Lda Emnemodellering: en forklaring
div >
baggrund
emnemodellering er processen med at identificere emner i et sæt dokumenter. Dette kan være nyttigt for søgemaskiner, automatisering af kundeservice og ethvert andet tilfælde, hvor det er vigtigt at kende emnerne i dokumenter. Der er flere metoder til at gøre dette, men her vil jeg forklare en: Latent Dirichlet tildeling (LDA).
algoritmen
LDA er en form for uovervåget læring, der ser dokumenter som poser med ord (dvs.orden betyder ikke noget). LDA fungerer ved først at antage en vigtig antagelse: den måde, et dokument blev genereret på, var ved at vælge et sæt emner og derefter for hvert emne vælge et sæt ord. Nu spørger du måske ” ok, så hvordan finder det emner?”Nå er svaret simpelt: det reverse ingeniører denne proces. For at gøre dette gør det følgende for hvert dokument m:
- Antag, at der er k-emner på tværs af alle dokumenterne
- distribuer disse k-emner på tværs af dokument m (denne fordeling er kendt som Kurt og kan være symmetrisk eller asymmetrisk, mere om dette senere) ved at tildele hvert ord et emne.
- for hvert ord i dokument m, antage, at dets emne er forkert, men hvert andet ord er tildelt det korrekte emne.
- probabilistisk tildele ord med et emne baseret på to ting:
– hvilke emner er der i dokument m
– Hvor mange gange er ord m blevet tildelt et bestemt emne på tværs af alle dokumenterne (denne distribution kaldes Kurt, mere om dette senere) - Gentag denne proces et antal gange for hvert dokument, og du er færdig!
modellen
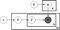
ovenfor er det, der er kendt som et pladediagram over en Lda-model, hvor:
kr er emnefordelingen pr.dokument,
kr er ordfordelingen pr. emne,
kr er emnefordelingen for dokument m,
kr er ordfordelingen for emne k,
Å er emnet for det n-th ord i dokument m, og
H er det specifikke ord
tilpasning af modellen
i plademodeldiagrammet ovenfor kan du se, at v er nedtonet. Dette skyldes, at det er den eneste observerbare variabel i systemet, mens de andre er latente. På grund af dette, for at tilpasse modellen er der et par ting, du kan rod med, og nedenfor fokuserer jeg på to.
List er en matrice, hvor hver række er et dokument, og hver kolonne repræsenterer et emne. En værdi i række i og kolonne j repræsenterer, hvor sandsynligt dokument i indeholder emne j. en symmetrisk fordeling ville betyde, at hvert emne er jævnt fordelt i hele dokumentet, mens en asymmetrisk fordeling favoriserer bestemte emner frem for andre. Dette påvirker udgangspunktet for modellen og kan bruges, når du har en grov ide om, hvordan emnerne distribueres for at forbedre resultaterne.
er en matrice, hvor hver række repræsenterer et emne, og hver kolonne repræsenterer et ord. En værdi i række i og kolonne j repræsenterer, hvor sandsynligt det emne Jeg indeholder ord j. normalt fordeles hvert ord jævnt i hele emnet, så intet emne er partisk mod bestemte ord. Dette kan udnyttes dog for at bias visse emner for at favorisere bestemte ord. For eksempel, hvis du ved, at du har et emne om Apple-produkter, kan det være nyttigt at bias ord som “iphone” og “ipad” for et af emnerne for at skubbe modellen mod at finde det pågældende emne.
konklusion
Denne artikel er ikke beregnet til at være en fuldblæst LDA-tutorial, men snarere at give et overblik over, hvordan LDA-modeller fungerer, og hvordan man bruger dem. Der er mange implementeringer derude, såsom Gensim, der er nemme at bruge og meget effektive. En god tutorial om brug af Gensim-biblioteket til Lda-modellering kan findes her.
har nogen tanker eller finde noget, jeg savnede? Sig til!
glad emne modellering!
Leave a Reply