sundhed viden
Bemærk:
Vi er i øjeblikket i færd med at opdatere dette kapitel, og vi sætter pris på din tålmodighed, mens dette er ved at blive afsluttet.
Bias i epidemiologiske undersøgelser
mens resultaterne af en epidemiologisk undersøgelse kan afspejle den virkelige virkning af en eksponering(er) på udviklingen af det undersøgte resultat, bør det altid overvejes, at resultaterne faktisk kan skyldes en alternativ forklaring1.
sådanne alternative forklaringer kan skyldes virkningerne af tilfældighed (tilfældig fejl), bias eller forvirring, som kan give falske resultater, hvilket får os til at konkludere eksistensen af en gyldig statistisk forening, når man ikke eksisterer, eller alternativt fraværet af en forening, når man virkelig er til stede1.
observationsstudier er særligt modtagelige for virkningerne af tilfældighed, bias og forvirring, og disse faktorer skal overvejes både i design-og analysefasen af en epidemiologisk undersøgelse, så deres virkninger kan minimeres.
Bias
Bias kan defineres som enhver systematisk fejl i en epidemiologisk undersøgelse, der resulterer i et forkert skøn over den sande effekt af en eksponering på resultatet af interesse.1
- Bias skyldes systematiske fejl i forskningsmetoden.
- effekten af bias vil være et skøn enten over eller under den sande værdi afhængigt af retningen af den systematiske fejl.
- størrelsen af bias er generelt vanskelig at kvantificere, og der findes begrænset omfang til justering af de fleste former for bias på analysestadiet. Som resultat, nøje overvejelse og kontrol af de måder, hvorpå bias kan indføres under design og gennemførelse af undersøgelsen er afgørende for at begrænse virkningerne på gyldigheden af undersøgelsesresultaterne.
almindelige typer bias i epidemiologiske undersøgelser
mere end 50 typer bias er blevet identificeret i epidemiologiske undersøgelser, men for enkelhed kan de bredt grupperes i to kategorier: informationsbias og selektionsbias.
1. Informationsbias
informationsbias skyldes systematiske forskelle i måden data om eksponering eller resultat opnås fra de forskellige studiegrupper.1 Dette kan betyde, at enkeltpersoner tildeles den forkerte resultatkategori, hvilket fører til et forkert skøn over sammenhængen mellem eksponering og resultat.
fejl i måling er også kendt som fejlklassifikationer, og størrelsen af effekten af bias afhænger af den type fejlklassificering, der er sket. Der er to typer fejlklassificering – differentiel og ikke-differentiel – og disse behandles andetsteds (se “kilder til variation, dens måling og kontrol”).observatørens bias kan være et resultat af efterforskerens forudgående kendskab til den hypotese, der undersøges, eller viden om en persons eksponering eller sygdomsstatus. Sådanne oplysninger kan påvirke den måde, hvorpå information indsamles, måles eller fortolkes af efterforskeren for hver af studiegrupperne.
for eksempel i et forsøg med en ny medicin til behandling af hypertension, hvis efterforskeren er opmærksom på, hvilken behandlingsarm deltagere blev tildelt, kan dette påvirke deres læsning af blodtryksmålinger. Observatører kan undervurdere blodtrykket hos dem, der er blevet behandlet, og overvurdere det hos dem i kontrolgruppen.bias opstår, når en intervju spørger ledende spørgsmål, der systematisk kan påvirke svarene fra intervju ‘ er.
minimering af observatørens bias:
- hvor det er muligt, bør observatører blindes for eksponering og sygdomsstatus for den enkelte
- blinde observatører til den hypotese, der undersøges.
- i et randomiseret kontrolleret forsøg blinde efterforskere og deltagere til behandlings-og kontrolgruppe (dobbeltblindende).
- udvikling af en protokol til indsamling, måling og fortolkning af information.
- brug af standardiserede spørgeskemaer eller kalibrerede instrumenter, såsom sphygmomanometre.
- uddannelse af praktikanter.
Recall (eller respons) bias – i en case-control undersøgelse data om eksponering indsamles retrospektivt. Kvaliteten af dataene bestemmes derfor i vid udstrækning af patientens evne til nøjagtigt at huske tidligere eksponeringer. Recall bias kan forekomme, når oplysningerne om eksponering adskiller sig mellem sagerne og kontrollerne. For eksempel kan en person med det undersøgte resultat (sag) rapportere deres eksponeringserfaring anderledes end en person uden det undersøgte resultat (kontrol).
Recall bias kan resultere i enten en undervurdering eller overvurdering af sammenhængen mellem eksponering og resultat.
metoder til at minimere tilbagekaldelse bias omfatter:
- indsamling af eksponeringsdata fra arbejde eller medicinske journaler.
- blændende deltagere til undersøgelseshypotesen.social ønskværdighed bias opstår, hvor respondenter til undersøgelser har tendens til at svare på en måde, de føler, vil blive betragtet som gunstige af andre, for eksempel ved overrapportering af positiv adfærd eller underrapportering af uønskede. Ved rapportering af bias kan enkeltpersoner selektivt undertrykke eller afsløre information af lignende årsager (for eksempel omkring rygehistorie). Rapporteringsforstyrrelse kan også henvise til selektiv resultatrapportering fra undersøgelsesforfattere.
Præstationsforstyrrelse refererer til, når studiepersonale eller deltagere ændrer deres adfærd / svar, hvor de er opmærksomme på gruppetildelinger.
Detektionsforstyrrelse opstår, hvor den måde, hvorpå resultatinformation indsamles, adskiller sig mellem grupper. Instrument bias refererer til, hvor et utilstrækkeligt kalibreret måleinstrument systematisk over/undervurderer måling. Blinding af resultatvurderere og brug af standardiserede, kalibrerede instrumenter kan reducere risikoen herfor.
2. Selektionsforstyrrelse
Selektionsforstyrrelse opstår, når der er en systematisk forskel mellem enten:
- dem, der deltager i undersøgelsen, og dem, der ikke gør det (påvirker generaliserbarhed) eller
- dem i behandlingsarmen i en undersøgelse og dem i kontrolgruppen (påvirker sammenlignelighed mellem grupper).
det vil sige, at der er forskelle i karakteristika mellem studiegrupper, og disse egenskaber er relateret til enten den eksponering eller det resultat, der undersøges. Valg bias kan forekomme af en række årsager.
Sampling bias beskriver scenariet, hvor nogle individer inden for en målpopulation er mere tilbøjelige til at blive valgt til inkludering end andre. For eksempel, hvis deltagerne bliver bedt om at melde sig frivilligt til en undersøgelse, er det sandsynligt, at de, der melder sig frivilligt, ikke vil være repræsentative for den generelle befolkning, hvilket truer generaliseringen af undersøgelsesresultaterne. Frivillige har tendens til at være mere sundhedsbevidste end den generelle befolkning.
Fordelingsforstyrrelse forekommer i kontrollerede forsøg, når der er en systematisk forskel mellem deltagere i studiegrupper (bortset fra den intervention, der undersøges). Dette kan undgås ved randomisering.
tab til opfølgning er et særligt problem forbundet med kohortestudier. Bias kan indføres, hvis de personer, der er tabt for opfølgning, adskiller sig med hensyn til eksponeringen og resultatet fra de personer, der forbliver i undersøgelsen. Det differentielle tab af deltagere fra grupper i et randomiseret kontrolforsøg er kendt som nedslidningsforstyrrelse.
• selection bias i case-control studies
Selection bias er et særligt problem i case-control studies, hvor det giver anledning til manglende sammenlignelighed mellem cases og controls. I case – Control-undersøgelser bør kontrol foretages fra samme population som sagerne, så de er repræsentative for den population, der producerede sagerne. Kontroller bruges til at give et skøn over eksponeringsgraden i befolkningen. Derfor kan selektionsforstyrrelse forekomme, når de personer, der er valgt som kontroller, ikke er repræsentative for den befolkning, der producerede sagerne.
potentialet for udvælgelsesforstyrrelse i case-control-undersøgelser er et særligt problem, når sager og kontroller udelukkende rekrutteres fra hospital eller klinikker. Sådanne kontroller kan være at foretrække af logistiske årsager. Imidlertid har hospitalspatienter en tendens til at have forskellige egenskaber i forhold til den bredere befolkning, for eksempel kan de have højere niveauer af alkoholforbrug eller cigaretrygning. Deres indlæggelse på hospitalet kan endda være relateret til deres eksponeringsstatus, så målinger af eksponeringen blandt kontroller kan være forskellige fra målingerne i referencepopulationen. Dette kan resultere i et forudindtaget skøn over sammenhængen mellem eksponering og sygdom.
for eksempel i en case-control-undersøgelse, der undersøgte virkningerne af rygning på lungekræft, ville foreningens styrke blive undervurderet, hvis kontrollerne var patienter med andre tilstande på åndedrætsafdelingen, fordi adgang til hospital for andre lungesygdomme også kan være relateret til rygestatus. Mere subtilt kan effekten af alkohol på leversygdom potentielt undervurderes, hvis der tages kontrol fra andre afdelinger: højere end gennemsnitligt alkoholforbrug kan resultere i optagelse til en række andre tilstande, såsom traumer.
da potentialet for selektionsforstyrrelse sandsynligvis vil være mindre af et problem i befolkningsbaserede case-control-undersøgelser, kan naboskabskontrol være et foretrukket valg, når man bruger sager fra et hospital eller en klinikindstilling. Alternativt kan potentialet for selektionsforstyrrelse minimeres ved at vælge kontrolelementer fra mere end en kilde. For eksempel brugen af både hospital og naboskabskontrol.
• Selektionsbias i kohortestudier
Selektionsbias kan være mindre problematisk i kohortestudier sammenlignet med case-control-studier, fordi eksponerede og ikke-eksponerede individer er tilmeldt, før de udvikler resultatet af interesse.
der kan dog indføres selektionsbias, når fuldstændigheden af opfølgningen eller konstateringen af sager er forskellig mellem eksponeringskategorierne. For eksempel kan det være lettere at følge op på udsatte personer, der alle arbejder på samme fabrik, end ueksponerede kontroller valgt fra samfundet (tab til opfølgningsbias). Dette kan minimeres ved at sikre, at der opretholdes et højt opfølgningsniveau blandt alle studiegrupper.
den sunde arbejdereffekt er en potentiel form for selektionsbias, der er specifik for erhvervsmæssige kohortestudier. For eksempel kan en erhvervsmæssig kohortestudie søge at sammenligne sygdomsrater blandt personer fra en bestemt erhvervsgruppe med personer i en ekstern standardpopulation. Der er risiko for bias her, fordi personer, der er ansat, generelt skal være sunde for at arbejde. I modsætning hertil vil den generelle befolkning også omfatte dem, der er uegnede til at arbejde. Derfor kan dødelighed eller sygelighed i besættelsesgruppekohorten være lavere end i befolkningen som helhed.
for at minimere potentialet for denne form for bias bør der vælges en sammenligningsgruppe blandt en gruppe arbejdstagere med forskellige job udført på forskellige steder inden for en enkelt facilitet1; for eksempel en gruppe ikke-eksponerede kontorarbejdere. Alternativt kan sammenligningsgruppen vælges blandt en ekstern population af beskæftigede personer.
• Selektionsbias i randomiserede forsøg
randomiserede forsøg er teoretisk mindre tilbøjelige til at blive påvirket af selektionsbias, fordi individer tilfældigt fordeles til de grupper, der sammenlignes, og der bør tages skridt til at minimere efterforskernes eller deltagernes evne til at påvirke denne tildelingsproces. Afslag på at deltage i en undersøgelse eller efterfølgende tilbagetrækninger kan dog påvirke resultaterne, hvis årsagerne er relateret til både eksponering og resultat.
Confounding
Confounding, interaktion og effekt modifikation
Confounding giver en alternativ forklaring på en sammenhæng mellem en eksponering og et resultat. Det sker, når en observeret forening faktisk er forvrænget, fordi eksponeringen også er korreleret med en anden risikofaktor (Y). Denne risikofaktor Y er også forbundet med resultatet, men uafhængigt af den undersøgte eksponering, H. Som følge heraf er den estimerede sammenhæng ikke den samme som eksponeringens sande virkning på resultatet.
en ulige fordeling af den ekstra risikofaktor, Y, mellem studiegrupperne vil resultere i forvirring. Den observerede sammenhæng kan helt eller delvis skyldes virkningerne af forskelle mellem studiegrupperne snarere end den eksponering, der undersøges.1
en potentiel konfunder er enhver faktor, der kan have en effekt på risikoen for sygdom, der undersøges. Dette kan omfatte faktorer med en direkte årsagssammenhæng til sygdommen såvel som faktorer, der er stedfortrædende foranstaltninger for andre ukendte årsager, såsom alder og socioøkonomisk status.2
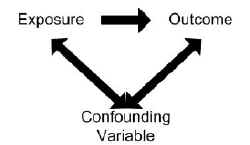
for at en variabel skal betragtes som en confounder:
- variablen skal være uafhængigt forbundet med resultatet (dvs.være en risikofaktor).
- variablen skal også være forbundet med den eksponering, der undersøges i kildepopulationen.
- variablen bør ikke ligge på årsagsvejen mellem eksponering og sygdom.
eksempler på confounding
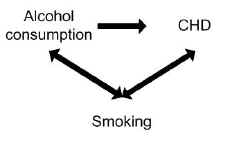
en undersøgelse viste, at alkoholforbrug var forbundet med risikoen for koronar hjertesygdom (CHD). Rygning kan dog have forvirret sammenhængen mellem alkohol og CHD.
rygning er en risikofaktor i sig selv for CHD, så er uafhængigt forbundet med resultatet, og rygning er også forbundet med alkoholforbrug, fordi rygere har tendens til at drikke mere end ikke-rygere.
kontrol af den potentielle forvirrende virkning af rygning kan faktisk ikke vise nogen sammenhæng mellem alkoholforbrug og CHD.
virkninger af confounding
Confoundingfaktorer, hvis de ikke kontrolleres for, forårsager bias i estimatet af virkningen af den eksponering, der undersøges. Virkningerne af forvirring kan resultere i:
- en observeret tilknytning, når der ikke findes nogen reel tilknytning.
- ingen observeret tilknytning, når der findes en ægte tilknytning.
- en undervurdering af foreningen (negativ confounding).
- en overvurdering af foreningen (positiv confounding).
kontrol for confounding
Confounding kan adresseres enten på undersøgelsesdesignstadiet eller justeret for på analysestadiet, der giver tilstrækkelige relevante data er indsamlet. En række metoder kan anvendes til at kontrollere for potentielle forvirrende faktorer, og formålet med dem alle er at gøre grupperne så ens som muligt med hensyn til konfunderen(erne).
kontrol for confounding i designfasen
potentielle confoundingfaktorer kan identificeres i designfasen baseret på tidligere undersøgelser, eller fordi en forbindelse mellem faktor og resultat kan betragtes som biologisk plausibel. Metoder til at begrænse forvirring i designfasen inkluderer randomisering, begrænsning og matchning.
• randomisering
Dette er den ideelle metode til at kontrollere for forvirring, fordi alle potentielle forvirrende variabler, både kendte og ukendte, skal fordeles ligeligt mellem studiegrupperne. Det involverer tilfældig tildeling (f.eks. ved hjælp af en tabel med tilfældige tal) af enkeltpersoner til studiegrupper. Denne metode kan dog kun anvendes i eksperimentelle kliniske forsøg.
• begrænsning
begrænsning begrænser deltagelse i undersøgelsen til personer, der er ens i forhold til konfunderen. For eksempel, hvis deltagelse i en undersøgelse kun er begrænset til ikke-rygere, vil enhver potentiel forvirrende virkning af rygning blive elimineret. En ulempe ved begrænsning er imidlertid, at det kan være vanskeligt at generalisere resultaterne af undersøgelsen til den bredere befolkning, hvis studiegruppen er homogen.1
• Matching
Matching involverer valg af kontroller, så fordelingen af potentielle confounders (f.eks. alder eller rygestatus) er så ens som muligt som blandt sagerne. I praksis bruges dette kun i case-control – undersøgelser, men det kan gøres på to måder:
- Partilpasning-valg for hvert tilfælde en eller flere kontroller med lignende egenskaber (f. eks. frekvens matching-at sikre, at sagerne som en gruppe har lignende egenskaber som kontrollerne
påvisning og kontrol for forvirring på analysestadiet
tilstedeværelsen eller størrelsen af forvirring i epidemiologiske undersøgelser evalueres ved at observere graden af uoverensstemmelse mellem det rå skøn (uden at kontrollere for forvirring) og det justerede skøn efter at have taget højde for den potentielle forvirring(e). Hvis estimatet er ændret, og der er ringe variation mellem de stratumspecifikke forhold (se nedenfor), så er der tegn på forvirring.
det er uhensigtsmæssigt at anvende statistiske tests til at vurdere forekomsten af forvirring, men følgende metoder kan anvendes til at minimere dens virkning.
• stratificering
stratificering gør det muligt at undersøge sammenhængen mellem eksponering og resultat inden for forskellige lag af den forvirrende variabel, for eksempel efter alder eller køn. Styrken af foreningen måles oprindeligt separat inden for hvert lag af den forvirrende variabel. Forudsat at de stratumspecifikke satser er relativt ensartede, kan de derefter samles for at give et sammenfattende skøn som justeret eller kontrolleret for den potentielle forvirrer. Et eksempel er Mantel-Haensel-metoden. En ulempe ved denne metode er, at jo mere den oprindelige prøve er stratificeret, jo mindre bliver hvert lag, og kraften til at detektere foreninger reduceres.
• multivariabel analyse
statistisk modellering (f. eks. multivariabel regressionsanalyse) bruges til at kontrollere for mere end en confounder på samme tid og muliggør fortolkning af effekten af hver confounder individuelt. Det er den mest almindeligt anvendte metode til at håndtere forvirring på analysestadiet.
• standardisering
standardisering tegner sig for confounders (generelt alder og køn) ved at bruge en standardreferencepopulation til at negere effekten af forskelle i fordelingen af confounding faktorer mellem studiepopulationer. Se “tællere, nævnere og risikopopulationer” for flere detaljer.
resterende confounding
det er kun muligt at kontrollere for confounders på analysetrinnet, hvis data om confounders blev nøjagtigt indsamlet. Resterende confounding opstår, når alle confounders ikke er blevet justeret tilstrækkeligt for, enten fordi de er blevet unøjagtigt målt, eller fordi de ikke er blevet målt (for eksempel ukendte confounders). Et eksempel ville være socioøkonomisk status, fordi det påvirker flere sundhedsresultater, men er vanskeligt at måle nøjagtigt.3
interaktion (effektmodifikation)
interaktion opstår, når retningen eller størrelsen af en sammenhæng mellem to variabler varierer afhængigt af niveauet for en tredje variabel (effektmodifikatoren). For eksempel kan aspirin bruges til at håndtere symptomerne på virussygdomme, som f.eks. Selvom det kan være effektivt hos voksne, er aspirinbrug til børn med virussygdomme imidlertid forbundet med leverdysfunktion og hjerneskade (Reyes syndrom).4 i dette tilfælde ændres effekten af aspirin på styring af virussygdomme efter alder.
hvor interaktion eksisterer, kan beregning af et samlet skøn over en forening være vildledende. I modsætning til confounding er interaktion et biologisk fænomen og bør ikke statistisk justeres for. En almindelig metode til at håndtere interaktion er at analysere og præsentere associationerne for hvert niveau i den tredje variabel. I eksemplet ovenfor ville oddsene for at udvikle Reyes syndrom efter aspirinbrug i virussygdomme være langt større hos børn sammenlignet med voksne, og dette ville fremhæve aldersrollen som en effektmodifikator. Interaktion kan bekræftes statistisk, for eksempel ved hjælp af en chi-kvadreret test til vurdering af heterogenitet i de stratumspecifikke estimater. Imidlertid er sådanne tests kendt for at have en lav effekt til påvisning af interaktion5, og en visuel inspektion af stratumspecifikke estimater anbefales også.
- Hennekens CH, Buring JE. Epidemiologi i medicin, Lippincott Vilhelms & Vilkins, 1987.
- Carneiro I. Introduktion til epidemiologi. Open University Press, 2011.
- http://www.edmundjessop.org.uk/fulltext.doc – adgang til 20/02/16
- McGovern MC. Reyes syndrom og aspirin: for at vi ikke glemmer. BMJ 2001; 322: 1591.
- Marshall SV. Strøm til test af interaktion: effekt af at hæve type 1-fejlfrekvensen. Epidemiologiske perspektiver og innovationer 2007; 4: 4.
Leave a Reply