LDA Tópico de Modelagem: Uma Explicação
Fundo
Tópico modelagem é o processo de identificação de temas em um conjunto de documentos. Isto pode ser útil para motores de busca, automação de serviço ao cliente, e qualquer outra instância onde conhecer os tópicos de documentos é importante. Existem vários métodos para fazer isso, mas aqui vou explicar um: Alocação latente de Dirichlet (LDA).
o algoritmo
LDA é uma forma de aprendizagem não supervisionada que vê documentos como sacos de palavras (ie ordem não importa). LDA funciona primeiro fazendo uma suposição chave: a forma como um documento foi gerado foi escolhendo um conjunto de tópicos e, em seguida, para cada tópico escolher um conjunto de palavras. Agora você pode estar perguntando ” ok então como ele encontra tópicos?”Bem, a resposta é simples: ela inverte este processo. Para isso, faz o seguinte para cada documento m:
- Assume que existem tópicos k em todos os documentos
- distribua estes tópicos k através do documento m (esta distribuição é conhecida como α e pode ser simétrica ou assimétrica, mais tarde) atribuindo a cada palavra um tópico.
- Para cada palavra w no documento m, assumir que o seu tópico está errado, mas todas as outras palavras são atribuídas o tópico correto.
- probabilisticamente atribuir a palavra w um tópico baseado em duas coisas:
– what topics are in document m
– how many times word w has been assigned a particular topic across all of the documents (this distribution is called β, more on this later) - Repeat this process a number of times for each document and you’re done!
Modelo
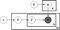
Acima é o que é conhecido como um prato diagrama de um modelo onde LDA:
α é o per-tópico do documento distribuições,
β é por tópico palavra de distribuição,
θ é o tópico de distribuição de documento, m,
φ é a palavra de distribuição para o tópico k,
z é o tema para a n-ésima palavra no documento m e
w é a palavra específica
Ajustes, o Modelo
Na placa de modelo de diagrama acima, você pode ver que w é acinzentado. Isto é porque é a única variável observável no sistema enquanto os outros são latentes. Por causa disso, para ajustar o modelo há algumas coisas que você pode mexer e Abaixo eu me concentrar em dois.
α é uma matriz onde cada linha é um documento e cada coluna representa um tópico. Um valor na linha I e coluna j representa a probabilidade de o documento I conter o tópico J. uma distribuição simétrica significaria que cada tópico é distribuído uniformemente ao longo do documento, enquanto uma distribuição assimétrica favorece certos tópicos sobre outros. Isso afeta o ponto de partida do modelo e pode ser usado quando você tem uma idéia aproximada de como os tópicos são distribuídos para melhorar os resultados.
β é uma matriz onde cada linha representa um tópico e cada coluna representa uma palavra. Um valor na linha I e coluna j representa a probabilidade de que o tópico I contenha palavra J. Normalmente cada palavra é distribuída uniformemente ao longo do tópico, de modo que nenhum tópico é tendencioso para certas palavras. Isso pode ser explorado, porém, a fim de influenciar certos tópicos para favorecer certas palavras. Por exemplo, se você sabe que tem um tópico sobre produtos da Apple pode ser útil para o viés de palavras como “iphone” e “ipad” para um dos tópicos, a fim de levar o modelo para encontrar determinado tópico.
Conclusion
this article is not meant to be a full-blown Lda tutorial, but rather to give an overview of how LDA models work and how to use them. Há muitas implementações lá fora, como o Gensim, que são fáceis de usar e muito eficazes. Um bom tutorial sobre o uso da biblioteca Gensim para modelagem LDA pode ser encontrado aqui.teve algum pensamento ou encontrou algo que me escapou? Avisa-me!Happy topic modeling!
Leave a Reply