Conoscenza della salute
NOTA:
Attualmente stiamo aggiornando questo capitolo e apprezziamo la tua pazienza mentre questo è in fase di completamento.
Bias negli studi epidemiologici
Mentre i risultati di uno studio epidemiologico possono riflettere il vero effetto di una o più esposizioni sullo sviluppo del risultato oggetto di indagine, si deve sempre considerare che i risultati possono in realtà essere dovuti a una spiegazione alternativa1.
Tali spiegazioni alternative possono essere dovute agli effetti del caso (errore casuale), del pregiudizio o della confusione che possono produrre risultati spuri, portandoci a concludere l’esistenza di una valida associazione statistica quando non esiste o in alternativa l’assenza di un’associazione quando si è veramente presenti1.
Gli studi osservazionali sono particolarmente sensibili agli effetti del caso, del pregiudizio e della confusione e questi fattori devono essere considerati sia nella fase di progettazione che di analisi di uno studio epidemiologico in modo che i loro effetti possano essere ridotti al minimo.
Bias
Bias può essere definito come qualsiasi errore sistematico in uno studio epidemiologico che si traduce in una stima errata del vero effetto di un’esposizione sul risultato di interesse.1
- Bias deriva da errori sistematici nella metodologia di ricerca.
- L’effetto del bias sarà una stima superiore o inferiore al valore reale, a seconda della direzione dell’errore sistematico.
- L’entità del bias è generalmente difficile da quantificare e esiste un margine limitato per l’aggiustamento della maggior parte delle forme di bias nella fase di analisi. Di conseguenza, un’attenta considerazione e controllo dei modi in cui il bias può essere introdotto durante la progettazione e la conduzione dello studio è essenziale per limitare gli effetti sulla validità dei risultati dello studio.
Tipi comuni di bias negli studi epidemiologici
Più di 50 tipi di bias sono stati identificati negli studi epidemiologici, ma per semplicità possono essere ampiamente raggruppati in due categorie: bias di informazione e bias di selezione.
1. Polarizzazione delle informazioni
La polarizzazione delle informazioni deriva da differenze sistematiche nel modo in cui i dati sull’esposizione o sui risultati sono ottenuti dai vari gruppi di studio.1 Ciò può significare che gli individui sono assegnati alla categoria di risultati errati, portando a una stima errata dell’associazione tra esposizione e risultato.
Gli errori di misurazione sono noti anche come errori di classificazione e l’entità dell’effetto del bias dipende dal tipo di errore di classificazione che si è verificato. Esistono due tipi di errata classificazione – differenziale e non differenziale-e questi sono trattati altrove (vedi “Fonti di variazione, sua misurazione e controllo”).
La polarizzazione dell’osservatore può essere il risultato della precedente conoscenza dello sperimentatore dell’ipotesi in esame o della conoscenza dello stato di esposizione o malattia di un individuo. Tali informazioni possono influenzare il modo in cui le informazioni vengono raccolte, misurate o interpretate dallo sperimentatore per ciascuno dei gruppi di studio.
Ad esempio, in uno studio di un nuovo farmaco per trattare l’ipertensione, se lo sperimentatore è a conoscenza di quali partecipanti al braccio di trattamento sono stati assegnati, ciò può influenzare la loro lettura delle misurazioni della pressione arteriosa. Gli osservatori possono sottovalutare la pressione sanguigna in coloro che sono stati trattati e sopravvalutarla in quelli del gruppo di controllo.
La polarizzazione dell’intervistatore si verifica quando un intervistatore pone domande importanti che possono influenzare sistematicamente le risposte fornite dagli intervistati.
Minimizzare la polarizzazione osservatore / intervistatore:
- Ove possibile, gli osservatori dovrebbero essere accecati all’esposizione e allo stato di malattia del singolo
- Osservatori ciechi all’ipotesi in esame.
- In uno studio randomizzato controllato ricercatori ciechi e partecipanti al trattamento e al gruppo di controllo (doppio accecamento).
- Sviluppo di un protocollo per la raccolta, la misurazione e l’interpretazione delle informazioni.
- Uso di questionari standardizzati o strumenti calibrati, come gli sfigmomanometri.
- Formazione degli intervistatori.
Recall (or response) bias – In uno studio caso-controllo i dati sull’esposizione vengono raccolti retrospettivamente. La qualità dei dati è quindi determinata in larga misura dalla capacità del paziente di richiamare con precisione le esposizioni passate. Recall bias può verificarsi quando le informazioni fornite sull’esposizione differiscono tra i casi e i controlli. Ad esempio, un individuo con il risultato in esame (caso) può riferire la propria esperienza di esposizione in modo diverso rispetto a un individuo senza il risultato (controllo) in esame.
Il bias di richiamo può comportare una sottostima o una sovrastima dell’associazione tra esposizione e risultato.
I metodi per ridurre al minimo il recall bias includono:
- Raccogliere dati sull’esposizione dal lavoro o dalle cartelle cliniche.
- Accecare i partecipanti all’ipotesi di studio.
Il bias di desiderabilità sociale si verifica quando i rispondenti ai sondaggi tendono a rispondere in un modo che ritengono sarà visto come favorevole da altri, ad esempio segnalando eccessivamente comportamenti positivi o sottoponendo a report indesiderati. Nel segnalare pregiudizi, gli individui possono sopprimere o rivelare informazioni selettivamente, per ragioni simili (ad esempio, intorno alla storia del fumo). Il bias di segnalazione può anche riferirsi alla segnalazione selettiva dei risultati da parte degli autori dello studio.
Il pregiudizio delle prestazioni si riferisce a quando il personale di studio o i partecipanti modificano il loro comportamento / risposte in cui sono consapevoli delle allocazioni di gruppo.
Il bias di rilevamento si verifica quando il modo in cui vengono raccolte le informazioni sui risultati differisce tra i gruppi. La polarizzazione dello strumento si riferisce al punto in cui uno strumento di misura calibrato in modo inadeguato sovra/sottovaluta sistematicamente la misurazione. L’accecamento dei valutatori dei risultati e l’uso di strumenti standardizzati e calibrati possono ridurre il rischio di ciò.
2. Bias di selezione
Il bias di selezione si verifica quando esiste una differenza sistematica tra:
- Coloro che partecipano allo studio e coloro che non lo fanno (che influenzano la generalizzabilità) o
- Quelli nel braccio di trattamento di uno studio e quelli nel gruppo di controllo (che influenzano la comparabilità tra i gruppi).
Cioè, esistono differenze nelle caratteristiche tra i gruppi di studio e tali caratteristiche sono correlate all’esposizione o al risultato in esame. Il bias di selezione può verificarsi per una serie di motivi.
Il bias di campionamento descrive lo scenario in cui alcuni individui all’interno di una popolazione target hanno maggiori probabilità di essere selezionati per l’inclusione rispetto ad altri. Ad esempio, se ai partecipanti viene chiesto di fare volontariato per uno studio, è probabile che coloro che fanno volontariato non siano rappresentativi della popolazione generale, minacciando la generalizzabilità dei risultati dello studio. I volontari tendono ad essere più attenti alla salute rispetto alla popolazione generale.
Il bias di allocazione si verifica in studi controllati quando c’è una differenza sistematica tra i partecipanti ai gruppi di studio (diversi dall’intervento studiato). Ciò può essere evitato mediante randomizzazione.
La perdita di follow-up è un problema particolare associato agli studi di coorte. Il bias può essere introdotto se gli individui persi al follow-up differiscono per quanto riguarda l’esposizione e l’esito di quelle persone che rimangono nello studio. La perdita differenziale di partecipanti da gruppi di uno studio di controllo randomizzato è nota come polarizzazione di attrito.
• Il bias di selezione negli studi caso-controllo
Il bias di selezione è un problema particolare inerente agli studi caso-controllo, dove dà luogo a non comparabilità tra casi e controlli. Negli studi caso-controllo, i controlli dovrebbero essere tratti dalla stessa popolazione dei casi, quindi sono rappresentativi della popolazione che ha prodotto i casi. I controlli sono utilizzati per fornire una stima del tasso di esposizione nella popolazione. Pertanto, il bias di selezione può verificarsi quando quegli individui selezionati come controlli non sono rappresentativi della popolazione che ha prodotto i casi.
Il potenziale di bias di selezione negli studi caso-controllo è un problema particolare quando i casi e i controlli sono reclutati esclusivamente da ospedali o cliniche. Tali controlli possono essere preferibili per motivi logistici. Tuttavia, i pazienti ospedalieri tendono ad avere caratteristiche diverse rispetto alla popolazione più ampia, ad esempio possono avere livelli più elevati di consumo di alcol o fumo di sigaretta. Il loro ricovero in ospedale può anche essere correlato al loro stato di esposizione, quindi le misurazioni dell’esposizione tra i controlli possono essere diverse da quelle della popolazione di riferimento. Ciò può comportare una stima parziale dell’associazione tra esposizione e malattia.
Ad esempio, in uno studio caso-controllo che esplora gli effetti del fumo sul cancro ai polmoni, la forza dell’associazione sarebbe sottostimata se i controlli fossero pazienti con altre condizioni nel reparto respiratorio, perché il ricovero in ospedale per altre malattie polmonari può anche essere correlato allo stato di fumo. Più sottilmente, l’effetto dell’alcol sulla malattia del fegato potrebbe potenzialmente essere sottovalutato se i controlli vengono presi da altri reparti: un consumo di alcol superiore alla media può comportare l’ammissione per una varietà di altre condizioni, come il trauma.
Poiché è probabile che il potenziale di bias di selezione sia meno problematico negli studi di caso-controllo basati sulla popolazione, i controlli di vicinato possono essere una scelta preferibile quando si utilizzano casi da un ambiente ospedaliero o clinico. In alternativa, il potenziale di bias di selezione può essere ridotto al minimo selezionando i controlli da più fonti. Ad esempio, l’uso di controlli ospedalieri e di vicinato.
• Bias di selezione negli studi di coorte
Il bias di selezione può essere meno problematico negli studi di coorte rispetto agli studi di caso-controllo, perché gli individui esposti e non esposti sono arruolati prima di sviluppare il risultato di interesse.
Tuttavia, il bias di selezione può essere introdotto quando la completezza del follow-up o l’accertamento dei casi differiscono tra le categorie di esposizione. Ad esempio, può essere più facile seguire gli individui esposti che lavorano tutti nella stessa fabbrica, rispetto ai controlli non esposti selezionati dalla comunità (perdita di pregiudizi di follow-up). Ciò può essere minimizzato garantendo un elevato livello di follow-up tra tutti i gruppi di studio.
L’effetto lavoratore sano è una potenziale forma di bias di selezione specifica per gli studi di coorte professionale. Ad esempio, uno studio di coorte professionale potrebbe cercare di confrontare i tassi di malattia tra individui di un particolare gruppo professionale con individui in una popolazione standard esterna. C’è il rischio di pregiudizi qui perché gli individui che sono impiegati generalmente devono essere sani per lavorare. Al contrario, la popolazione generale includerà anche coloro che sono inadatti al lavoro. Pertanto, i tassi di mortalità o morbilità nella coorte del gruppo di occupazione possono essere inferiori a quelli della popolazione nel suo complesso.
Al fine di ridurre al minimo il potenziale di questa forma di distorsione, un gruppo di confronto dovrebbe essere selezionato tra un gruppo di lavoratori con lavori diversi eseguiti in luoghi diversi all’interno di un’unica facilità1; ad esempio, un gruppo di impiegati non esposti. In alternativa, il gruppo di confronto può essere selezionato tra una popolazione esterna di persone occupate.
• Bias di selezione negli studi randomizzati
Gli studi randomizzati hanno teoricamente meno probabilità di essere influenzati dal bias di selezione, perché gli individui sono assegnati in modo casuale ai gruppi confrontati e si dovrebbero adottare misure per ridurre al minimo la capacità degli sperimentatori o dei partecipanti di influenzare questo processo di allocazione. Tuttavia, il rifiuto di partecipare a uno studio o i successivi ritiri possono influire sui risultati se i motivi sono correlati sia all’esposizione che all’esito.
Confusione
Confusione, interazione e modifica degli effetti
Confusione fornisce una spiegazione alternativa per un’associazione tra un’esposizione (X) e un risultato. Si verifica quando un’associazione osservata è infatti distorta perché l’esposizione è correlata anche con un altro fattore di rischio (Y). Questo fattore di rischio Y è anche associato al risultato, ma indipendentemente dall’esposizione in esame, X. Di conseguenza, l’associazione stimata non è la stessa del vero effetto dell’esposizione X sul risultato.
Una distribuzione diseguale del fattore di rischio aggiuntivo, Y, tra i gruppi di studio si tradurrà in confusione. L’associazione osservata può essere dovuta in tutto o in parte agli effetti delle differenze tra i gruppi di studio piuttosto che all’esposizione in esame.1
Un potenziale confondente è qualsiasi fattore che potrebbe avere un effetto sul rischio di malattia in studio. Ciò può includere fattori con un nesso causale diretto alla malattia, nonché fattori che sono misure proxy per altre cause sconosciute, come l’età e lo stato socioeconomico.2
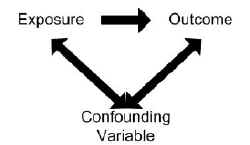
Affinché una variabile possa essere considerata un confonditore:
- La variabile deve essere associata indipendentemente al risultato (cioè essere un fattore di rischio).
- La variabile deve anche essere associata all’esposizione in studio nella popolazione di origine.
- La variabile non deve trovarsi sulla via causale tra esposizione e malattia.
Esempi di confusione
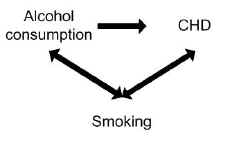
Uno studio ha rilevato che il consumo di alcol è associato al rischio di malattia coronarica (CHD). Tuttavia, il fumo può aver confuso l’associazione tra alcol e CHD.
Il fumo è un fattore di rischio a sé stante per la CHD, quindi è associato indipendentemente al risultato, e il fumo è anche associato al consumo di alcol perché i fumatori tendono a bere più dei non fumatori.
Il controllo del potenziale effetto confondente del fumo può infatti non mostrare alcuna associazione tra consumo di alcol e CHD.
Effetti di confondimento
I fattori confondenti, se non controllati, causano distorsioni nella stima dell’impatto dell’esposizione studiata. Gli effetti della confusione possono comportare:
- Un’associazione osservata quando non esiste un’associazione reale.
- Nessuna associazione osservata quando esiste una vera associazione.
- Una sottovalutazione dell’associazione (confusione negativa).
- Una sovrastima dell’associazione (confusione positiva).
Controllo per la confusione
La confusione può essere affrontata nella fase di progettazione dello studio o regolata nella fase di analisi fornendo dati pertinenti sufficienti sono stati raccolti. Un certo numero di metodi può essere applicato per controllare i potenziali fattori confondenti e lo scopo di tutti loro è quello di rendere i gruppi il più simile possibile rispetto al confonditore(s).
Controllo della confusione in fase di progettazione
I potenziali fattori di confusione possono essere identificati in fase di progettazione sulla base di studi precedenti o perché un legame tra il fattore e il risultato può essere considerato biologicamente plausibile. I metodi per limitare la confusione in fase di progettazione includono la randomizzazione, la restrizione e la corrispondenza.
• Randomizzazione
Questo è il metodo ideale per controllare la confusione perché tutte le potenziali variabili di confusione, sia note che sconosciute, dovrebbero essere equamente distribuite tra i gruppi di studio. Implica l’assegnazione casuale (ad esempio utilizzando una tabella di numeri casuali) di individui a gruppi di studio. Tuttavia, questo metodo può essere utilizzato solo in studi clinici sperimentali.
• Restrizione
La restrizione limita la partecipazione allo studio a individui che sono simili in relazione al confonditore. Ad esempio, se la partecipazione a uno studio è limitata ai soli non fumatori, qualsiasi potenziale effetto confondente del fumo sarà eliminato. Tuttavia, uno svantaggio della restrizione è che può essere difficile generalizzare i risultati dello studio alla popolazione più ampia se il gruppo di studio è omogeneo.1
• La corrispondenza
La corrispondenza implica la selezione dei controlli in modo che la distribuzione dei potenziali confondenti (ad esempio l’età o lo stato di fumo) sia il più simile possibile a quella dei casi. In pratica questo viene utilizzato solo negli studi di case-control, ma può essere fatto in due modi:
- Pair matching – selezionando per ogni caso uno o più controlli con caratteristiche simili (ad es. stessa età e abitudine al fumo)
- Frequenza di corrispondenza – garantire che un gruppo di casi hanno caratteristiche simili ai controlli
Rilevamento e controllo per la confusione in fase di analisi
La presenza o la grandezza di confondimento negli studi epidemiologici, è valutata osservando il grado di differenza tra la stima approssimativa (senza controllo di confondimento) e dall’adeguamento della stima dopo la contabilizzazione per il potenziale confounder(s). Se la stima è cambiata e c’è poca variazione tra i rapporti specifici dello strato (vedi sotto), allora c’è evidenza di confusione.
Non è opportuno utilizzare test statistici per valutare la presenza di confusione, ma i seguenti metodi possono essere utilizzati per minimizzare il suo effetto.
• Stratificazione
La stratificazione consente di esaminare l’associazione tra esposizione e risultato all’interno di diversi strati della variabile confondente, ad esempio per età o sesso. La forza dell’associazione viene inizialmente misurata separatamente all’interno di ogni strato della variabile confondente. Supponendo che i tassi specifici dello strato siano relativamente uniformi, possono quindi essere raggruppati per fornire una stima sommaria corretta o controllata per il potenziale confondente. Un esempio è il metodo Mantel-Haenszel. Uno svantaggio di questo metodo è che più il campione originale è stratificato, più piccolo sarà ogni strato e il potere di rilevare le associazioni è ridotto.
• Analisi multivariabile
Modellazione statistica (ad es. analisi di regressione multivariabile) viene utilizzato per controllare per più di un confondente allo stesso tempo, e consente l’interpretazione dell’effetto di ogni confondente individualmente. È il metodo più comunemente usato per trattare la confusione nella fase di analisi.
• Standardizzazione
La standardizzazione tiene conto dei fattori confondenti (generalmente età e sesso) utilizzando una popolazione di riferimento standard per annullare l’effetto delle differenze nella distribuzione dei fattori confondenti tra le popolazioni in studio. Vedere “Numeratori, denominatori e popolazioni a rischio” per maggiori dettagli.
Confusione residua
È possibile controllare i confonditori solo nella fase di analisi se i dati sui confonditori sono stati raccolti con precisione. La confusione residua si verifica quando tutti i confondenti non sono stati adeguatamente regolati per, o perché sono stati misurati in modo impreciso, o perché non sono stati misurati (ad esempio, confondenti sconosciuti). Un esempio potrebbe essere lo stato socioeconomico, perché influenza più risultati di salute ma è difficile da misurare con precisione.3
Interazione (modifica dell’effetto)
L’interazione si verifica quando la direzione o la grandezza di un’associazione tra due variabili varia in base al livello di una terza variabile (il modificatore dell’effetto). Ad esempio, l’aspirina può essere utilizzata per gestire i sintomi di malattie virali, come l’influenza. Tuttavia, mentre può essere efficace negli adulti, l’uso di aspirina nei bambini con malattie virali è associato a disfunzione epatica e danni cerebrali (sindrome di Reye).4 In questo caso, l’effetto dell’aspirina sulla gestione delle malattie virali viene modificato dall’età.
Se esiste un’interazione, il calcolo di una stima complessiva di un’associazione può essere fuorviante. A differenza della confusione, l’interazione è un fenomeno biologico e non dovrebbe essere regolato statisticamente per. Un metodo comune per trattare l’interazione è analizzare e presentare le associazioni per ogni livello della terza variabile. Nell’esempio sopra, le probabilità di sviluppare la sindrome di Reye dopo l’uso di aspirina nelle malattie virali sarebbero molto maggiori nei bambini rispetto agli adulti, e questo evidenzierebbe il ruolo dell’età come modificatore di effetto. L’interazione può essere confermata statisticamente, ad esempio utilizzando un test chi-quadrato per valutare l’eterogeneità nelle stime specifiche dello strato. Tuttavia, tali test sono noti per avere una bassa potenza per rilevare l’interazione5 e si raccomanda anche un’ispezione visiva delle stime specifiche dello strato.
- Hennekens CH, Buring JE. Epidemiologia in medicina, Lippincott Williams& Wilkins, 1987.
- Carneiro I, Howard N. Introduzione all’epidemiologia. Open University Press, 2011.
- http://www.edmundjessop.org.uk/fulltext.doc – Accesso 20/02/16
- McGovern MC. Sindrome di Reye e aspirina: per non dimenticare. BMJ 2001;322: 1591.
- Marshall SW. Potenza per i test di interazione: effetto di aumentare il tasso di errore di tipo 1. Prospettive epidemiologiche e innovazioni 2007; 4: 4.
Leave a Reply