OCR med Python, OpenCV og PyTesseract

optisk tegngenkendelse (OCR) er konvertering af billeder af skrevet, håndskrevet eller trykt tekst til maskinkodet tekst, hvad enten det er fra et scannet dokument, et foto af et dokument, et foto fra en scene (reklametavler i et landskabsfoto) eller fra en tekst, der er overlejret på et billede (undertekster på en TV-udsendelse).
OCR består generelt af delprocesser, der skal udføres så nøjagtigt som muligt.

- forbehandling
- tekstdetektering
- tekstgenkendelse
- efterbehandling
underprocesserne kan naturligvis variere afhængigt af brugssagen, men disse er generelt de trin, der er nødvendige for at udføre optisk tegngenkendelse.
Tesseract OCR :
Tesseract er en open source tekstgenkendelsesmotor (OCR), der er tilgængelig under Apache 2.0-licensen. Det kan bruges direkte, eller (for programmører) ved hjælp af en API til at udtrække udskrevet tekst fra billeder. Det understøtter en bred vifte af sprog. Tesseract har ikke en indbygget GUI, men der er flere tilgængelige fra 3.partysiden. Tesseract er kompatibel med mange programmeringssprog og rammer gennem indpakninger, der kan findes her. Det kan bruges med den eksisterende layoutanalyse til at genkende tekst i et stort dokument, eller det kan bruges sammen med en ekstern tekstdetektor til at genkende tekst fra et billede af en enkelt tekstlinje.
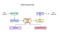
Tesseract 4.00 inkluderer et nyt neuralt netværksundersystem konfigureret som en tekstlinjegenkendelse. Det har sin oprindelse i OCRopus ‘ Python-baserede LSTM implementering, men er blevet redesignet til Tesseract i C++. Det neurale netværkssystem i Tesseract foruddaterer Tensorstrøm, men er kompatibelt med det, da der er et netværksbeskrivelsessprog kaldet variabelt Grafspecifikationssprog (VGSL), der også er tilgængeligt for Tensorstrøm.
for at genkende et billede, der indeholder et enkelt tegn, bruger vi typisk et indviklet neuralt netværk (CNN). Tekst af vilkårlig længde er en sekvens af tegn, og sådanne problemer løses ved hjælp af RNNs og LSTM er en populær form for RNN. Læs dette indlæg for at lære mere om LSTM.
Tesseract udviklet fra OCRopus model i Python, som var en gaffel af en LSMT i C++, kaldet CLSTM. CLSTM er en implementering af LSTM tilbagevendende neurale netværksmodel i C++.
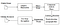
Tesseract var en indsats på kode rengøring og tilføje en ny LSTM model. Inputbilledet behandles i kasser (rektangel) linje for linje, der føres ind i LSTM-modellen og giver output. På billedet nedenfor kan vi visualisere, hvordan det fungerer.

installation af Tesseract
installation af Tesseract på vinduer er let med de forudkompilerede binære filer, der findes her. Glem ikke at redigere “sti” miljøvariabel og tilføje Tesseract sti. Det er installeret med få kommandoer.
Som standard forventer Tesseract en side med tekst, når den segmenterer et billede. Hvis du bare søger at OCR en lille region, kan du prøve en anden segmenteringstilstand ved hjælp af argumentet — psm. Der er 14 tilstande til rådighed, som kan findes her. Som standard automatiserer Tesseract fuldt ud sidesegmenteringen, men udfører ikke orientering og scriptdetektion. For at angive parameteren skal du skrive følgende:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
Der er også endnu et vigtigt argument, OCR-motortilstand (oem). Tesseract 4 har to OCR-motorer-Legacy Tesseract engine og LSTM engine. Der er fire driftsformer valgt ved hjælp af-oem-indstillingen.
0. Kun ældre motor.
1 . Kun neurale net LSTM-motor.
2 . Legacy + LSTM motorer.
3. Standard, baseret på hvad der er tilgængeligt.
OCR med Pytesseract og OpenCV:
Pytesseract er en indpakning til Tesseract-OCR motor. Det er også nyttigt som en stand-alone påkaldelse script til tesseract, da det kan læse alle billedtyper understøttes af puden og leptonica billedbehandling biblioteker, herunder jpeg, png, gif, bmp, tiff, og andre. Mere info om Python tilgang læs her.
forbehandling til Tesseract:
Vi skal sørge for, at billedet er korrekt forbehandlet. for at sikre en vis grad af nøjagtighed.
Dette inkluderer omskalering, binarisering, fjernelse af støj, deskvingning osv.
for at forbehandle billedet til OCR skal du bruge en af følgende python-funktioner eller følge OpenCV-dokumentationen.
Our input is this image :

Here’s what we get :

Getting boxes around text :
Vi kan bestemme afgrænsningsboksoplysningerne med PyTesseradt ved hjælp af følgende kode.
scriptet nedenfor giver dig oplysninger om afgrænsningsfeltet for hvert tegn, der registreres af tesseract under OCR.
Hvis du vil have bokse omkring ord i stedet for tegn, vil funktionenimage_to_data komme til nytte. Du kan bruge funktionen image_to_data med Outputtype angivet med pytesseract Output.
Vi bruger prøvekvitteringsbilledet nedenfor som input til at teste tesseract .

Her er koden:
udgangen er en ordbog med følgende nøgler:
ved hjælp af denne ordbog kan vi få hvert ord registreret, deres afgrænsningsboks information, teksten i dem og tillidsscore for hver.
Du kan plotte boksene ved at bruge koden nedenfor :
outputtet:

som vi kan se, er Tesseract ikke i stand til at registrere alle tekstbokse med sikkerhed, scanninger af dårlig kvalitet og små skrifttyper kan producere OCR-tekstdetektering af dårlig kvalitet. Der er heller ikke foretaget nogen forbehandling for at forbedre billedets kvalitet.
matchning af tekstskabeloner (registrer kun cifre ):
Tag eksemplet med at forsøge at finde, hvor en kun cifret streng er i et billede. Her vil vores skabelon være et regulært udtryksmønster, som vi matcher med vores OCR-resultater for at finde de passende afgrænsningsbokse. Vi vil bruge regex modulet og image_to_data funktionen til dette.

sidesegmenteringstilstande :
der er flere måder, hvorpå en tekstside kan analyseres. Tesseract api giver flere sidesegmenteringstilstande, hvis du kun vil køre OCR i en lille region eller i forskellige retninger osv.
Her er en liste over de understøttede sidesegmenteringstilstande af tesseract :
0. Kun orientering og scriptdetektion (OSD).
1 . Automatisk sidesegmentering med OSD.
2 . Automatisk sidesegmentering, men ingen OSD eller OCR.
3. Fuldautomatisk sidesegmentering, men ingen OSD. (Standard)
4. Antag en enkelt kolonne med tekst med variable størrelser.
5. Antag en enkelt ensartet blok af lodret justeret tekst.
6. Antag en enkelt ensartet tekstblok.
7. Behandl billedet som en enkelt tekstlinje.
8. Behandl billedet som et enkelt ord.
9. Behandl billedet som et enkelt ord i en cirkel.
10. Behandl billedet som et enkelt tegn.
11. Sparsom tekst. Find så meget tekst som muligt i ingen bestemt rækkefølge.
12. Sparsom tekst med OSD.
13. Rå linje. Behandl billedet som en enkelt tekstlinje, omgå hacks, der er Tesseract-specifikke.
for at ændre din sidesegmenteringstilstand skal du ændre argumentet--psm i din brugerdefinerede konfigurationsstreng til en af de ovennævnte tilstandskoder.
registrer kun cifre ved hjælp af konfiguration:
Du kan kun genkende cifre ved at ændre konfigurationen til følgende:
som giver følgende output.

som du kan se, er output ikke det samme ved hjælp af regeks .
hvidliste/sortliste tegn:
sig, at du kun vil registrere bestemte tegn fra det givne billede og ignorere resten. Du kan angive din hvidliste over tegn (her har vi kun brugt alle små bogstaver fra A til Å) ved hjælp af følgende config.
og det giver os denne output :

blacklisting letters :
Hvis du er sikker på, at nogle tegn eller udtryk bestemt ikke dukker op i din tekst (OCR returnerer forkert tekst i stedet for sortlistede tegn ellers), kan du sortliste disse tegn ved hjælp af følgende konfiguration.
udgang :
flere sprog tekst:
for at angive det sprog, du har brug for din OCR-udgang I, skal du bruge argumentet -l LANG i konfigurationen, hvor lang er koden på 3 bogstaver for hvilket sprog du vil bruge.
Du kan arbejde med flere sprog ved at ændre lang-parameteren som sådan:
NB : Det sprog, der først er angivet til parameteren -l, er det primære sprog.

og du får følgende output:
desværre har Tesseract ikke en funktion til automatisk at registrere sprog for teksten i et billede. En alternativ løsning leveres af et andet python-modul kaldet langdetect som kan installeres via pip for mere information, tjek dette link.
Dette modul registrerer igen ikke tekstsproget ved hjælp af et billede, men har brug for strenginput for at registrere sproget fra. Den bedste måde at gøre dette på er ved først at bruge tesseract til at få OCR-tekst på de sprog, du måske føler er derinde, ved at bruge langdetect for at finde ud af, hvilke sprog der er inkluderet i OCR-teksten og derefter køre OCR igen med de fundne sprog.
sig, at vi har en tekst, vi troede var på engelsk og portugisisk.
NB: Tesseract fungerer dårligt, når de sprog, der er angivet i konfigurationen, i et billede med flere sprog er forkerte eller slet ikke nævnes. Dette kan også vildlede langdetect-modulet ganske lidt.
Tesseract begrænsninger:
Tesseract OCR er ret kraftig, men har nogle begrænsninger.
- OCR er ikke så nøjagtig som nogle tilgængelige kommercielle løsninger .
- klarer sig ikke godt med billeder, der er påvirket af artefakter, herunder delvis okklusion, forvrænget perspektiv og kompleks baggrund.
- det er ikke i stand til at genkende håndskrift.
- det kan finde volapyk og rapportere dette som OCR output.
- hvis et dokument indeholder sprog uden for dem, der er angivet i argumenterne-L LANG, kan resultaterne være dårlige.
- det er ikke altid godt at analysere den naturlige læserækkefølge af dokumenter. For eksempel kan det ikke genkende, at et dokument indeholder to kolonner, og kan forsøge at forbinde tekst på tværs af kolonner.
- dårlig kvalitet scanninger kan producere dårlig kvalitet OCR.
- det afslører ikke oplysninger om, hvilken skrifttypefamilietekst der tilhører.
konklusion:
Tesseract er perfekt til scanning af rene dokumenter og leveres med temmelig høj nøjagtighed og skrifttypevariabilitet, da dens træning var omfattende.
den seneste udgave af Tesseract 4.0 understøtter dyb læring baseret OCR, der er betydeligt mere præcis. OCR-motoren selv er bygget på et langt Korttidshukommelsesnetværk (LSTM), som er en bestemt type tilbagevendende neuralt netværk (RNN).
Leave a Reply