode ser usado com a análise de layout existente para reconhecer texto dentro de um documento grande, ou pode ser usado em conjunto com um detector de texto externo para reconhecer texto a partir de uma imagem de uma única linha de texto.
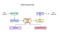
Tesseract 4.00 inclui uma nova rede neural subsistema configurado como uma linha de texto reconhecedor. Tem suas origens na implementação LSTM baseada em Python do OCRopus, mas foi redesenhada para o Tesseract em C++. O sistema de rede neural em Tesseract pré-data TensorFlow, mas é compatível com ele, como há uma linguagem de descrição de rede chamada Variable Graph Specification Language (VGSL), que também está disponível para TensorFlow.
para reconhecer uma imagem contendo um único caractere, normalmente usamos uma rede neural convolucional (CNN). Text of arbitrary length is a sequence of characters, and such problems are solved using RNNs and LSTM is a popular form of RNN. Leia este post para saber mais sobre o LSTM.
Tesseract desenvolvido a partir do modelo OCRopus em Python, que era um fork de um LSMT em C++, chamado CLSTM. CLSTM é uma implementação do modelo de rede neural recorrente do LSTM em C++.
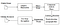
Tesseract foi um esforço na limpeza de código e adicionar um novo LSTM modelo. A imagem de entrada é processada em caixas (retângulo) linha por linha alimentando o modelo LSTM e dando saída. Na imagem abaixo podemos visualizar como funciona.

Instalação do Tesseract
Instalação do tesseract no Windows é fácil com os binários pré-compilados encontrado aqui. Não se esqueça de editar a variável de ambiente “path” e adicionar a localização do tesseract. Para a instalação Linux ou Mac é instalado com poucos comandos.
Por padrão, o Tesseract espera uma página de texto quando segmenta uma imagem. Se você está apenas procurando OCR uma pequena região, tente um modo de segmentação diferente, usando o argumento-psm. Existem 14 modos disponíveis que podem ser encontrados aqui. Por padrão, o Tesseract automatiza totalmente a segmentação da página, mas não executa a orientação e detecção de script. Para especificar o parâmetro, digite o seguinte:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
há também mais um argumento importante, o modo motor OCR (oem). Tesseract 4 tem dois motores OCR-Legacy Tesseract engine e LSTM engine. Existem quatro modos de operação escolhidos usando a opção-oem.
0. Apenas Motor legado.
1. Redes neurais apenas Motor LSTM.
2. Legacy + LSTM engines.
3. Padrão, baseado no que está disponível.
OCR com o Pytesseract e o OpenCV:
o Pytesseract é um invólucro para o motor Tesseract-OCR. Ele também é útil como um script de Invocação independente para tesseract, como ele pode ler todos os tipos de imagem suportados pela almofada e leptonica imaging libraries, incluindo jpeg, png, gif, bmp, tiff, e outros. Leia aqui mais informações sobre a abordagem Python.
pré-Processamento para Tesseract :
precisamos ter certeza de que a imagem é devidamente pré-processados. para garantir um certo nível de precisão.
isto inclui redimensionamento, binarização, remoção de ruído, deskewing, etc.
para pré-processar a imagem para OCR, use qualquer uma das seguintes funções python ou siga a documentação do OpenCV.
Our input is this image :

Here’s what we get :

Getting boxes around text :
podemos determinar a informação da caixa envolvente com o PyTesseradt usando o seguinte código.
o programa abaixo dar-lhe-á informação da caixa envolvente para cada carácter detectado pelo tesseract durante o OCR.
Se você deseja caixas em torno de palavras, em vez de caracteres, a função image_to_data vai vir a calhar. Você pode usar a função image_to_data com o tipo de saída especificado com pytesseract .
usaremos a imagem de recepção da amostra abaixo como entrada para testar o tesseract .

Aqui está o código :
A saída é um dicionário com as seguintes chaves :

Usando este dicionário, podemos obter cada palavra detectada, sua caixa delimitadora de informações, o texto e a confiança pontuações para cada um.
Você pode plotar as caixas usando o código abaixo :
A saída:

Como podemos ver Tesseract não é capaz de detectar todas as caixas de texto com confiança, má qualidade de verificações e fontes pequenas podem produzir uma baixa qualidade de OCR de texto de detecção. Também Nenhum pré-processamento foi feito para melhorar a qualidade da imagem.
correspondência do modelo de texto (detectar apenas os algarismos ):
tome o exemplo de tentar descobrir onde uma cadeia de dígitos só está numa imagem. Aqui o nosso modelo será um padrão de expressão regular que combinaremos com os nossos resultados OCR para encontrar as caixas envolventes adequadas. Usaremos o módulo regex e a função image_to_data para isso.

Página segmentação modos de :
Existem várias formas de analisar uma página de texto. A api tesseract oferece vários modos de segmentação de páginas se você quiser executar OCR em apenas uma pequena região ou em diferentes orientações, etc.
Aqui está uma lista dos modos de segmentação da página suportados pelo tesseract :
0. Apenas orientação e detecção de script (OSD).
1. Segmentação automática da página com OSD.
2. Segmentação automática da página, mas sem OSD, ou OCR.
3. Segmentação automática da página, mas sem OSD. (Default)
4. Assuma uma única coluna de texto de tamanhos variáveis.
5. Assuma um único bloco uniforme de texto alinhado verticalmente.
6. Assuma um único bloco uniforme de texto.
7. Trate a imagem como uma única linha de texto.
8. Trate a imagem como uma única palavra.
9. Trate a imagem como uma única palavra em um círculo.
10. Trate a imagem como um único personagem.
11. Mensagem esparsa. Encontre o máximo de texto possível em nenhuma ordem particular.
12. Texto esparso com OSD.
13. Linha bruta. Tratar a imagem como uma única linha de texto, contornando hacks que são Tesseract-específico.
para alterar o seu modo de segmentação da página, altere o --psm argumento no seu texto de configuração personalizado para qualquer um dos códigos de modo acima mencionados.
Detectar apenas dígitos, usando de configuração :
Você pode reconhecer apenas dígitos alterando a configuração para o seguinte :
o que dá o seguinte resultado.

Como você pode ver, a saída não é o mesmo usando regex .
whitelisting / Blacklisting characters:
Say you only want to detect certain characters from the given image and ignore the rest. Você pode especificar a sua lista em branco de caracteres (Aqui, nós usamos todos os caracteres minúsculos de A A z apenas) usando a seguinte configuração.
e dá-nos esta saída :

declaração de Inidoneidade letras :
Se você tem certeza de que alguns caracteres ou expressões, definitivamente, não vai aparecer no seu texto (OCR irá retornar o texto errado no lugar de lista negra caracteres de outra forma), pode colocar os caracteres utilizando a seguinte config.
Saída :
Vários idiomas de texto :
Para especificar o idioma você precisa de seus resultados de OCR, use o -l LANG argumento na config onde LANG é o código de 3 letras para o idioma que você deseja usar.
Você pode trabalhar com várias línguas, alterando o parâmetro LANG tais como :
NB : A linguagem indicada em primeiro lugar para o parâmetro -l é a linguagem primária.

E você receberá a seguinte saída :

Infelizmente tesseract não tem um recurso para detectar o idioma do texto em uma imagem automaticamente. Uma solução alternativa é fornecida por outro módulo python chamado langdetect que pode ser instalado através do pip para mais informações verifique esta ligação.
Este módulo novamente, não detecta a linguagem de texto usando uma imagem, mas precisa de entrada de texto para detectar a linguagem de. A melhor maneira de fazer isso é usando primeiro tesseract para obter o texto OCR em quaisquer línguas que você possa sentir que estão lá, usando langdetect para encontrar quais línguas estão incluídas no texto OCR e, em seguida, executar OCR novamente com as línguas encontradas.digamos que temos um texto que pensávamos estar em inglês e português.
NB: o Tesseract tem um mau desempenho quando, numa imagem com várias línguas, as línguas especificadas na configuração estão erradas ou não são mencionadas de todo. Isto também pode induzir em erro o módulo langdetect.
limitações do Tesseract:
Tesseract OCR é bastante poderoso, mas tem algumas limitações.
- o RCP não é tão preciso como algumas soluções comerciais disponíveis .
- Não se dá bem com imagens afetadas por artefatos, incluindo oclusão parcial, perspectiva distorcida e fundo complexo.não é capaz de reconhecer a caligrafia.pode encontrar algaraviada e relatar isto como saída de OCR.
- Se um documento contiver línguas fora das indicadas nos argumentos do lang-l, os resultados podem ser fracos.nem sempre é bom analisar a ordem natural de leitura dos documentos. Por exemplo, ele pode não reconhecer que um documento contém duas colunas, e pode tentar juntar texto através de colunas.scans de baixa qualidade podem produzir OCR de baixa qualidade.
- não expõe informações sobre a família de tipos de letra a que pertence o texto.
conclusão:
Tesseract é perfeito para a digitalização de documentos limpos e vem com bastante alta precisão e variabilidade da fonte, uma vez que seu treinamento foi abrangente.
A última versão do Tesseract 4.0 Suporta OCR baseado em aprendizagem profunda que é significativamente mais precisa. O motor OCR em si é construído sobre uma rede de memória de longo prazo (LSTM), que é um tipo particular de Rede Neural recorrente (RNN).
Leave a Reply